

Concurrency und lock-freies Programmieren
Dieser Artikel schließt die Regeln zur Concurrency ab und knüpft direkt mit den Regeln zur lock-freien Programmierung an.
- Rainer Grimm
Heute schließe ich die Regeln zur Concurrency ab und knüpfe direkt mit den Regeln zur lock-freien Programmierung an. Ja, du hast richtig gelesen: Lock-freie Programmierung.
Bevor ich zur lock-freien Programmierung schreibe, möchte ich noch die drei verbleibenden Regeln zur Concurrency vorstellen:
- CP.43: Minimize time spent in a critical section
- CP.44: Remember to name your lock_guards and unique_locks
- CP.50: Define a mutex together with the data it guards. Use synchronized_value<T> where possible
Da die Regeln ziemlich offensichtlich sind, kann ich mich kurz halten.
CP.43: Minimize time spent in a critical section
Je kürzer du eine Mutex lockst, desto länger kann ein anderer Thread ausgeführt werden. Dies gilt zum Beispiel für die Benachrichtigung einer Bedingungsvariable. Das ganze Beispielprogramm gibt es in dem Artikel C++ Core Guidelines: Sei dir der Fallen von Bedingungsvariablen bewusst.
void setDataReady(){
std::lock_guard<std::mutex> lck(mutex_);
dataReady = true; // (1)
std::cout << "Data prepared" << std::endl;
condVar.notify_one();
}
Der Mutex mutex_ wird am Beginn der Funktion gelockt und an ihrem Ende wieder freigegeben. Dies ist nicht notwendig. Lediglich der Ausdruck dataReady = true (1) ist zu schützen.
Erstens gilt, dass std::cout thread-sicher ist. Der C++11-Standard sichert zu, dass jeder Buchstabe atomar geschrieben wird und dass jeder Buchstabe in der richtigen Reihenfolge ausgegeben wird. Zweitens gilt, dass die Benachrichtigung condVar.notify_one thread-sicher ist.
Hier ist verbesserte Version der Funktion setDataReady:
void setDataReady(){
{ // Don't remove because of the lifetime of the mutex (1)
std::lock_guard<std::mutex> lck(mutex_);
dataReady = true;
} (2)
std::cout << "Data prepared" << std::endl;
condVar.notify_one();
}
Wenn ich diese Regel in meiner Schulungen zur Concurrency vorstelle, gibt es häufig eine Frage: Ist der künstliche Bereich zu dokumentieren, der die Lebenszeit des Locks std::lock_guard und damit des Mutex einschränkt (Zeilen (1) und (2))? Die meisten Teilnehmer und ich plädieren für ja. Falls nicht, ist die Gefahr sehr groß, dass eine Überarbeitung des Codes dazu führt, dass die zwei zusätzlichen geschweiften Klammern als überflüssig angesehen und entfernt werden. Am Ende führt dies zur Version 1.
CP.44: Remember to name your lock_guards and unique_locks
Zugegeben, beim ersten Lesen dieser Regel war ich ein wenig verwundert. Hier ist das kleine Sourcecode Beispiel aus den Guidelines:
unique_lock<mutex>(m1);
lock_guard<mutex> {m2};
lock(m1, m2);
Der unique_lock und der lock_guard sind lediglich temporäre Variablen, die in einem Schritt erzeugt und wieder destruiert werden. unique_lock und lock_guard locken ihre Mutexe in ihrem Konstruktor und geben diese wieder in ihrem Destruktor frei. Dieses Pattern besitzt den Namen RAII. Hier gibt es die Details dazu: Garbage Collection - No thanks.
Mein kleines Beispiel stellt das prinzipielle Verhalten eines einfachen std::lock_guard vor. Sein großer Bruder std::unique_lock bietet ein deutlich mächtigeres Interface an.
// myGuard.cpp
#include <mutex>
#include <iostream>
template <typename T>
class MyGuard{
T& myMutex;
public:
MyGuard(T& m):myMutex(m){
myMutex.lock();
std::cout << "lock" << std::endl;
}
~MyGuard(){
myMutex.unlock();
std::cout << "unlock" << std::endl;
}
};
int main(){
std::cout << std::endl;
std::mutex m;
MyGuard<std::mutex> {m}; // (1)
std::cout << "CRITICAL SECTION" << std::endl; // (2)
std::cout << std::endl;
}
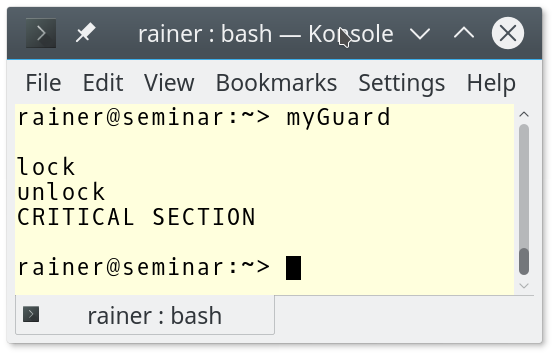
MyGuard ruft lock und unlock in seinem Konstruktor und Destruktor auf. Aufgrund der temporären Variablen, finden beide Aufrufe genau in der Zeile (1) statt. Das bedeutet insbesondere, dass der Destruktor in Zeile (1) aufgerufen und nicht – wie vermutet – in der Zeile (3). Konsequenterweise wird der kritische Bereich in Zeile (2) ohne Synchronisation ausgeführt.
Die Ausführung des Programms bringt es ans Licht: "output" wird vor "CRITICAL SECTION" ausgegeben.
CP.50: Define a mutex together with the data it guards. Use synchronized_value<T> where possible
Die zentrale Idee dieser Regel ist es, dass du den Mutex direkt in der Datenstruktur anlegst, die es zu schützen gilt. Wenn standardisiertes C++ zum Einsatz kommt, bietet sich die folgende Umsetzung an:
struct Record {
std::mutex m; // take this mutex before accessing other members
// ...
};
Mit zukünftigen C++-Standard, kann man diese Regel deutlich eleganter implementieren. Die nächste Implementierung basiert auf synchronized_value<T>, das wohl mit C++20/23 standardisiert werden wird.
class MyClass {
struct DataRecord {
// ...
};
synchronized_value<DataRecord> data; // Protect the data with a mutex
};
Anthony Williams stellt im Proposal N4033 die Grundidee von synchronized_value<T> genauer vor: "The basic idea is that synchronized_value<T> stores a value of type T and a mutex. It then exposes a pointer interface, such that derefencing the pointer yields a special wrapper type that holds a lock on the mutex, and that can be implicitly converted to T for reading, and which forwards any values assigned to the assignment operator of the underlying T for writing."
Dies bedeutet im Wesentlichen, dass die Operation auf s in dem folgenden Codeschnipsel thread-sicher sind.
synchronized_value<std::string> s;
std::string readValue()
{
return *s;
}
void setValue(std::string const& newVal)
{
*s=newVal;
}
void appendToValue(std::string const& extra)
{
s->append(extra);
}
Nun, wie bereits angekündigt, zu etwas ganz anderem.
Lock-freie Programmierung
Beginnen möchte ich mit einer Meta-Regel.
Programmiere nicht lock-frei
Klar, du glaubst mir nicht, aber basierend auf meiner Erfahrung aus vielen Schulungen und Workshops zur Concurrency, ist dies meine erste Regel. Ehrlich gesagt, bin ich damit im Tenor der meistgeschätzten und bekannten C++ Experten weltweit. Gerne zitiere ich ein paar Aussagen und Zitate ihrer Vorträge:
- Herb Sutter: "Lock-freie Programmierung ist wie das Spielen mit Messern."
- Anthony Williams: "Lock-free programming is about how to shoot yourself in the foot."
- Tony Van Eerd: "Lock-free coding is the last thing you want to do."
- Fedor Pikus: "Writing correct lock-free programs is even harder."
- Harald Böhm: "The rules are not obvious."
Das Bild bringt die Aussagen und Zitate nochmals auf den Punkt.

Du glaubst mir immer noch nicht? C++11 definierte die Speicherordnung std::memory_order_consume. Sieben Jahre später sind dies die offizielen Worte dazu: "The specification of release-consume ordering is being revised, and the use of memory_order_consume is temporarily discouraged." (memory_order)
Im Falle, du weißt, was du tust, denke über das ABA-Problem in der Regel CP.100 nach.
CP.100: Don’t use lock-free programming unless you absolutely have to
Das folgend kleine Codebeispiel der C++ Guidelines besitzt einen Bug.
extern atomic<Link*> head; // the shared head of a linked list
Link* nh = new Link(data, nullptr); // make a link ready for insertion
Link* h = head.load(); // read the shared head of the list
do {
if (h->data <= data) break; // if so, insert elsewhere
nh->next = h; // next element is the previous head
} while (!head.compare_exchange_weak(h, nh)); // write nh to head or to h
Finde den Bug und schreibe eine E-Mail oder einen Kommentar. Ich werde auf die beste Problemanalyse in meinen nächsten Artikel eingehen und, falls du willst, deinen Namen nennen.
Wie geht's weiter?
Klar, ich werde erst das ABA-Problem im nächsten Artikel auflösen. Danach geht meine Geschichte zur lock-freien Programmierung weiter. ()
