

Google will neuronale Netze auf den Smartphones der Nutzer trainieren
Google hat eine Methode vorgestellt, um die Smartphones, auf denen die Daten anfallen, ins Training seiner neuronalen Netze einzuspannen. Für den Smartphone-Nutzer verspricht die Methode mehr Privatsphäre, da die Daten nicht mehr in die Cloud müssen.
(Bild: Google)
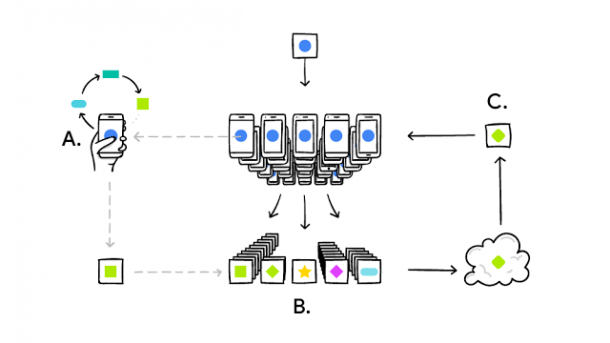
Der größte Teil der Daten, mit denen Google seine neuronalen Netze trainiert, fällt auf Smartphones an. Um aus dem Tippverhalten folgende Wörter zu empfehlen oder schlechte Fotos von guten Schnappschüssen zu unterscheiden, muss Google die Daten bisher in seinen Rechenzentren auswerten. Mit "Federated Learning" will Google bald auf die Datensammlung verzichten können und bestimmte neuronale Netze, wie das für die Wortvorhersage, direkt auf dem Smartphone der Nutzer trainieren. Laut Googles Research-Blog laufen erste Tests mit der Android-Tastatur-App schon. Um dabei sowohl Akku als auch Datenvolumen zu schonen, soll das Training nur stattfinden, wenn das Smartphone am Ladegerät hängt und im WLAN eingebucht ist.
Verteilter Durchschnitt
Die wenigen Daten, die auf einem einzelnen Smartphone anfallen, reichen nicht, um die neuronalen Netze zu trainieren. Um die Daten vieler Nutzer zu kombinieren, reicht es aber einzelne Schritte des Trainings auf den Mobilgeräten auszuführen und die Ergebnisse auf einem Server zu mitteln. Der Algorithmus ähnelt dem stochastischen Gradientenabstieg, der auch beim Training auf nur einem Rechner eingesetzt wird. Der Unterschied liegt darin, dass die Datensätze bei den Nutzern nicht repräsentativ verteilt sind. Google konnte allerdings zeigen, dass das Training trotzdem konvergiert, wenn alle Smartphones die Trainingsschritte mit dem gleichen Satz an Parametern beginnen.
Um beim verteilten Trainieren nicht zu viele Daten zwischen Smartphone und Server auszutauschen, hat Google mit verschiedenen Kompressionsmethoden experimentiert. Da private Internetanschlüsse besonders beim Upload limitiert sind, haben die Forscher zwei Ansätze zur Kompression der Updates an den Server ausprobiert: Beim ersten Ansatz übertrugen sie nur eine zufällige Auswahl an Parametern, was sich im Durchschnitt kaum negativ bemerkbar machte. Beim zweiten Ansatz quantisierten sie die Parameter auf minimal 1 Bit, womit ebenfalls noch sinnvolles Training möglich war.
Mehr Privatsphäre
Für den Datenschutz verspricht Federated Learning entscheidende Verbesserungen: Aus den aktualisierten Parametern, die das Smartphone an den Server schickt, dürfte es nämlich äußerst schwierig werden, die Trainingsdaten wieder zu extrahieren. Theoretisch ließe sich der eigene Datensatz mit Rauschen nach dem Prinzip der Differential Privacy weiter verschleiern.

(Bild: Bonawitz et al. )
Ein bösartiger Server könnte das aber trotzdem versuchen und die Updates einzelner Smartphones untersuchen. Für diesen Fall hat Google ein Kommunikationsprotokoll vorgestellt, bei dem der Server nur die Summe der Updates einer Mindestanzahl von Smartphones berechnen kann. Die Summe reicht für das Training des Modells aus. Das Protokoll erfordert zwar zusätzliche Kommunikation, der Overhead übersteigt aber das 1,73-Fache der sonst nötigen Kommunikation auch bei vielen Smartphones nicht. (pmk)
