AMD Radeon Instinct MI50 und MI60: PCIe-4.0-Beschleuniger mit 7-nm-GPU
Mit den Rechenbeschleunigern Radeon Instinct MI50 und MI60 stellt AMD die ersten PCIe-4.0-Grafikchips vor, die zudem im 7-Nanometer-Verfahren hergestellt sind.
Die Machine-Learning-Beschleuniger Radeon Instinct MI50 und MI60 komplettieren AMDs erste Attacke auf den Markt der Rechenzentren. In Radeon Instinct MI50 und MI60 rechnen Grafikprozessoren mit Vega-Architektur, die AMD nicht nur auf 7-Nanometer-Fertigung portiert und geschrumpft hat, sondern auch deutlich überarbeitet hat. Damit will AMD gegen Nvidias Tesla antreten und sich einen Anteil an dem auf 12 Milliarden US-Dollar geschätzten Markt der Beschleuniger für Rechenzentren sichern.
Weiterlesen nach der Anzeige
Laut AMD ist die Radeon Instinct MI60 der aktuell schnellste HPC-Beschleuniger mit PCI-Express-Schnittstelle, was die Gleitkomma-Rechenleistung mit FP32- und FP64-Zahlen angeht. Die Einschränkung auf PCIe ist nötig, weil Nvidias Tesla V100 mit SXM2-Anschluss und NVLink 2.0 noch ein bisschen schneller ist, anders als die PCIe-Variante der Tesla V100.
Schließlich sind die Radeon Instinct MI50 und MI60 dank HBM2-Speicher auch noch die ersten Beschleuniger mit 1 TByte/s Speichertransferrate. AMD will MI50 und MI60 noch im vierten Quartal 2018 auf den Markt bringen.
Radeon Instinc MI60 Blockdiagramm: Ähnlichkeiten zur Vega 10.
(Bild: heise/Carsten Spille)
Dank 7-nm-Fertigung zu neuen Höhen
Der zur Herstellung des Grafikprozessors (GPU) genutzte 7-nm-Prozess der Chipschmiede TSMC erlaubt eine Verdopplung der Transistordichte bei gleichzeitig entweder mehr als 25 Prozent mehr Takt oder 50 Prozent niedrigerer Leistungsaufnahme. Im Falle der neuen Vega-GPUs hat AMD den Takt um nicht ganz 20 Prozent angehoben, daraus ergeben sich schätzungsweise 1,8 GHz. Die nominelle Leistungsaufnahme beträgt 300 Watt.
Die Eckdaten der neuen GPU ähneln denen der Vega-10-GPU von 2017 nur auf den ersten Blick. Beide verfügen über vier Raster-Einheiten, 4096 Shader-Einheiten gruppiert in 64 Compute Units und (vermutlich) 64 Raster-Endstufen. Die MI50-Variante hat nur 16 statt 32 GByte HBM2-Speicher, 60 CUs (3840 Shader) und arbeitet mit errechneten 1,75 GHz. Die neue Vega besteht aus über 13,2 Milliarden Transistoren auf 331 mm² Chipfläche.
Technische Spezifikationen Radeon MI50 und MI60
(Bild: heise/Carsten Spille)
Die neuen Vega-GPUs haben einige für High Performance Computing (HPC) wichtige Ergänzungen erhalten. Dazu gehört die Verdopplung der Transferleitungen der Speicherschnittstelle, die nun über 4096 Datenleitungen vier HBM2-Chips mit insgesamt 32 GByte ansteuert.
Weiterlesen nach der Anzeige
Bei den Rechenwerken wurde einiges an Fläche in die Gleitkommaleistung mit doppelter Genauigkeit (FP64) investiert, die nun mit halber FP32-Geschwindigkeit durchgeführt werden können – die Vorgängergeneration lag noch bei mickrigen 1:16. L1- und L2-Caches sowie die GPU-Register sind zudem nun per ECC gegen Fehler geschützt.
Der Takt des HBM2-Speichers wurde auf 1 GHz angehoben, sodass er nun ein sattes Terabyte pro Sekunde überträgt. Auch das System-Interface ist durch PCIe 4.0 x16 mit aggregierten 64 GByte/s (32 GByte/s pro Richtung) nun doppelt so schnell wie zuvor. Der kommende 7-nm-Epyc "Rome" wird wohl der erste x86-Prozessor mit PCIe 4.0 sein.
Für die Skalierbarkeit im Datenzentrum jedoch noch wichtiger sind Infinity-Fabric-Links. Zwei davon mit jeweils 100 GByte/s bringen MI50 und MI60 mit; das ist sozusagen das AMD-Gegenstück zun Nvidias NVLink 2.0. Ein Infinity-Fabric-Ringbus verbindet vier Radeon-Instinct-Beschleuniger miteinander und gewährt jeder GPU dabei Zugriff auf den gesamten angeschlossenen Speicher (Unified Memory). Zwei dieser Vierergruppen können wiederum über PCIe 4.0 miteinander kommunizieren. Zudem gibt es Hardware-Virtualisierung.
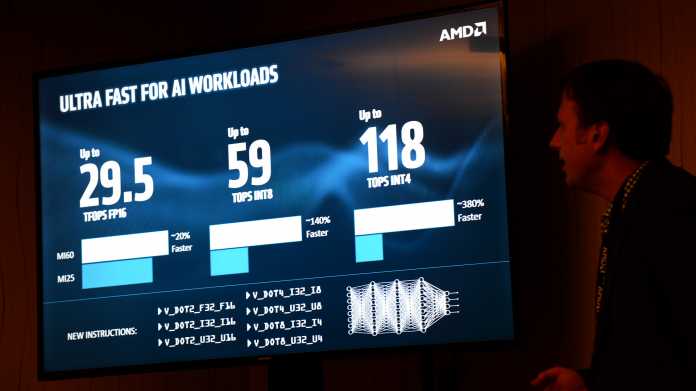
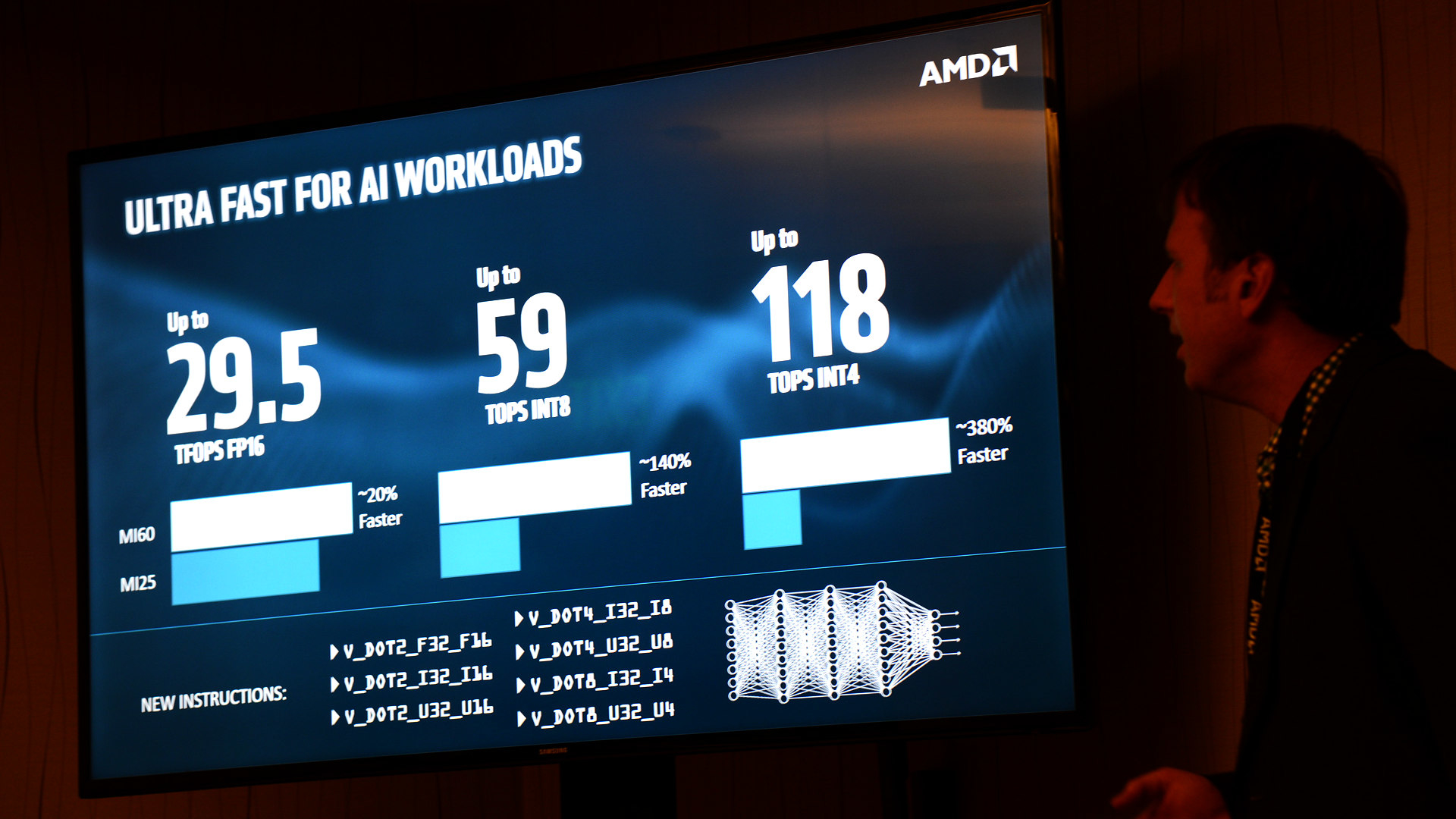
Der reine Arithmetik-Durchsatz stieg im Vergleich zur zwei Jahre alten Radeon Instinct MI25 nur um knapp 18 Prozent. Unter anderem durch den schnelleren Speicher will AMD jedoch im Machine-Learning-Benchmark Resnet-50 mit FP16-Genauigkeit bis zu 2,8 Mal so hohe Werte wie beim Vorgänger-Beschleuniger MI25 erreicht haben.
Mit FP32-Genauigkeit seien es mehr als 50 Prozent Zuwachs in den Benchmarks Resnet-50, Inception-4 sowie VGG16. Die Leistungssteigerung mit FP32-Genauigkeit im Alexnet-Benchmark hingegen läge bei mehr als 25 Prozent und damit eher im Bereich der theoretischen Durchsatzsteigerung.
Auch gegen den Platzhirsch unter den HPC-Beschleunigern, Nvidias Tesla V100, sieht AMD die MI60 trotz weniger als halb so großer Chipfläche konkurrenzfähig. In Resnet-50, SGEMM und DGEMM betrage der Leistungsunterschied nur zwischen -6 und +7 Prozent. Bei Resnet-50 wählte AMD allerdings die FP32-Version, sodass Nvidias Tensor-Kerne außen vorblieben.
Um die Leistung beim Machine Learning zu steigern, kann die AMD-GPU nicht nur FP16-Berechnungen mit doppelter Geschwindigkeit durchführen, sondern kleinere Datentypen wie INT8 oder INT4 mit nochmals verdoppeltem respektive vervierfachtem Durchsatz abarbeiten. So stehen am Ende bis zu 118 Tera-OPS für die MI60 auf der Uhr.
Disclaimer: c't-Redakteur Carsten Spille wurde von AMD zur Veranstaltung "Next Horizon" nach San Francisco eingeladen.