

Natural Language Processing: Google veröffentlicht Modell für Pre-Training
Mit den quelloffenen "Bidirectional Encoder Representations from Transformers" (BERT) soll das Training neuer Modelle einfacher und schneller laufen.

Der Mangel an umfassenden, von Menschen gelabelten Trainingsdaten erweist sich nach Ansicht von Google als eines der größten Hindernisse beim Erstellen neuer Modelle für Natural Language Processing (NLP). Die Technik der "Bidirectional Encoder Representations from Transformers" (BERT) soll Data Scientists und NLP-Anwendern die Arbeit künftig leichter machen – insbesondere im Hinblick auf Trainingsdaten mit Millionen oder gar Milliarden annotierter Einträge, von denen vor allem auf Deep Learning basierende NLP-Modelle profitieren. Google stellt BERT ab sofort als Open Source frei zur Verfügung.
Mit BERT lassen sich die umfangreichen nicht annotierten Textquellen aus dem Internet für das sogenannte Pre-Training universell einsetzbarer Sprachrepräsentationsmodelle nutzen und die Modelle dann schrittweise verfeinern. Die aktuelle Version von BERT verbindet Sourcecode, der auf TensorFlow aufsetzt, mit einer Reihe kontextbezogener Repräsentationsmodelle für gängige NLP-Aufgaben wie Frage/Antwort oder Stimmungsanalyse.
Laut Google lassen sich auf dieser Basis neue Modelle binnen weniger Stunden erstellen und verfeinern. BERT setzt auf kontextbezogenen Modellen wie Semi-supervised Sequence Learning, Generative Pre-Training, ELMo und ULMFit auf, verfolgt aber einen grundlegend ("tief") bidirektionalen, unüberwachten Lernansatz. Gegenüber unidirektionalen oder gar kontextfreien Ansätzen (wie word2vec und GloVe) bietet BERT dadurch den Vorteil einer noch genaueren Spezifizierung einzelner Wörter, die sich aus dem gesamten Kontext ableiten lässt.
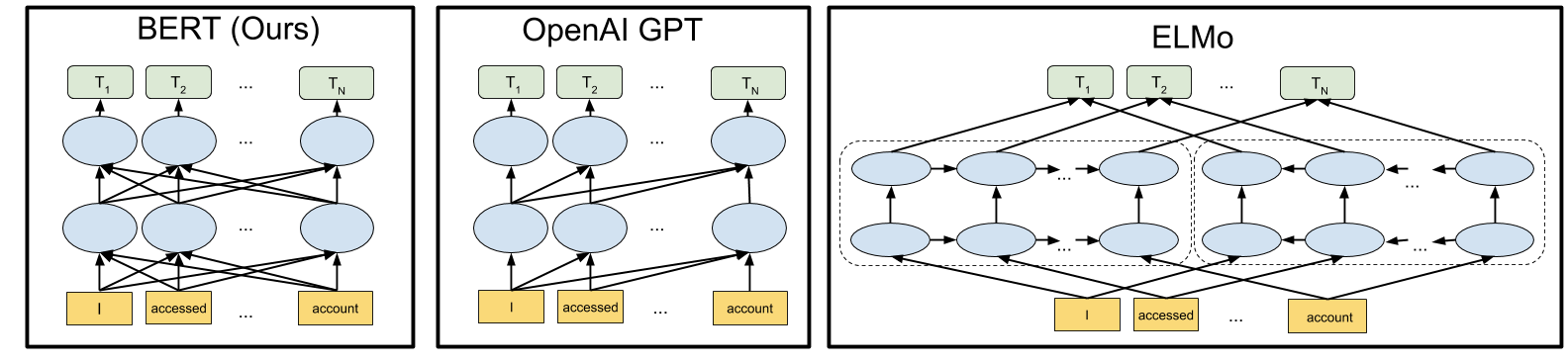
(Bild: Google)
Darüber hinaus hat Google BERT für den effizienten Einsatz auf Cloud TPUs optimiert. Einfache Frage-Antwort-Trainings sollen auf einer einzelnen Cloud TPU binnen 30 Minuten möglich sein – auf einer klassischen GPU in wenigen Stunden. Auch in typischen NLP-Aufgaben wie dem Stanford Question Answering Dataset (SQuAD v1.1) habe BERT sich bereits bewährt. Mit einem Genauigkeitsergebnis (F1 Score) von 93,2 Prozent übertreffe er die menschliche Leistungsfähigkeit (91,2 Prozent Human Performance, Stanford University).
Mehr Details zu den "Bidirectional Encoder Representations from Transformers" (BERT) und deren Leistungsfähigkeit findet sich im Google-AI-Blog. Die Open-Source-Implementierung von TensorFlow mit den BERT-Modellen steht zum Download parat. Alternativ lässt sich der Einstieg in das Arbeiten mit BERT via Colab anhand des Notebooks BERT FineTuning with Cloud TPUs nachvollziehen. (map)
