

Eine Einführung in die Azure Cosmos DB
Nicht immer eignen sich relationale Datenbanken zum dauerhaften Speichern von Daten. In den letzten Jahren sind verstärkt nichtrelationale Alternativen in den Fokus der (Enterprise-Anwendungs-)Entwicklung gerückt, darunter dokumentenbasierte Datenbanken, Key-Value-Stores und Graphdatenbanken.

- Thomas Haug
Die Azure Cosmos DB ist ein noch junges NoSQL-Datenbankangebot in der Azure Cloud. Sie ist seit Mai 2017 als Service verfügbar und löst die seit 2014 von Microsoft bereitgestellte Azure DocumentDB ab. Sie erweitert deren Funktionsumfang deutlich, da ihr kontinuierlich neue Funktionen hinzugefügt werden. Beispielsweise ist die Cassandra API, eine von insgesamt fünf Zugriffsvarianten, erst in den vergangenen Monaten dem Preview-Status entwachsen, und auch die Möglichkeit, mehrere Schreibregionen anzulegen, ist erst seit wenigen Monaten verfügbar.
Die Datenbank zählt zu den sogenannten "foundational services" der Azure-Plattform und ist somit weltweit verfügbar. Die Cosmos DB lässt sich im Azure-Portal direkt auswählen.

Folgende zentrale Eigenschaften zeichnen Cosmos DB aus:
- weltweit verteilte Datenbank
- weitgehende Konsistenzgarantien
- ausgeklügeltes Partitionierungssystem
- Multi-Modell
- Schemafreiheit mit automatischer Indizierung
Im Folgenden beschreibt der Autor die Aspekte Verteilung, Konsistenzmodelle, Multi-Modell und automatische Indizierung.
Global und weltweit verteilt
Als weltweit verteilte Datenbank stellt Microsoft die Cosmos DB als Cloud-Dienst bereit. Hierfür bietet Azure Regionen an, in denen sich die Datenbank ausführen lässt. Wer eine neue Cosmos-DB-Instanz anlegt, muss eine Schreibregion (Write Region) angeben und kann mehrere Leseregionen (Read Region) definieren. Im Azure-Portal wird das für jede erzeugte Datenbank visualisiert:
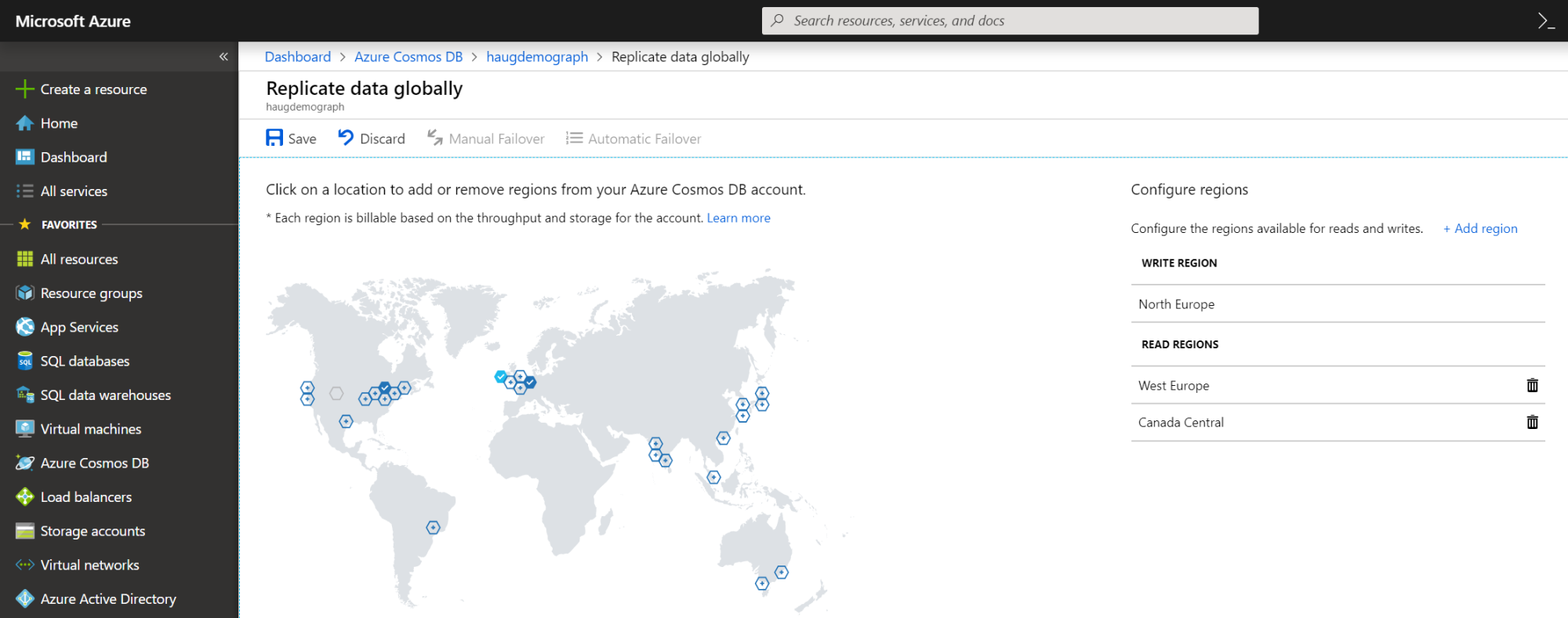
Abhängig von den Anwendungsbedürfnissen ist es möglich, die Daten so zu verteilen, dass sie nahe am Ort der Nutzung liegen. Cosmos DB verteilt gespeicherte Daten transparent in alle konfigurierten Regionen. Für den unwahrscheinlichen Fall, das die Write Region nicht verfügbar ist, gibt es in Cosmos DB die Option, einen automatischen Failover der Write Region auf eine Read Region durchzuführen, die im Folgenden für Schreiboperationen genutzt wird. Hierzu kann man im Portal den automatischen Failover aktivieren und die Reihenfolge der zu verwendenden Leseregionen festlegen.

Ein neues Feature sind sogenannte Multi-region Writes, die bei der Anlage einer Cosmos-DB-Instanz zu aktivieren sind:

Ist das geschehen, lässt sich jede Region sowohl zum Lesen als auch zum Schreiben von Daten nutzen. Innerhalb des Portals wird nun bei der Hinzunahme einer Region angezeigt, dass diese Region read/write aktiviert ist (Abb. 5).

Ein manueller oder automatischer Failover ergibt in dieser Konfiguration keinen Sinn, da grundsätzlich mehrere Schreibregionen vorhanden sind.
Für Anwendungen, die eine geografisch verteilte Cosmos DB nutzen, sind Veränderungen dieser Verteilung transparent, da die sogenannten Multihoming APIs immer die geografisch am Nächsten gelegene Region wählt. Das Hinzufügen beziehungsweise Entfernen von Regionen lässt sich spontan durchführen. Das heißt, die Infrastruktur der Datenbank sorgt automatisch und transparent für die notwendigen Veränderungen.
