Wenn Big Data der Schatz ist, den es zu heben gilt und GPU-Computing die Karte dorthin, markiert AI als X die Position – so oder ähnlich könnte man den Tenor auslegen, der während der Keynote von Nvidia-Boss Jen-Hsun Huang herrschte.
Weiterlesen nach der Anzeige
Amazon und Microsoft im Boot
Mit Amazon Web Services (AWS) gewinnt Nvidia einen weiteren schwergewichtigen Partner unter den Anbietern von Cloud-Rechenleistung – allerdings nicht exklusiv. Amazon wird weiterhin mehrgleisig fahren. Die in Kürze verfügbaren EC2-G4-Instanzen werden mit Tesla T4, die für besonders hohe Rechendichte beim KI-Inferencing optimiert sind, ausgestattet.
Beim Inferencing werden anhand vorab trainierte neuronaler Netze Rückschlüsse anhand von Daten gezogen, beispielsweise also die Objekte auf einem Bild identifiziert. Dabei genügt oft schon eine geringe Ganzzahlpräzision mit 8 Bit (INT8), wenn die KI darauf ausgelegt ist.
Hierbei schaffen die Grafikprozessoren auf den T4-Karten wie schon alle Pascal-GPUs den vierfachen Durchsatz gegenüber dem FP32-Standard, mit INT4 sind sie gar den acht Mal so schnell.Um KIs zu trainieren genügt das nicht, hier wird in vielen Fällen mindestens auf 16-Bit-Gleitkommagenauigkeit zurückgegriffen (FP16). Das können die in Volta und Turing, den Nachfolgern der Pascal-Architektur in den T4-Karten, enthaltenen Tensor-Cores achtmal so schnell. [update] Auch die Tensor Cores beherrschen INT-Genauigkeit. Sie schleusen bei maximalem rechnerischen Turbotakt mit INT8-Präzision 130 TOPS, mit INT4 260 TOPS durch.
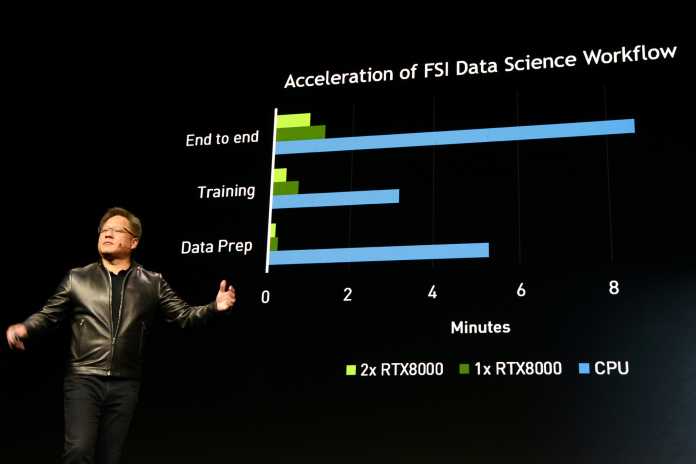
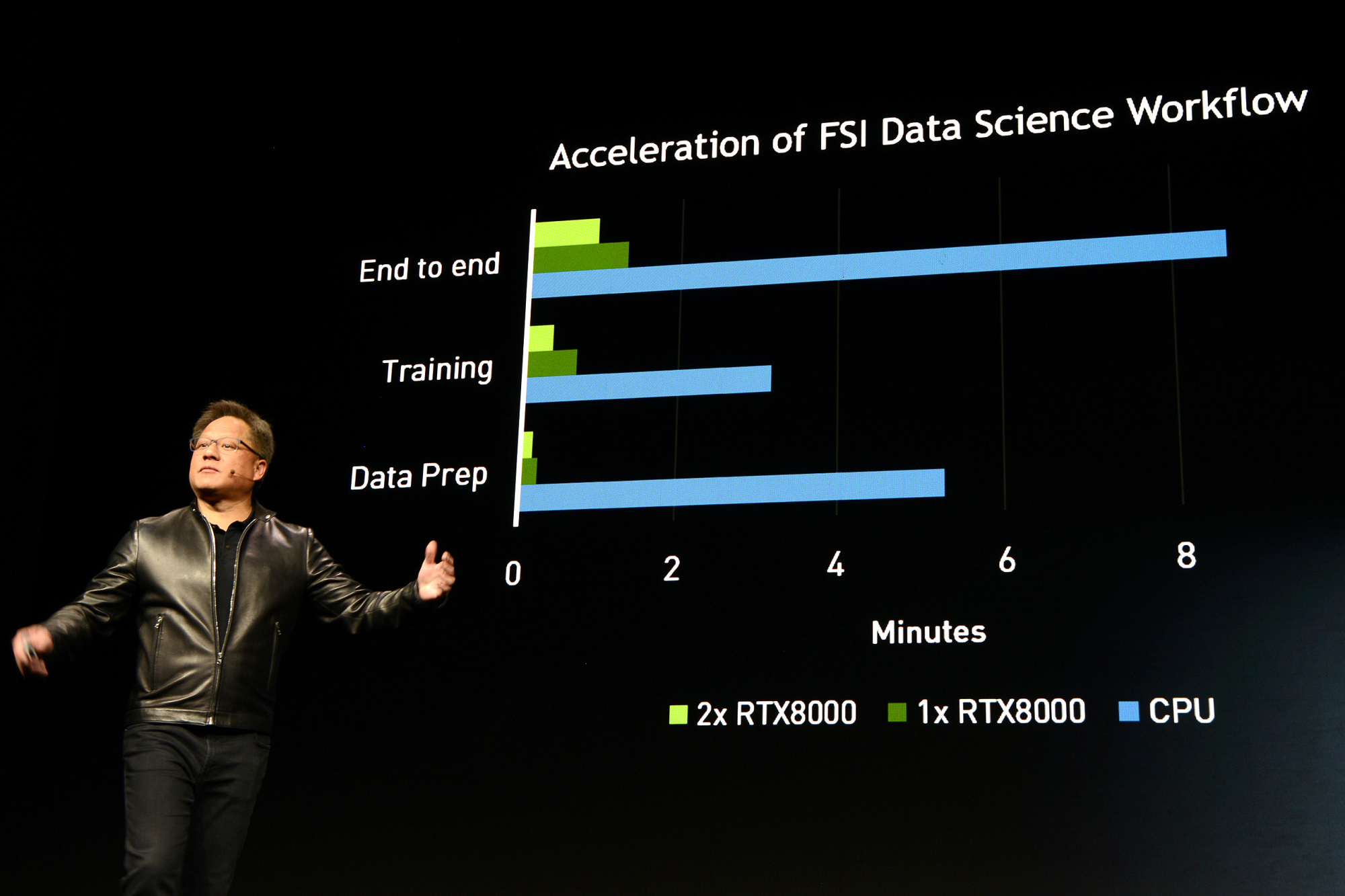
Neben Amazon ist auch Microsoft mit Azure nun mit im Nvidia-Boot. Die Azure Machine Learning Platform nutzt Nvidias RAPIDS-Framework. Am Beispiel des US-Handelsriesen Walmart wurden die Vorzüge erläutert: Die Voraussagen für die Warenwirtschaft sollen mit KI-Systemen genauer ausfallen.
Einen Leistungsvergleich (außerhalb von Walmart) hatte man natürlich auch direkt parat: Um nicht weniger als Faktor 20 sollen sich KI-Trainingszeiten mit RAPIDS reduzieren lassen.
Weiterlesen nach der Anzeige
Datenanalyse profitiert von viel und schnellem Speicher - und hoher Rechenleistung
(Bild: c't / Carsten Spille)
Aus CUDA 10 wird X mit Option auf AI
Passend zum KI-Hype fasst Nvidia unter dem Mantel CUDA-X nun seine Entwickler-Bibliotheken zusammen, um neuen speziell neuen Entwicklern eine homogenere Programmierumgebung zu bieten und sie so zugleich im Nvidia-Universum heimisch werden zu lassen.
CUDA-X AI beinhaltet dabei speziell die Komponenten für Künstliche Intelligenz mit den Unterkategorien Machine Learning, Deep Learning, HPC und Inference. Doch es gibt auch eine echte Neuerung: Mit dem Release als CUDA-X optimieren die enthaltenen Compiler die KI-Umgebungen automatisch für Tensor-Kerne, sofern möglich.
Server mit T4-Beschleunigern und vorinstalliertem und -konfiguriertem CUDA-X AI sind von C wie Cisco bis S wie Sugon erhältlich, verkündete Nvidia.
Hinweis: Nvidia bezahlte Flug und Hotel für c't-Redakteur Carsten Spille.
(csp)