

Mehr Regeln zu regulären Ausdrücken
Es gibt mehr zur Anwendung von regulären Ausdrücken zu schreiben, als das was im Artikel "The Regular Expression"-Bibliothek geschrieben wurde. Nun geht es weiter.
- Rainer Grimm
Es gibt mehr zur Anwendung von regulären Ausdrücken zu schreiben, als das was ich in meinem letzten Artikel "The Regular Expression"-Bibliothek schrieb. Heute geht es weiter.
Der Text bestimmt den regulären Ausdruck, das Ergebnis und die Erfassungsgruppen
Zuerst einmal muss ich mich genauer ausdrücken. Der Datentyp des Textes bestimmt den Typ des regulären Ausdrucks, den Typ des Ergebnisses und den Typ der Erfassungsgruppen. Natürlich gilt meine Argumentation auch, wenn ich sie auf andere Bereiche der Funktionalität regulärer Ausdrücke anwende. Eine Erfassungsgruppe ist ein Teilausdruck in deinem Suchergebnis, der sich mit runden Klammern definieren lässt. In meinen letzten Artikel "The Regular Expression"-Bibliothek habe ich bereits darüber geschrieben.
Die Tabelle zeigt alle Datentypen, die vom Typ des Textes abhängen.

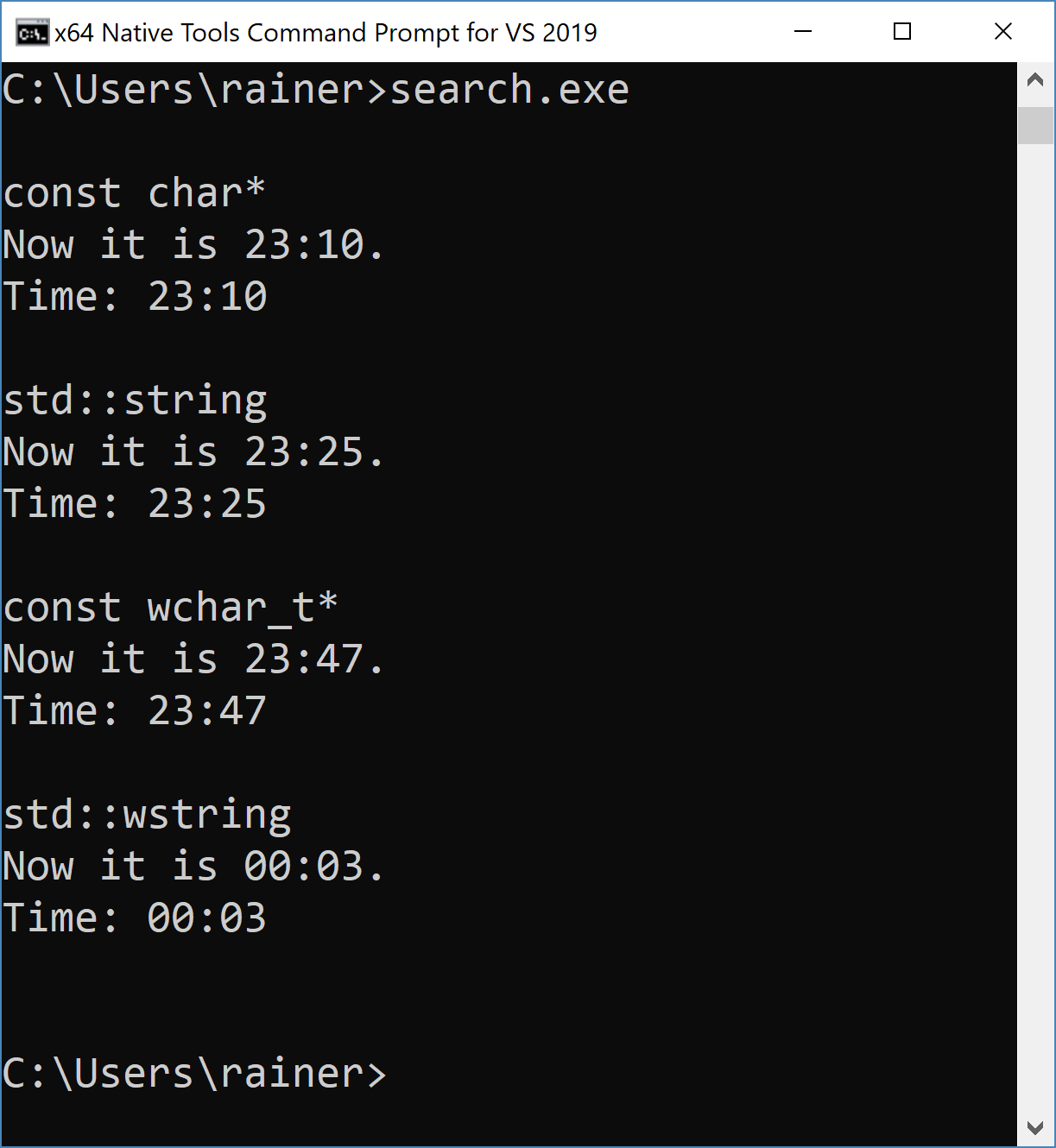
Das folgende Beispiel zeigt alle Varianten von std::regex_search, die vom Datentyp des Textes abhängen.
// search.cpp
#include <iostream>
#include <regex>
#include <string>
int main(){
std::cout << std::endl;
// regular expression for time
std::regex crgx("([01]?[0-9]|2[0-3]):[0-5][0-9]");
// const char*
std::cout << "const char*" << std::endl;
std::cmatch cmatch;
const char* ctime{"Now it is 23:10."};
if (std::regex_search(ctime, cmatch, crgx)){
std::cout << ctime << std::endl;
std::cout << "Time: " << cmatch[0] << std::endl;
}
std::cout << std::endl;
// std::string
std::cout << "std::string" << std::endl;
std::smatch smatch;
std::string stime{"Now it is 23:25."};
if (std::regex_search(stime, smatch, crgx)){
std::cout << stime << std::endl;
std::cout << "Time: " << smatch[0] << std::endl;
}
std::cout << std::endl;
// regular expression holder for time
std::wregex wrgx(L"([01]?[0-9]|2[0-3]):[0-5][0-9]");
// const wchar_t*
std::cout << "const wchar_t* " << std::endl;
std::wcmatch wcmatch;
const wchar_t* wctime{L"Now it is 23:47."};
if (std::regex_search(wctime, wcmatch, wrgx)){
std::wcout << wctime << std::endl;
std::wcout << "Time: " << wcmatch[0] << std::endl;
}
std::cout << std::endl;
// std::wstring
std::cout << "std::wstring" << std::endl;
std::wsmatch wsmatch;
std::wstring wstime{L"Now it is 00:03."};
if (std::regex_search(wstime, wsmatch, wrgx)){
std::wcout << wstime << std::endl;
std::wcout << "Time: " << wsmatch[0] << std::endl;
}
std::cout << std::endl;
}
Zuerst kommt ein Text vom Typ const char*, vom Typ std::string, vom Typ const wchar_t* und zum Abschluss vom Typ std::wstring zum Einsatz. Da es fast immer der identische Code in den vier Variationen ist, werde ich mich für den Rest des Artikels nur noch auf std:.string beziehen.
Der Text enthält einen Teil-String, der für eine Zeitangabe steht. Dank dem regulären Ausdruck "([01]?[0-9]|2[0-3]):[0-5][0-9]" lässt sich nach diesem im Text suchen. Der reguläre Ausdruck definiert ein Zeitformat, das aus einer Stunde und einer Minute besteht, die durch Doppelpunkt separiert sind. Hier sind ein paar Erläuterungen zu dem Stunden- und dem Minutenanteil:
- Stunde: [01]?[0-9]|2[0-3]:
[01]?: 0 oder 1 (optional)[0-9]: eine Zahl von 0 bis 9|: steht für oder2[0-3]: 2, gefolgt von einer Zahl von 0 bis 3
- Minute:
[0-5][0-9]: eine Zahl von 0 bis 5, gefolgt von einer Zahl von 0 bis 9
Zum Abschluss die Ausgabe des Programms.
Verwende regex_iterator oder regex_token_iterator für wiederholtes Suchen
Verwende keine wiederholenden std::search-Aufrufe, denn es passiert sehr leicht, dass du Wortgrenzen verlierst oder leere Treffer erhältst. Verwende stattdessen std::regex_iterator oder std::regex_token_iterator für wiederholtes Suchen. std::regex_token_iterator erlaubt es darüber hinuaus, die Komponenten der Erfassungsgruppen oder den Text zwischen den Treffern zu adressieren.
Das "Hello World" der wiederholten Suche mit regulären Ausdrücken ist es, zu zählen, wie häufig ein Wort in einem Text vorkommt. Hier ist das Programm, das die Aufgabe löst.
// wordCount.cpp
#include <algorithm>
#include <cstdlib>
#include <fstream>
#include <iostream>
#include <regex>
#include <string>
#include <map>
#include <unordered_map>
#include <utility>
using str2Int = std::unordered_map<std::string, std::size_t>; // (1)
using intAndWords = std::pair<std::size_t, std::vector<std::string>>;
using int2Words= std::map<std::size_t,std::vector<std::string>>;
// count the frequency of each word
str2Int wordCount(const std::string &text) {
std::regex wordReg(R"(\w+)"); // (2)
std::sregex_iterator wordItBegin(text.begin(), text.end(), wordReg); // (3)
const std::sregex_iterator wordItEnd;
str2Int allWords;
for (; wordItBegin != wordItEnd; ++wordItBegin) {
++allWords[wordItBegin->str()];
}
return allWords;
}
// get to each frequency the words
int2Words frequencyOfWords(str2Int &wordCount) {
int2Words freq2Words;
for (auto wordIt : wordCount) {
auto freqWord = wordIt.second;
if (freq2Words.find(freqWord) == freq2Words.end()) {
freq2Words.insert(intAndWords(freqWord, {wordIt.first}));
} else {
freq2Words[freqWord].push_back(wordIt.first);
}
}
return freq2Words;
}
int main(int argc, char *argv[]) {
std::cout << std::endl;
// get the filename
std::string myFile;
if (argc == 2) {
myFile = {argv[1]};
} else {
std::cerr << "Filename missing !" << std::endl;
exit(EXIT_FAILURE);
}
// open the file
std::ifstream file(myFile, std::ios::in);
if (!file) {
std::cerr << "Can't open file " + myFile + "!" << std::endl;
exit(EXIT_FAILURE);
}
// read the file
std::stringstream buffer;
buffer << file.rdbuf();
std::string text(buffer.str());
// get the frequency of each word
auto allWords = wordCount(text);
std::cout << "The first 20 (key, value)-pairs: " << std::endl;
auto end = allWords.begin();
std::advance(end, 20);
for (auto pair = allWords.begin(); pair != end; ++pair) { // (4)
std::cout << "(" << pair->first << ": " << pair->second << ")";
}
std::cout << "\n\n";
std::cout << "allWords[Web]: " << allWords["Web"] << std::endl; // (5)
std::cout << "allWords[The]: " << allWords["The"] << "\n\n";
std::cout << "Number of unique words: ";
std::cout << allWords.size() << "\n\n"; // (6)
size_t sumWords = 0;
for (auto wordIt : allWords)
sumWords += wordIt.second;
std::cout << "Total number of words: " << sumWords << "\n\n";
auto allFreq = frequencyOfWords(allWords);
// (7)
std::cout << "Number of different frequencies: " << allFreq.size() << "\n\n";
std::cout << "All frequencies: "; // (8)
for (auto freqIt : allFreq)
std::cout << freqIt.first << " ";
std::cout << "\n\n";
std::cout << "The most frequently used word(s): " << std::endl; // (9)
auto atTheEnd = allFreq.rbegin();
std::cout << atTheEnd->first << " :";
for (auto word : atTheEnd->second)
std::cout << word << " ";
std::cout << "\n\n";
// (10)
std::cout << "All words which appear more than 1000 times:" << std::endl;
auto biggerIt =
std::find_if(allFreq.begin(), allFreq.end(),
[](intAndWords iAndW) { return iAndW.first > 1000; });
if (biggerIt == allFreq.end()) {
std::cerr << "No word appears more than 1000 times !" << std::endl;
exit(EXIT_FAILURE);
} else {
for (auto allFreqIt = biggerIt; allFreqIt != allFreq.end(); ++allFreqIt) {
std::cout << allFreqIt->first << " :";
for (auto word : allFreqIt->second)
std::cout << word << " ";
std::cout << std::endl;
}
}
std::cout << std::endl;
}
Um den Progammfluss besser zu verstehen, habe ich ein paar Kommentare in das Programm eingefügt.
Die using-Deklaration in Zeile 1 hilft mir, meine Schreibarbeit zu minimieren. Die Funktion wordCount bestimmt die Häufigkeit jedes Wortes und die Funktion frequencyOfWords gibt zu jeder Häufigkeit alle Wörter zurück. Was ist ein Wort? Die Zeile 2 definiert dies mit einem regulären Ausdruck und Zeile 3 verwendet diesen in std::regex_iterator. Welche Fragen lassen sich mit den zwei Funktionen beantworten?
- Line 4: die ersten 20 (Schlüssel, Wert)-Paare
- Line 5: Häufigkeit der Wörter "Web" und "The"
- Line 6: Anzahl der eindeutigen Wörter
- Line 7: Anzahl der verschiedenen Häufigkeiten
- Line 8: alle vorkommenden Häufigkeiten
- Line 9: das am häufigsten verwendete Wort
- Line 10: Wörter, die mehr als 1000 Mal vorkommen
Jetzt benötige ich natürlich noch einen längeren Text. Klar, ich verwende Grimms' Märchen vom Projekt Gutenberg. Hier ist das Ergebnis:

Wie geht's weiter?
Nun bin ich fast fertig mit den regulären Ausdrücken. Eine Regel habe ich aber noch, die das wiederholte Suchen meist einfacher macht: Suche nicht nach dem Textmuster, sondern nach dem Trenner des Textmusters. Ich nenne diese Technik negative Suche. ()
