

Künstliche Intelligenz: Rundumschlag zu TensorFlow
Zum Machine-Learning-Framework TensorFlow hat Google unter anderem TF Lite 1.0 und die erste Alpha von TensorFlow 2 veröffentlicht.

Im Rahmen des TensorFlow Dev Summit 2019 im Google Event Center in Sunnyvale, Kalifornien, gab es zahlreiche Ankündigungen rund um das von Google entwickelte Machine-Learning-Framework (ML). So steht TensorFlow 2.0 (TF) mit der ersten Alpha in den Startlöchern, und das auf mobile Endgeräte und Embedded Devices ausgerichtete TF Lite sowie die JavaScript-Implementierung TensorFlow.js sind jeweils als erstes stabile Release erchienen. Sowohl TensorFlow Federation als auch TensorFlow Privacy sollen mit unterschiedlichen Ansätzen die Privatsphäre wahren.
Empfohlener redaktioneller Inhalt
Mit Ihrer Zustimmung wird hier ein externes YouTube-Video (Google Ireland Limited) geladen.
Ich bin damit einverstanden, dass mir externe Inhalte angezeigt werden. Damit können personenbezogene Daten an Drittplattformen (Google Ireland Limited) übermittelt werden. Mehr dazu in unserer Datenschutzerklärung.
Die Pläne zu TensorFlow 2.0 hatte Google Bereits Mitte Januar veröffentlicht. Neben einer aufgeräumten Architektur bringt das ML-Framework einige Änderungen bei den APIs mit, die vor allem das Verteilen von Modellen stabilisieren sollen. Außerdem bekommt die Deep-Learning-Bibliothek Keras die Rolle der Standard-High-Level-API für TensorFlow, die sie inoffiziell ohnehin schon hat.

(Bild: Google)
Alpha-Framework mit Keras-Aufsatz
Die Installation der ersten öffentlich verfügbaren Alpha-Version von TF 2.0 erfolgt über den Paketmanager Pip mit
pip install tensorflow==2.0.0-alpha0
Passend zum frischen Release hat Google auch die TensorFlow-Website überarbeitet. Im Alpha-Test-Bereich finden Interessierte Starthinweise sowohl für Einsteiger als auch für Experten. Außerdem sind auf der Seite die zusammengefassten Neuerungen und der Text zur Standardisierung auf Keras verlinkt. Das Anfänger-Tutorial ist als interaktives Jupyter Notebook umgesetzt und setzt auf Keras, genauer die Keras Sequential API.
Leichtgewicht für mobile Endgeräte
TensorFlow Lite hatte der Internetriese auf der Hausmesse Google I/O erstmals im Mai 2017 vorgestellt und im November 2017 als Preview veröffentlicht. Die schlanke Variante ist auf Endgeräte mit iOS und Android sowie auf Embedded Devices ausgerichtet. Es ist für den Einsatz trainierter Modelle ausgelegt, nicht auf deren rechenintensives Training. TF Lite kombiniert einen plattformunabhängigen Stack mit spezifischen APIs, die auf die jeweilige Zielplattform zugeschnitten sind. Über eine C++-Schnittstelle lassen sich die Modelle laden und der Interpreter anstoßen.
Auf Android existiert ein zusätzlicher Java-Wrapper für die C++-API. Außerdem nutzt TF Lite auf Googles mobilem Betriebssystem die Android Neural Networks API. Eine direkte Anbindung zu CoreML auf iOS existiert nicht, stattdessen lassen sich TensorFlow-Modelle mit einem Konverter in CoreML umwandeln.
Mit dem nun erschienenen 1.0-Relese gilt TensorFlow Lite als stabil. Neben den mobilen Endgeräten lässt es sich auf dem Raspberry Pi sowie AArch64-Boards verwenden. Als nächste Schritte plant Google vor allem Methoden, um die Größe der Modelle für den mobilen Einsatz zu verringern. Außerdem will das Team die CPU-Performance optimieren.
JavaScript und Swift
Die JavaScript-Bibliothek TensorFlow.js für das Verwenden und Trainieren von ML-Modellen hat ebenfalls den stabilen Versionsstand 1.0 erreicht. Google hatte sie 2018 erstmals vorgestellt. Neben dem Sourcecode findet sich auf GitHub ein Repository mit vortrainierten Modellen.
Vom 1.0-Release ist Swift für TensorFlow noch ein wenig entfernt. Zum Dev Summit ist Version 0.2 der Anbindung der von Apple entwickelten und inzwischen quelloffenen Programmiersprache Swift an das ML-Framework erschienen. Letztes Jahr hatte Sprachschöpfer Chris Lattner, der mittlerweile für Google arbeitet, das Projekt auf dem Dev Summit vorgestellt. Es richtet sich sowohl an Entwickler, die in Machine Learning einsteigen, als auch an fortgeschrittene ML-Researcher, die mit der Programmiersprache arbeiten.
Die Privatsphäre im Blick
Gleich zwei neue Bibliotheken sollen eine bessere Wahrung der Privatsphäre beim Trainieren von ML-Modellen sicherstellen. TensorFlow Privacy hat die Privatsphäre sogar im Namen. Es setzt auf Techniken der Differential Privacy. Das Ziel ist, präzise Modelle zu trainieren, die aber keine Rückschlüsse auf die verwendeten Daten zulassen. Differential Privacy ist keine Erfindung von Machine-Learning-Experten, sondern kommt in unterschiedlichen Feldern der Datenverarbeitung und Statistik bereits seit Längerem zum Tragen.
TF Privacy ist eine Python-Bibliothek, die Optimierer zum Trainieren von ML-Modellen mit Differential Privacy enthält. Sie setzt auf TensorFlow auf und ist auf Entwickler und Data Scientists ausgelegt. Spezielle Erfahrungen über die Wahrung der Privatsphäre und die dazu verwendeten Methoden sind wohl nicht erforderlich. TF Privacy soll unter anderem spezifische Details in Texten, Bildern oder anderen Daten herausfiltern, die Rückschlüsse auf die Urheber zulassen.
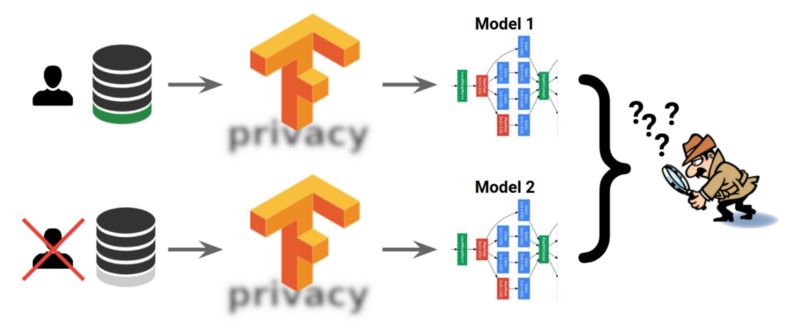
(Bild: Google)
Smartphones vereint euer Training!
Das Konzept des Federated Learning hat Google 2017 vorgestellt. Es sieht vor, dass zahlreiche mobile Endgeräte ein gemeinsames Prediction Model erstellen, ohne die Daten miteinander zu teilen. Die Trainingsdaten bleiben auf dem Smartphone. Das Federated Learning berücksichtigt beim Training die begrenzte Leistung der Endgeräte und dient dabei ebenfalls der verbesserten Privatsphäre.

(Bild: Google)
TensorFlow Federated (TFF) überträgt das Konzept nun in das Machine-Learning-Framework. Das zu trainierende Modell geht an zahlreiche Endgeräte, die es jeweils mit lokalen Daten trainieren. Die Updates fließen nicht einzeln, sondern aggregiert zurück in das Modell. Die Macher von TensorFlow Federated führen ein auf dem MNIST-Datensatz (Modified National Institute of Standards and Technology) basierendes Beispiel auf, einer Sammlung handgeschriebener Zahlen, der sich für das Training von ML-Modellen eignet. Statt die komplette Sammlung dafür zu verwenden, setzt der Ansatz darauf, die Daten der einzelnen freiwilligen Teilnehmer, die ihre Handschriftprobe eingereicht haben, einzeln zu nutzen und über die Federated-Learning-API von TFF zu aggregieren.
Komplettpaket für lokales Machine Learning
Unter dem Namen Coral hat Google zudem eine Plattform veröffentlicht, die Hardwarekomponenten mit Softwaretools verbindet und zusätzlich vortrainierte Modelle mitbringt. Mit dem Toolkit können Entwickler Systeme bauen, bei denen das Training lokal auf dem Endgerät erfolgt.
Im Kern der ersten Serie steht der ASIC (anwendungsspezifische Integrierte Schaltung) für Machine Learning Edge TPU, den Google erstmals 2018 auf der Cloud Next vorgestellt hatte. Ein darauf basierendes Entwickler-Board ist nun als Coral Dev Board verfügbar. Zusätzlich gibt es ein Kameramodul. Ein ebenfalls separater USB Accelerator ermöglicht die Integration in Linux-Systeme inklusive Raspberry Pi über USB 2.0 und 3.0.
Hinsichtlich der Software setzt Coral auf TensorFlow: TF-Lite-Modelle lassen sich quantisieren und kompilieren, damit sie direkt auf der Edge TPU arbeiten. Google bietet trainierte und vorkompilierte Modelle zum Einsatz auf den Coral-Boards an. Darüber hinaus existieren Tools zum erweiterten Training der Modelle.

(Bild: Google)
Vom 14. bis 16. Mai findet in Mannheim die zweite Auflage der Minds Mastering Machines statt. Auf der von heise Developer, iX und dpunkt.verlag veranstalteten Entwicklerkonferenz zu Machine Learning gibt es unter anderem Vorträge zu dem nun als Alpha-Release verfügbaren TensorFlow 2.0 sowie zu TensorFlow Probability. Ein ganztägiger Workshop führt in Deep Learning mit TF 2 und Keras ein.
Weitere Details lassen sich den jeweiligen Ankündigungen zu TensorFlow 2.0 Alpha, TensorFlow Privacy, TensorFlow Federated und Coral entnehmen. (rme)
