

C++ Core Guidelines: std::array und std::vector sind die erste Wahl
In 99 Prozent aller Anwendungsfälle für einen sequenziellen Container sind std::array und std::vector die idealen Kandidaten. Bedenken hierzu? Hier die Antwort des Autors.
- Rainer Grimm
In 99 Prozent aller Anwendungsfälle für einen sequentiellen Container sind std::array und std::vector die idealen Kandidaten. Höre ich Bedenken? Hier ist meine Antwort.
Heute kann ich mich wirklich kurzfassen. Dies ist die Faustregel: Falls du Elemente von deinem Container entfernen oder hinzufügen willst, ist std::vector dein idealer Kandidat, wenn nicht, verwende ein std::array.
Das war es schon für heute, falls du sehr beschäftigst bist; falls nicht, lies weiter.
Die Details
Die C++ Core Guidelines liefern eine Begründung für die Faustregel in der folgenden Guideline: SL.con.2: Prefer using STL vector by default unless you have a reason to use a different container.
std::array und std::vector können mit den folgenden Eigenschaften punkten:
- the fastest general-purpose access (random access, including being vectorization-friendly);
- the fastest default access pattern (begin-to-end or end-to-begin is prefetcher-friendly);
- the lowest space overhead (contiguous layout has zero per-element overhead, which is cache-friendly).
In meinem letzten Artikel "C++ Core Guidelines: Die Standard-Bibliothek" bin ich bereits ausführlich auf den Punkt drei eingegangen. Der erste Punkt, dass beide Container den beliebigen Zugriff mittels des Index-Operators unterstützen, ist offensichtlich. Da ich mich vermutlich nicht mit einem Autoritätsbeweis aus der Affäre ziehen kann, will ich über den Punkt zwei genauer schreiben. Den vollständigen Überblick zu den sequenziellen Containern der STL gibt die folgende Tabelle:
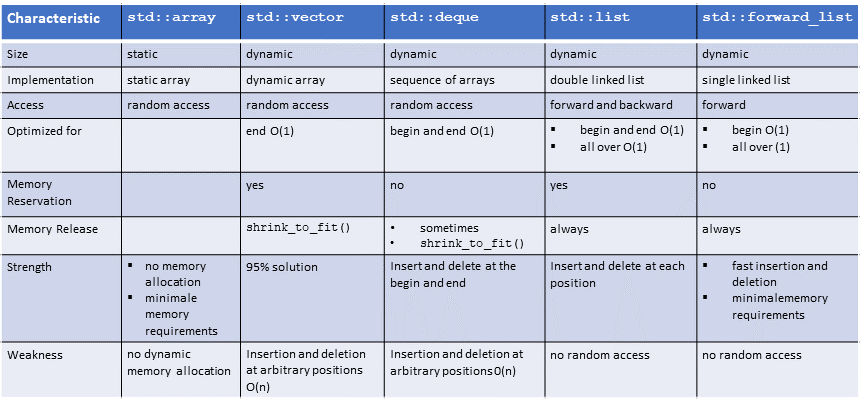
Es gibt fünf sequenzielle Container in der Standard Template Library. Abhängig von deinem Anwendungsfall passt der std::vector in 95 Prozent aller Fälle. Meist musst du zum Container Elemente hinzufügen oder löschen. Die Tabelle besitzt noch deutlich mehr Informationen.
0(i) bezeichnet die Komplexität (Laufzeit) einer Operation. Dabei bedeutet 0(1), dass die Laufzeit einer Operation auf einem Container konstant ist, und 0(n), dass die Laufzeit einer Operation linear von der Anzahl seiner Elemente abhängt. Das heißt im konkreten Fall eines std::vector oder std::array, dass die Zugriffszeit auf seine Elemente immer gleich schnell ist und damit unabhängig von der Anzahl seiner Elemente. Hingegen ist das Einfügen oder Löschen eines beliebigen Elements bei k zusätzlichen Elementen um den Faktor k langsamer. Wie bereits gesagt, gilt der letzte Satz nur für einen std::vector.
std::array und std::vector bieten ähnliche Zugriffszeiten, aber sie besitzen einen weiteren großen Unterschied, den viele Entwickler nicht im Blick haben. Das std::array wird typischerweise auf dem Stack angelegt und der std::vector verwaltet seine Elemente auf dem Heap. Das bedeutet, dass ein std::array nur eine eingeschränkte Anzahl von Elementen besitzen kann, während ein std::vector eine unbeschränkte Anzahl von Elementen besitzen kann.
std::vector und std::deque unterstützen mit C++11 die neue Methode shrink_to_fit. Die Anzahl der Elemente, die ein std::vector oder ein std::deque besitzt (size), ist in der Regel kleiner als die Anzahl der Elemente, die für einen std::vector oder std::deque reserviert sind (capacity). Dies hat einen einfachen Grund. Eine Vergrößerung eines std::vector oder eines std::deque führt nicht automatisch zu einer neuen teuren Anforderung von Speicher. Die neue Methode shrink_to_fit erlaubt es, die Kapazität eines std::vector oder std::deque auf seine Größe zu reduzieren. Dieser Aufruf ist aber nicht bindend. Das heißt, dass die Laufzeit ihn ignorieren kann. Auf allen populären Plattformen hat shrink_to_fit aber den gewünschten Effekt gehabt.
Auch wenn der Zugriff auf die Elemente eines std::vector genau so wie der Zugriff auf ein std::deque die Komplexität 0(1) besitzt, so bedeutet das in keinem Fall, dass beide Operationen gleich schnell sind.
Die Komplexitätszusicherung 0(1) für das Einfügen oder Löschen neuer Elemente in eine doppelt oder einfach verkettete Liste std::list bzw. std::forward_list gilt nur unter der Annahme, dass ein Iterator bereits auf das Element verweist.
Du musst einen überzeugenden Grund besitzen, um den sehr speziellen sequenziellen Container std::forward_list zu verwenden. std::forward_list ist auf minimale Speicheranforderung und hohe Performanz optimiert und kann dann verwendet werden, wenn das Hinzufügen, Extrahieren oder auch Löschen von Elementen nur benachbarte Elemente betrifft. Der Grund für dieses besondere Verhalten ist offensichtlich. std::forward_list als einfach verknüpfter Container kennt nur einen Vorwärts-Iterator und nicht seine Größe. Damit lässt sich eine std::forward_list in vielen Algorithmen der STL nicht verwenden.
Vorhersagbarkeit von Speicherzugriffen
Ich habe bereits gesagt, dass die Zugriffszeit O(1) auf ein Element eines std::vector oder ein std::deque nicht dasselbe bedeutet. Gleich präsentiere ich mein einfaches Experiment, das ich bereits im Artikel "C++ Core Guidelines: Die verbleibenden Regeln zur Performanz" behandelt habe. Dies ist genau der Grund, warum ich meine Erläuterungen einfach halten werde.
Wenn eine Variable int vom Hauptspeicher gelesen wird, werden tatsächlich deutlich mehr als 4 Bytes vom Speicher gelesen. Eine ganze Cacheline wird gelesen und im Cache gespeichert. Auf modernen Architekturen besitzt eine Cacheline typischerweise 64 Bytes. Wenn nun nochmals eine Variable aus dem Hauptspeicher angefordert wird und sich die Variable bereits im Cache befindet, verwendet die Leseoperation direkt den Cache und ist damit deutlich schneller.
Ich möchte gerne testen, was diese Aussage für einen std::vector, eine std::deque, ein std::list und eine std::forward_list bedeutet. Aufgrund der limitierenden Größe ignoriere ich ein std::array in meinem Test.
Das war die Theorie zu den Cachelines. Jetzt bin ich neugierig, ob es einen Unterschied ausmacht, die Elemente eines std::vector, einer std::deque, einer std::list oder einer std::forward_list zu addieren. Das kleine Programm soll die Antwort liefern:
// memoryAcess.cpp
#include <forward_list>
#include <chrono>
#include <deque>
#include <iomanip>
#include <iostream>
#include <list>
#include <string>
#include <vector>
#include <numeric>
#include <random>
const int SIZE = 100'000'000;
template <typename T>
void sumUp(T& t, const std::string& cont){ // (6)
std::cout << std::fixed << std::setprecision(10);
auto begin= std::chrono::steady_clock::now();
std::size_t res = std::accumulate(t.begin(), t.end(), 0LL);
std::chrono::duration<double> last= std::chrono::steady_clock::now() - begin;
std::cout << cont << std::endl;
std::cout << "time: " << last.count() << std::endl;
std::cout << "res: " << res << std::endl;
std::cout << std::endl;
std::cout << std::endl;
}
int main(){
std::cout << std::endl;
std::random_device seed; // (1)
std::mt19937 engine(seed());
std::uniform_int_distribution<int> dist(0, 100);
std::vector<int> randNumbers;
randNumbers.reserve(SIZE);
for (int i=0; i < SIZE; ++i){
randNumbers.push_back(dist(engine));
}
{
std::vector<int> myVec(randNumbers.begin(), randNumbers.end());
sumUp(myVec,"std::vector<int>"); // (2)
}
{
std::deque<int>myDec(randNumbers.begin(), randNumbers.end());
sumUp(myDec,"std::deque<int>"); // (3)
}
{
std::list<int>myList(randNumbers.begin(), randNumbers.end());
sumUp(myList,"std::list<int>"); // (4)
}
{
std::forward_list<int>myForwardList(randNumbers.begin(), randNumbers.end());
sumUp(myForwardList,"std::forward_list<int>"); // (5)
}
}
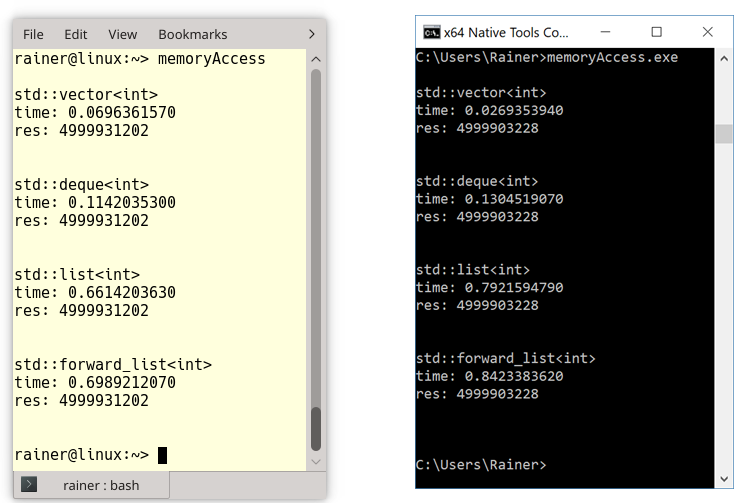
Das Programm memoryAccess.cpp erzeugt zuerst einmal 100 Millionen Zufallszahlen zwischen 0 und 100 (1). Dann summiert es die Zahlen mit einem std::vector (2), einer std::deque (3), einer std::list (4) und einer std::forward_list (5) zusammen. Die eigentliche Arbeit findet in der Funktion sumUp (6) statt.
Ich übersetzte das Programm mit maximaler Optimierung unter Linux und Windows. Mich interessiert in diesem Fall nicht der Performanzunterschied zwischen Linux und Windows, da dies ein Vergleich zwischen einem Desktop-PC und einem Laptop wäre. Mich interessiert die Leseperformanz der vier Container. Hier ist sie:
Um meine Performanztest einfach zu visualisieren, stellt sie die folgende Grafik dar.
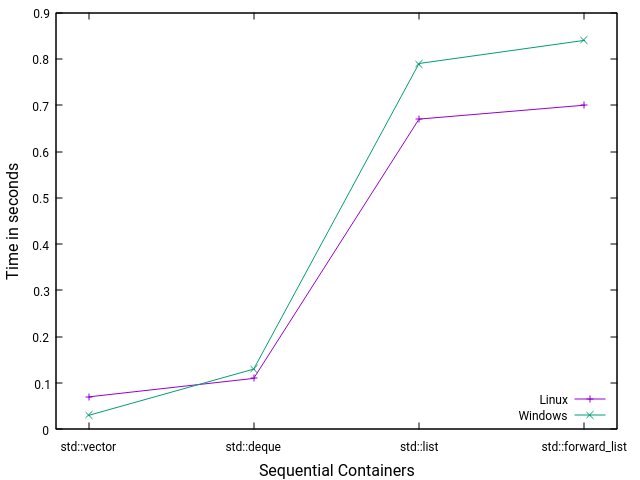
Ich will die Performanzzahlen nicht überbewerten, aber eine Beobachtung lässt sich auf jeden Fall ableiten. Je optimierter eine Datenstrukur für Cachelines ist, desto schneller ist die Zugriffszeit: std::vector > std::deque > (std::list, std::forward_list).
Wie geht's weiter?
Ich denke, ich werde einen ähnlichen Artikel zu den assoziativen Containern der Standard Template Library schreiben. Für mein Gefühl sind sie in den C++ Core Guidelines unterrepräsentiert. Im nächsten Artikel geht es daher um assoziative Container wie std::map und std::unordered_map. ()
