

C++ Core Guidelines: Mehr Fallen in der Concurrency
Concurrency bietet viele Wege an, sich in den eigenen Fuß zu schießen. Die Regeln dieses Artikels sollen helfen, diese Gefahren zu kennen und zu vermeiden.
- Rainer Grimm
Concurrency bietet viele Wege an, sich in den eigenen Fuß zu schießen. Die Regeln des heutigen Artikels sollen helfen, diese Gefahren zu kennen und zu vermeiden.
Das sind die drei Regel für den heutigen Artikel:
- CP.31: Pass small amounts of data between threads by value, rather than by reference or pointer
- CP.32: To share ownership between unrelated threads use shared_ptr
- CP.41: Minimize thread creation and destruction
Es gibt noch weitere Regeln, die ich aber ignoriere, da sie zum jetzigen Zeitpunkt keinen Inhalt besitzen.
CP.31: Pass small amounts of data between threads by value, rather than by reference or pointer
Diese Regel ist sehr naheliegend, daher kann ich mich kurz und bündig halten. Wenn du deine Daten per Copy an den Thread übergibst, besitzt dies zwei unmittelbare Vorteile:
- Die Daten werden nicht geteilt, und damit sind Data Races nicht möglich. Die Bedingungen an ein Data Race ist geteilter, veränderlicher Zustand. Hier sind die Details: "C++ Core Guidelines: Regeln zur Concurrency und zur Parallelität".
- Du musst dir keine Gedanken zur Gültigkeit deiner Variablen machen. Die Gültigkeit der Daten ist an die Gültigkeit des erzeugten Threads gebunden. Dies ist insbesondere wichtig, wenn du auf dem neuen Thread detach aufrufst: "C++ Core Guidelines: Sich um Kinder-Threads kümmern".
Natürlich habe ich noch nicht die entscheidende Frage dieser Regel beantwortet: Was heißt eine kleine Datenmenge angesichts eines Threads? Die C++ Core Guidelines geben hier keine eindeutige Aussage. In der Regel F.16 For “in” parameters, pass cheaply-copied types by value and others by reference to const to functions stellen sie die folgende Daumenregel 4 * sizeof(int) als Entscheidungsregel auf. Das heißt, wenn die Daten kleiner als 4 * sizeof(int) sind, sollten sie kopiert werden. Andernfalls, sollen sie mit einem Zeiger oder einer Referenz übergeben werden.
Um die sichere Antwort zu erhalten, führt letztlich kein Weg an einer Performanzmessung vorbei.
CP.32: To share ownership between unrelated threads use shared_ptr
Stelle dir vor, du besitzt Objekte, die du zwischen Threads teilen willst. Die entscheidende Frage ist nun: Wer ist der Besitzer des Objekts und damit für das Freigeben des Speichers verantwortlich? Nun stehen zwei Optionen zur Wahl. Wenn du den Speicher nicht freigibst, erhältst du ein Speicherleck. Wenn du den Speicher mehrmals freigibst, besitzt dein Programm undefiniertes Verhalten. Meist wird dies undefinierte Verhalten in einem Absturz zur Laufzeit des Programms enden:
// threadSharesOwnership.cpp
#include <iostream>
#include <thread>
using namespace std::literals::chrono_literals;
struct MyInt{
int val{2017};
~MyInt(){ // (4)
std::cout << "Good Bye" << std::endl;
}
};
void showNumber(MyInt* myInt){
std::cout << myInt->val << std::endl;
}
void threadCreator(){ // (1)
MyInt* tmpInt= new MyInt;
std::thread t1(showNumber, tmpInt); // (2)
std::thread t2(showNumber, tmpInt); // (3)
t1.detach();
t2.detach();
}
int main(){
std::cout << std::endl;
threadCreator();
std::this_thread::sleep_for(1s);
std::cout << std::endl;
}
Habe Geduld! Das Programm ist absichtlich sehr einfach gehalten. Ich habe den main-Thread nur für eine Sekunde schlafen gelegt, um sicher zu gehen, dass den Threads t1 und t2 genug Zeit für ihr Arbeitspaket bleibt. Dies ist natürlich keine angemessene Synchronisation, hilft mir aber, mich auf meinen zentralen Punkt zu fokussieren. Der zentrale Punkt ist: Wer ist verantwortlich für die Freigabe von tmpInt (1)? Der Thread t1 (2), der Thread t2 (3) oder die Funktion (1) (main-Thread) selbst? Da ich nicht vorhersagen kann, welcher Thread am längsten benötigt, habe ich mich für ein Speicherleck entschieden. Konsequenterweise wird der Destruktor von MyInt (4) nie aufgerufen:

Die ganzen Lebenszeitherausforderungen sind sehr angenehm zu lösen, wenn ich einen std::shared_ptr einsetze.
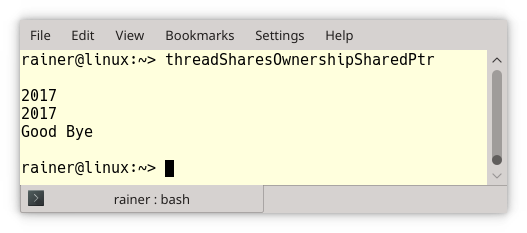
// threadSharesOwnershipSharedPtr.cpp
#include <iostream>
#include <memory>
#include <thread>
using namespace std::literals::chrono_literals;
struct MyInt{
int val{2017};
~MyInt(){
std::cout << "Good Bye" << std::endl;
}
};
void showNumber(std::shared_ptr<MyInt> myInt){ // (2)
std::cout << myInt->val << std::endl;
}
void threadCreator(){
auto sharedPtr = std::make_shared<MyInt>(); // (1)
std::thread t1(showNumber, sharedPtr);
std::thread t2(showNumber, sharedPtr);
t1.detach();
t2.detach();
}
int main(){
std::cout << std::endl;
threadCreator();
std::this_thread::sleep_for(1s);
std::cout << std::endl;
}
Zwei kleine Änderungen am Sourcecode waren notwendig. Zuerst wurde der Zeiger in (1) zum std::shared_ptr. Zusätzlich nimmt die Funktion showNumber einen std::shared_ptr statt eines nackten Zeigers an.
CP.41: Minimize thread creation and destruction
Wie teuer ist ein Thread? Ziemlich teuer! Dies ist der Grund für diese Regel. Zuerst will ich über die Größe eines Threads und dann über die Kosten seiner Erzeugung schreiben.
Größe
Ein std::thread ist ein dünner Wrapper um den zugrunde liegenden, nativen Thread. Das heißt, dass ich mich für die Größe eines Windows-Thread und eines POSIX-Thread interessiere.
- Windows-System: Die Antwort gibt der Artikel "Thread Stack Size": 1 MByte.
- POSIX- System: In diesem Fall hilft die man-page zu der Funktion pthread_create: 2 MByte. Dies ist die Größe für i386- und x86_64-Architekturen. Falls du die Größen zu weiteren Architekturen wissen willst, die den POSIX-Standard umsetzen, sind hier die Details.

Erzeugung
Ich habe keine Zahlen für die Kosten zur Erzeugung eines Threads gefunden. Um aber ein Gefühl dafür zu bekommen, führe ich einen einfachen Performanztest auf Linux und Windows durch.
Für meinen Performanztest kommt der GCC 6.2.1 auf einem Desktop-PC und die cl.exe auf einem Windows-Laptop zum Einsatz. Die cl.exe ist Bestandteil von Microsoft Visual Studio 2017. Ich übersetze das Programm mit maximaler Optimierung. Das bedeutet auf Linux das Flag O3 und auf Windows das Flag Ox.
Hier ist das kleine Testprogramm:
// threadCreationPerformance.cpp
#include <chrono>
#include <iostream>
#include <thread>
static const long long numThreads= 1'000'000;
int main(){
auto start = std::chrono::system_clock::now();
for (volatile int i = 0; i < numThreads; ++i) std::thread([]{}).detach();
std::chrono::duration<double> dur= std::chrono::system_clock::now() - start;
std::cout << "time: " << dur.count() << " seconds" << std::endl;
}
Das Programm erzeugt eine Millionen Threads, die eine leere Lambda-Funktion (1) ausführen. Dies sind die Zahlen für Linux und Windows.
Linux:

Das heißt, die Erzeugung eines Thread kostet ungefähr 14,5 sec/1.000.000 = 14,5 Mikrosekunden auf Linux.
Windows:

Die Erzeugung eines Threads schlägt mit 44 sec/1.000.000 = 44 Mikrosekunden auf Windows zu Buche.
Somit lassen sich 69 Tausend Threads auf Linux und 23 Tausend Threads auf Windows in einer Sekunden erzeugen.
Wie geht's weiter?
Was ist der einfachste Weg, sich in den Fuß zu schießen? Verwende eine Bedingungsvariable! Du glaubst mir nicht? Warte auf den nächsten Artikel! ()
