

C++ Core Guidelines: Weitere Regeln zu Templates
Da sich die verbleibenden Regeln zu Templates nicht unter einem gemeinsamen Begriff zusammenfassen lassen, sind die heterogenen Regeln in dem Abschnitt "other" der C++ Core Guidelines gelandet. Diese beschäftigen sich mit Best Practices und Überraschungen.
- Rainer Grimm
Da sich die verbleibenden Regeln zu Templates nicht unter einem gemeinsamen Begriff zusammenfassen lassen, sind die heterogenen Regeln in dem Abschnitt "other" der C++ Core Guidelines gelandet. Diese beschäftigen sich mit Best Practices und Überraschungen.
Hier ist meine Plan für heute.
- T.140: Name all operations with potential for reuse
- T.141: Use an unnamed lambda if you need a simple function object in one place only
- T.143: Don’t write unintentionally nongeneric code
Bei der ersten Regel geht es gleich um Bewährtes.
T.140: Name all operations with potential for reuse
Ehrlich gesagt, weiß ich nicht, warum diese Regeln zu den Regeln für Templates gehört. Vielleicht, da es bei Templates um Wiederverwendung geht oder da das Beispiel den std::find_if-Algorithmus der Standard Template Library verwendet. Egal! Diese Regel ist entscheidend für guten Code.
Stelle dir vor, du besitzt einen Vektor von einfachen Datensätzen. Jeder Datensatz besteht aus einem Namen, einer Adresse und einer ID. Oft stehst du vor dem Problem, einen bestimmten Datensatz mit einem spezifischen Namen zu finden. Die Aufgabe ist noch schwieriger, denn du achtest bei dem Name nicht auf dessen Groß- oder Kleinschreibung:
// records.cpp
#include <algorithm>
#include <cctype>
#include <iostream>
#include <string>
#include <vector>
struct Rec { // (1)
std::string name;
std::string addr;
int id;
};
int main(){
std::cout << std::endl;
std::vector<Rec> vr{ {"Grimm", "Munich", 1}, // (2)
{"huber", "Stuttgart", 2},
{"Smith", "Rottenburg", 3},
{"black", "Hanover", 4} };
std::string name = "smith";
auto rec = std::find_if(vr.begin(), vr.end(), [&](Rec& r) { // (3)
if (r.name.size() != name.size()) return false;
for (int i = 0; i < r.name.size(); ++i){
if (std::tolower(r.name[i]) != std::tolower(name[i])) return false;
}
return true;
});
if (rec != vr.end()){
std::cout << rec->name << ", " << rec->addr << ", " << rec->id << std::endl;
}
std::cout << std::endl;
}
Die Struktur rec (Zeile 1) besitzt nur öffentliche Mitglieder. Daher lässt sie sich direkt mit Aggregat-Initialisierung in Zeile 2 initialisieren. In der Zeile suche ich mithilfe der Lambda-Funktion nach dem Datensatz, der den Namen "smith" besitzt. Daher prüfe ich zuerst, ob beide Namen gleich lang sind und dann vergleiche ich die Buchstaben unabhängig von ihrer Groß- oder Kleinschreibung.
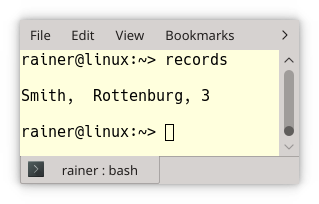
Welches Problem besitzt der Sourcecode? Die Anforderung, Strings unabhängig von dessen Groß- oder Kleinschreibung zu vergleichen, tritt sehr häufig auf. Daher sollte die Lösung der Anforderung in eine Einheit verpackt werden und einen Namen erhalten:
bool compare_insensitive(const std::string& a, const std::string& b) // (1)
{
if (a.size() != b.size()) return false;
for (int i = 0; i < a.size(); ++i){
if (std::tolower(a[i]) != std::tolower(b[i])) return false;
}
return true;
}
std::string name = "smith";
auto res = std::find_if(vr.begin(), vr.end(),
[&](Rec& r) { compare_insensitive(r.name, name); }
);
std::vector<std::string> vs{"Grimm", "huber", "Smith", "black"}; // (2)
auto res2 = std::find_if(vs.begin(), vs.end(),
[&](std::string& r) { compare_insensitive(r, name); }
);
Die Funktion compare_insensitive (Zeile 1) gibt der typischen Anforderung einen Namen. Nun lässt sie sich auf einen Vektor von Strings in Zeile 2 anwenden.
T.141: Use an unnamed lambda if you need a simple function object in one place only
Zugegeben, ich habe häufig eine Diskussion in meinen Schulungen zu der Frage: Wann soll eine Funktion (Funktionsobjekt) oder eine Lambda-Funktion eingesetzt werden? Ehrlich gesagt, ich habe keine einfache Antwort auf diese Frage. Hier widersprechen sich zwei wichtigen Regeln zur Codequalität:
- Don't repeat yourself. (DRY)
- Explicit is better than implicit. (The Zen of Python)
Die zweite Regel musste ich mir von Python ausleihen. Für was steht diese Regel. Stelle dir vor, du hast einen altbackenen Fortran-Programmierer in deinem Team. Dieser entgegnet dir: "Jeder Bezeichner muss genau drei Buchstaben lang sein." Daher kann dein Sourcecode zeitweise das folgende Aussehen besitzen:
auto eUE = std::remove_if(use.begin(), use.end(), igh);
Für was steht zum Beispiel die Funktion igh? Sie steht für eine "id greater hundred". Nun bist du gezwungen, diesen Funktionsaufruf zu dokumentieren.
Wenn du hingegen eine Lambda-Funktion verwendest, dokumentiert sich der Code selbst:
auto earlyUsersEnd = std::remove_if(users.begin(), users.end(),
[](const User &user) { return user.id > 100; });
Glaube mir, ich hatte Diskussionen mit Fortran-Programmierern zu Bezeichnern. Zugegeben, mehr Argumente wie Codelokalität oder Codegröße sprechen für oder gegen Lambda-Funktionen. Die zwei Argumente "Don't repeat yourself" versus "Explicit is better than implicit" sind für mich die zwei entscheidenden Argumente.
T.143: Don’t write unintentionally nongeneric code
Ein einfaches Beispiel sagt mehr als eine lange Erläuterung. In dem folgenden Beispiel iteriere ich durch einen std::vector, eine std::deque und eine std::list:
// notGeneric.cpp
#include <deque>
#include <list>
#include <vector>
template <typename Cont>
void justIterate(const Cont& cont){
const auto itEnd = cont.end();
for (auto it = cont.begin(); it < itEnd; ++it) { // (1)
// do something
}
}
int main(){
std::vector<int> vecInt{1, 2, 3, 4, 5};
justIterate(vecInt); // (2)
std::deque<int> deqInt{1, 2, 3, 4, 5};
justIterate(deqInt); // (3)
std::list<int> listInt{1, 2, 3, 4, 5};
justIterate(listInt); // (4)
}
Der Code wirkt unschuldig. Wenn ich aber das Programm übersetze, bricht dieser Prozess mit einer Fehlermeldung von circa 100 Zeilen ab:
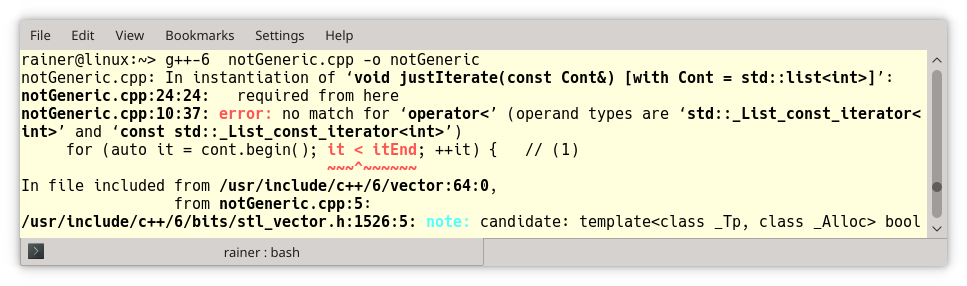
Der Anfang der Fehlermeldung ist sehr präzise: "notGeneric.cpp:10:37: error: no match for ‘operator<’ (operand types are ‘std::_List_const_iterator".
Was ist das Problem? Das Problem ist in der Zeile 1. Der Iteratorvergleich (<) ist für den std::vector (Zeile 2) und für die std::deque (Zeile 3) okay, bricht aber für die std::list (Zeile 4). Jeder Container gibt einen Iterator zurück, der seine Struktur repräsentiert. Das ist im Falle des std::vector und der std::deque ein Random Access Iterator und im Falle der std::list ein Bidirectional Iterator. Ein Blick auf die Iteratorkategorien schafft Aufklärung:

Die Random-Access-Iterator-Kategorie ist eine Obermenge der Bidirectional-Iterator-Kategorie und Letztere ist eine Obermenge der Forward-Iterator-Kategorie. Nun ist das Problem offensichtlich. Ein Iterator, der von einer Liste erzeugt wird, unterstützt den Kleiner-Vergleich nicht. Die Lösung des Problems ist einfach. Iteratoren aller Kategorien unterstützen den !=-Vergleich. Hier ist das generische justIterate-Funktions-Template, das mit den Container der Standard Template Library kann.
template <typename Cont>
void justIterate(const Cont& cont){
const auto itEnd = cont.end();
for (auto it = cont.begin(); it != itEnd; ++it) { // (1)
// do something
}
}
Eine Bemerkung kann ich mir nicht verkneifen. Es ist meist eine schlechte Idee, händisch durch einen Container wie in der Funktion justIterate zu iterieren. Dies ist die Aufgabe eines passenden Algorithmus der Standard Template Library.
Wie geht's weiter?
Mein ursprünglicher Plan war es, in diesem Artikel auf die Regel "T.144: Don’t specialize function templates" einzugehen. Die Regel besitzt ein großes Überraschungspotenzial. Mein nächster Artikel zeigt, warum. ()
