

Lautlos telefonieren
Öffentlich telefonieren, ohne andere zu nerven oder intime Details auszuplaudern – daran arbeiten Forscher in Bremen und Grenoble.
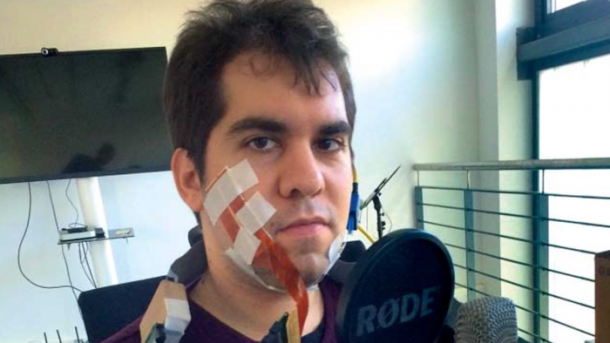
(Bild: (C) CSL / Uni Bremen)
- Susanne Donner
"Und dann ist er ausgerastet. Unglaublich." Wer solche Gesprächsfetzen eines Telefonats aufschnappt, ist sogleich hellwach und hört unwillkürlich mit, auch wenn der Anstand das Weghören fordert. Als Anrufer ist es einem mitunter peinlich, wenn das Umfeld ungefragt an den ganz privaten Dingen teilhat. Technisch gäbe es für dieses Problem eine perfekte Lösung: die Lautlostelefonie.
Ein Gerät erfasst die Muskelbewegungen der Kiefer und schließt daraus auf die geäußerten Worte. In der Öffentlichkeit dürfte die Mundgymnastik zweifellos für irritierte Blicke sorgen. Ob das aber die Technik ausbremst? Erstens haben wir uns auch an Telefonierer mit Freisprechanlage gewöhnt. Kaum einer hält die Nutzer noch für verrückt ins Selbstgespräch vertieft. Und zweitens wären die Gespräche vertraulicher, die Verständigung in lauter Umgebung fiele leichter.
Um das lautlose Sprechen zu erfassen, kleben Wissenschaftler der Universität Bremen ihren Probanden je vierzig Elektroden auf die Wange und unter das Kinn. Die Sensoren leiten die subtilen Änderungen der elektrischen Spannung ab, die aufgrund der Muskelbewegungen beim Sprechen auftreten (Elektromyografie). "Die Umwandlung von lautlos gesagten Sätzen in Text funktioniert schon sehr gut", sagt der Elektroingenieur Lorenz Diener vom Cognitive Systems Lab in Bremen. Diesen Text kann eine Sprachsynthesesoftware dann vorlesen. Doch der Umweg über die Textversion verursacht eine Verzögerung zwischen Spracheingabe und -ausgabe, die am Telefon lange Gesprächspausen nach sich ziehen würde. "Deshalb arbeiten wir jetzt an der direkten, verzögerungsfreien Übersetzung in Sprache", sagt Diener. Dazu wollen die Forscher motorische Impulse unmittelbar als Laute ausgegeben.
"Mit dem menschlichen Auge kann man in dem Muster an elektromyografischen Signalen nichts erkennen. Mit dem Computer ausgewertet, kann man aber ein A von einem O oder einem E treffsicher unterscheiden." Auch verschiedene Wörter kann das Computerprogramm der Bremer Forscher erfassen und in Echtzeit laut aussprechen. "Tür auf" könne das System beispielsweise von "Tür zu" unterscheiden und wiedergeben.
An längeren Wortfolgen und einem größeren Wortschatz scheitert das System allerdings noch. Diener arbeitet daher an Algorithmen, mit denen das System "an der Aussprache des Nutzers lernt und immer besser wird".
Das allein aber könnte nicht reichen. Deshalb will Diener ein weiteres Element des menschlichen Sprechapparates hinzufügen: die Zunge. Er reist dafür regelmäßig nach Grenoble. Am dortigen Forschungszentrum CNRS vermessen Forscher den Mundraum mit Ultraschall, um die Bewegungen der Zunge beim Sprechen zu erfassen. Die Methode gleicht jener für Untersuchungen während der Schwangerschaft, nur sitzt das Gerät nicht auf dem Bauch, sondern unter dem Kinn. Ein "H" und ein "A" lassen sich mit dieser Methode jedoch nicht unterscheiden, weil die Zunge sich bei diesen Lauten in identischer Weise nach unten in Richtung Gaumen bewegt.
Deshalb filmen die Forscher zusätzlich mit einer Kamera die Lippenbewegungen. Erst beide Bewegungsmuster zusammen verraten, was der Nutzer erzählt. "85 Prozent der Laute eines stumm gesagten Satzes – ob Englisch oder Französisch – gibt unser System momentan richtig wieder", sagt Sprachingenieur Thomas Hueber. Hueber und Diener planen nun, ihre Techniken zu verschmelzen. Sie rechnen damit, dass sich dadurch die Übersetzung vom Lautlosen ins Gesprochene erheblich verbessert. "Wir haben in unserem Labor sehr gute Informationen über die Muskelbewegungen des Gesichtes und der Lippen", sagt Diener. "Die Kollegen in Grenoble haben Daten über die Zunge. Das ergänzt sich ausgezeichnet."
Noch klingt die synthetische Stimme allerdings ein bisschen wie Darth Vader, robotisch und im lauten Flüsterton, ohne Rhythmus und Intonation – und zwar bei beiden Ansätzen. "Die Betonung entsteht erst, wenn die Stimmbänder vibrieren", erklärt Hueber. "Wenn wir lautlos sprechen, fehlt das." Das Manko ist mehr als reine Geschmackssache. Wichtige Informationen können verloren gehen, weil die Art der Betonung die Bedeutung eines Satzes komplett verändern kann. "Ich kann einen Baum umfahren, sodass er umfällt, oder ich kann einen Baum umfahren, sodass ich eine Kurve um ihn herum mache", erklärt Diener. Schwierigkeiten haben die Programme zudem bei ähnlich lautenden Wörtern wie "Pier" und "Bier".
Um diese Probleme wenigstens teilweise zu lösen, füttern die Forscher ihre Programme mit Regeln. Sie geben dem Übersetzungsprogramm beispielsweise vor, dass auf "My name" höchstwahrscheinlich "is" und nicht "it" folgt. Oder sie bringen ihm bei, dass man "Pudding isst" und nicht "Pudding ist". So können die Lautlosübersetzer künftig aus dem Kontext des Gesagten auf das richtige Wort schließen, ähnlich wie dies kommerzielle Sprachsoftware heute bereits praktiziert.
Vermutlich muss die Methode aber gar nicht perfekt funktionieren, um erste Anwendungen zu ermöglichen. Sie dürften in der Medizintechnik liegen, um jenen Patienten ein künstliches Sprachrohr zu geben, die aufgrund eines Kopf-Hals-Tumors keine Stimme mehr haben. Noch müssten sie dafür allerdings recht grobe Technik tragen: Beim Grenobler Team sitzen Ultraschallgerät und Kamera in einem martialischen Helm, der an eine Ritterrüstung erinnert.
In Bremen kleben die Sensoren im Gesicht. Hueber und Diener hoffen jedoch, dass sich die nötige Technik in ein Smartphone integrieren lässt. Die Erfassung der Lippen- und Zungenbewegung könnte etwa über die Freisprecheinrichtung erfolgen, die Elektrosensoren für die Muskeln würden auf dem Display sitzen, das der Nutzer beim Telefonieren ohnehin an seine Wange hält. "Wir haben uns noch nicht mit dem Design befasst", erklärt Hueber. "Im Fokus steht die Machbarkeit der lautlosen Kommunikation."
(bsc)
