

Stream-Verarbeitung: Hazelcast Jet 4.1 strömt über Kubernetes
Für das Framework zum Verarbeiten paralleler Datenströme existieren Operatoren für Kubernetes und OpenShift. Außerdem gibt es neue Data-Sink-APIs für Java.

Das vor allem für sein In-Memory Data Grid (IMDG) bekannte Unternehmen Hazelcast hat Jet 4.1 veröffentlicht. Das Framework zum Verarbeiten paralleler Datenströme bringt im aktuellen Release Operatoren für Kubernetes und OpenShift mit. Außerdem lassen sich Java-Backends über direkte APIs als Datensenken anbinden.
Einmal versenkt und nie wieder
Jet kennt für die Anbindung der Data Sinks mit Exactly-Once-Garantie neuerdings sowohl Java Database Connectivity (JDBC) als auch den Java Message Service (JMS). Sie lassen sich in verteilte Transaktionsprozesse einbinden, die sicherstellen, dass das System die Daten genau einmal verarbeitet.
In Version 4.0 hatte das Framework bereits eine JMS-Anbindung für Exactly-Once- sowie At-least-once-Prozesse eingeführt. Letztere gewähren eine mindestens einmalige Verarbeitung, die aber auch häufiger sein darf. Allerdings beschränkte sich die Integration dabei auf JMS-Quellen und nicht auf Datensenken.
Stream aus dem Container
Für den Einsatz im Container sind nun zwei neue Operatoren verfügbar: Im Red Hat Marketplace steht neuerdings der Hazelcast Jet Enterprise Operator for Openshift bereit, während der Hazelcast Jet Kubernetes Operator auf GitHub zu finden ist.
Eine neue ServiceFactory dient zum Zugriff auf externe gRPC-Dienste. Entwickler können sowohl bidirektionale als auch unäre RPCs anbinden. Letztere arbeiten wie normale Funktionsaufrufe: Der Client sendet eine einzelne Anfrage und erhält eine einzelne Response als Antwort. Bei der bidirektionalen Kommunikation senden dagegen beide Seiten Nachrichten über zwei unabhängige Read-Write-Streams.
Datenpipeline von der Quelle zur Senke
Hazelcast Jet dient zum Verarbeiten von Batch-Daten und Datenströmen. Das Unternehmen hatte das Framework 2017 erstmals vorgestellt. Jet setzt auf eine Pipeline in Form sogenannter Directed Acyclic Graphs (DAG), also gerichtete, azyklische Graphen. Generatoren verarbeiten die eingehenden Daten und verteilen sie an Akkumulatoren.
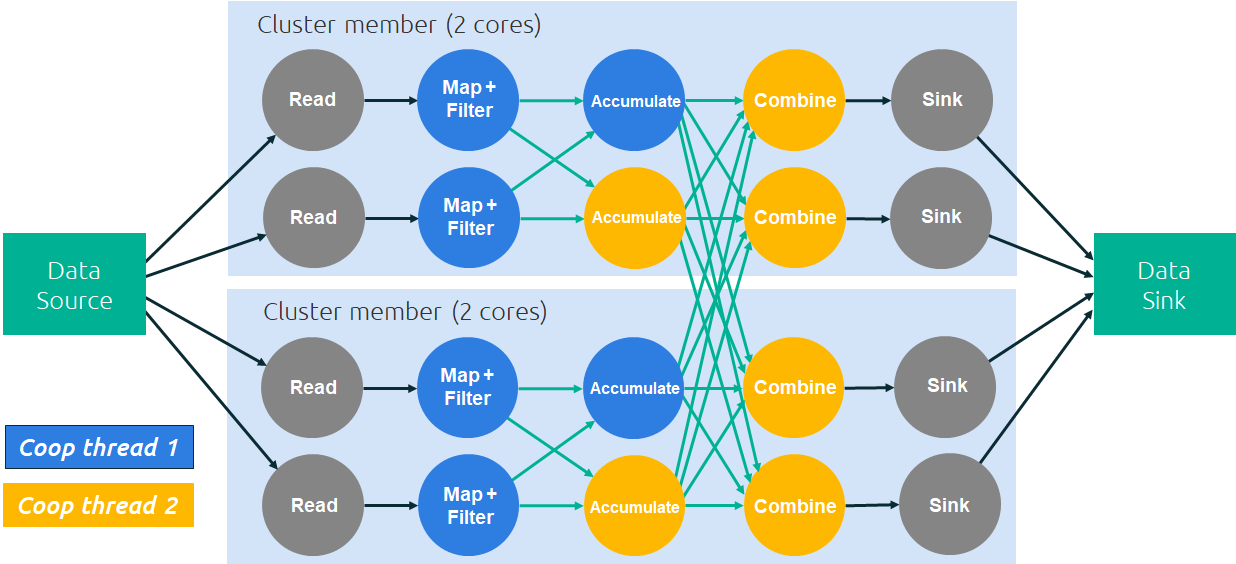
(Bild: Hazelcast)
Anschließend folgt die Zusammenführung in sogenannten Combiners, die das Ergebnis zum gewünschten Output liefern. Die ersten Verarbeitungsschritte erfolgen jeweils innerhalb eines Nodes, aber für die Zusammenführung überwindet das System die Cluster- und Knotengrenzen.
Weitere Neuerungen in Jet 4.1 wie die innerHashJoin-Transformation lassen sich den Release Notes entnehmen. Das Framework steht als Open-Source-Projekt auf GitHub bereit.
(rme)
