

Machine Learning: Facebook gibt LASER als Open Source frei
LASER – Language-Agnostic SEntence Representations, ist ein Toolkit zum Darstellen von Sätzen in verschiedenen Sprachen als Vektoren. Es ist nun Open Source.

(Bild: whiteMocca/Shutterstock.com)
- Björn Bohn
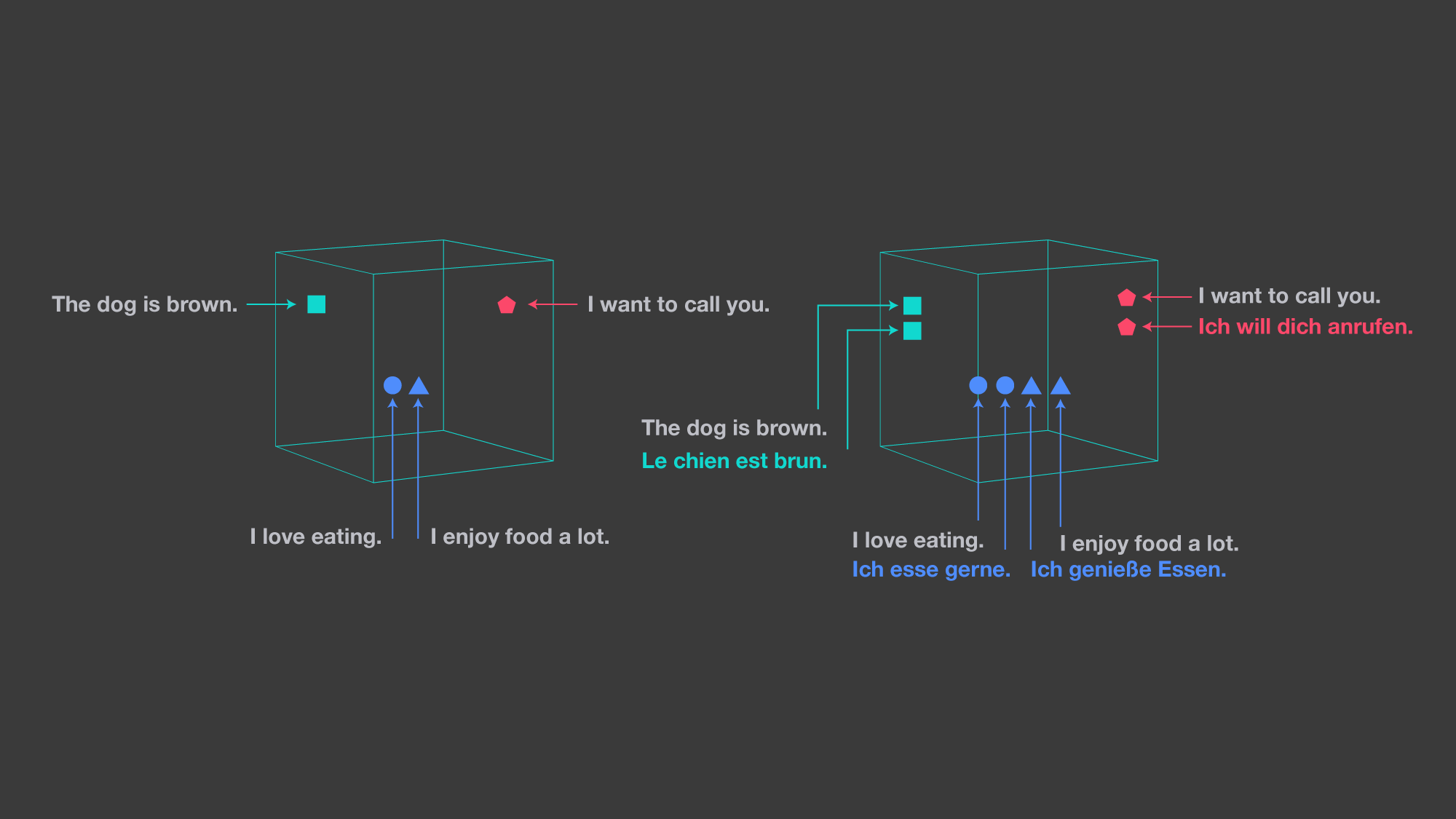
Das von Facebook entwickelte Toolkit LASER (Language-Agnostic SEntence Representations) liegt nun quelloffen vor. Es findet im Bereich des Natural Language Processing (NLP), also der Verarbeitung natürlichsprachlicher Informationen durch einen Computer Anwendung. Genauer gesagt stellt LASER Sätze verschiedener Sprachen als Vektoren dar. Dabei bildet es Sätze verschiedener Sprachen, die aber dieselbe Aussage haben, in einer räumlichen Nähe zueinander ab. Das Toolkit kommt mit 93 Sprachen in 23 Alphabeten zurecht.
(Bild: Facebook)
Facebook hat das Werkzeug in einem Blogbeitrag vorgestellt. Es soll bis zu 2000 Sätze pro Sekunde auf einer GPU verarbeiten können. Es ist in die kürzlich in Version 1.0 erschienene Deep-Learning-Bibliothek PyTorch implementiert – ebenfalls aus dem Hause Facebook. Das Modell soll wohl gute Ergebnisse bei der sogenannten Cross-Lingual Natural Language Interference (NLI) erzielen. Das bedeutet, dass wenn der NLI-Klassifizierer beispielsweise in Englisch trainiert wird, LASER auch in vielen anderen Sprachen gute Ergebnisse erzielt, für die es nicht trainiert wurde – mit einer Abweichung unter 5 Prozent, auch für entferntere Sprachen wie Russisch oder Chinesisch. Auch für Sprachen mit wenigen Materialien sollen die Ergebnisse zufriedenstellend sein.
Die Architektur von LASER
LASER setzt auf eine Encoder/Decoder-Herangehensweise. Der Encoder bildet ein bidirektionales LSTM-Netzwerk (Long Short-term Memory) aus fünf Ebenen. Während der Decoder wissen muss, welche Sprache er generiert, hat der Encoder keine Informationen über die Eingabesprache. Das soll das Trainieren von sprachunabhängigen Abbildungen verbessern. Facebook begann das Training von Laser mit 223 Millionen Sätzen in Englisch und Spanisch und steigerte nach und nach die Anzahl an Sprachen und Alphabeten.

(Bild: Facebook)
Wer mit LASER herumspielen möchte, findet das gesamte Projekt auf GitHub. Als Abhängigkeiten sind unter anderem Python 3.6 und PyTorch 1.0 notwendig. (bbo)
