

Facebook stellt verteilten Data Store für Logs vor
Um die Menge der bei Facebook produzierten Logs verfügbar und geordnet zu halten, hat das Unternehmen mit LogDevice ein für unterschiedliche Ansprüche optimierbares Projekt gestartet, das noch im Jahr 2017 Open Source werden soll.

- Julia Schmidt
Um den eigenen Ansprüchen an ein Logging-System gerecht zu werden, hat Facebook mit LogDevice einen verteilten Data Store für Logs entwickelt. Er soll sicherstellen, dass die im Unternehmen generierten Log-Einträge hochverfügbar und dauerhaft gespeichert werden und mit einer reproduzierbaren Nummerierung versehen sind. Das Grundprinzip des Tools hat Entwickler Mark Marchukov nun in einem Blogeintrag vorgestellt.
Da die zu loggenden Workloads des Unternehmens in ihren Ansprüchen hinsichtlich Latenz, Verfügbarkeit und der Behandlung von Leistungsspitzen variieren, soll sich LogDevice für alle Szenarien entsprechend einstellen lassen. Um eine gute Verfügbarkeit zum Schreiben anbieten zu können und wenig empfindlich für zeitweise einseitige Belastungen zu sein, hat das Team etwa die Sequenzialisierung der Aufzeichnungen von deren Speicherung getrennt und ihre Platzierung nicht deterministisch gestaltet. Für jedes Log in einem LogDevice-Cluster lässt das Tool ein Sequencer Object laufen, das monoton steigende Sequenznummern für jeden hinzugefügten Eintrag ausgibt.
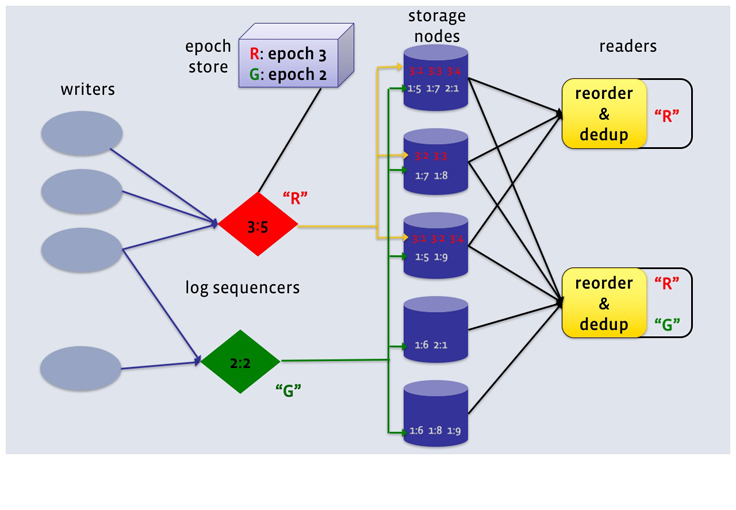
(Bild: Facebook )
Die Nummern bestehen aus Integer-Paaren, bei denen der erste Teil als Epoche bezeichnet wird und der zweite den Versatz innerhalb der Epoche angibt. Sollte ein Sequencer-Knoten beispielsweise abstürzen, muss LogDevice Ersatzobjekte für alle betroffenen Logs bereitstellen. Jeder neue Sequencer erhält dabei eine neue Epochennummer, damit sichergestellt ist, dass von ihm ausgegebene Sequenznummern immer größer als die vorangegangenen sind.
Sobald ein Eintrag mit Nummer versehen wurde, lassen sich Kopien auf allen Speicherknoten des Clusters hinterlegen, was die Langlebigkeit des Systems verbessern soll. Möchte ein Client Einblick in ein bestimmtes Log, kontaktiert er alle Knoten, die entsprechende Einträge speichern dürfen. Diese liefern via TCP passende Einträge, die die LogDevice Client Library anhand der enthaltenen Header-Informationen richtig ordnet und von Dopplungen befreit. Sollte es zu Datenverlusten gekommen sein, kann LogDevice das erkennen und Instanzen darüber informieren, die lesend auf die entsprechenden Bereiche zugreifen wollen.
Aus Kostengründen kommen bei Facebook häufig Festplatten zum Speichern der Logs zum Einsatz, weshalb die Entwickler zudem mit LogsDB einen lokalen Logspeicher vorgesehen haben. Dabei handelt es sich um eine Schicht auf Facebooks Key-Value-Datenspeicher RocksDB, genauer um eine zeitlich geordnete Sammlung von RocksDB-Instanzen, die ein Write-ahead Log gemeinsam nutzen. Das gesamte Projekt ist in C++ implementiert und soll wahrscheinlich noch 2017 für die Open-Source-Gemeinschaft geöffnet werden. Da allerdings nur wenige Unternehmen mit den bei Facebook auflaufenden Datenmengen konfrontiert sind, muss sich erst zeigen, ob sich das Tool an anderer Stelle bewährt und wie stark das Interesse daran tatsächlich ist. (jul)
