

Top500-Supercomputer: Japan überrundet alten Spitzenreiter mit 415 PFlops
Der erste Supercomputer, den man je nach Gesichtspunkt bereits als Exascale-System bezeichnen kann, kommt nicht aus China oder den USA, sondern aus Japan.

(Bild: Riken Center for Computational Science)
Mit 415 PFlops im Linpack-Benchmark setzt sich der japanische Supercomputer Fugaku mit ARM-Prozessoren von Fujitsu ganz klar an die Spitze der neuen 55. Top500-Liste der Supercomputer, die heute zum Auftakt der online abgehaltenen ISC 2020 Digital vorgestellt wurde.
Ähnlich wie einst vor nunmehr fast 20 Jahren der Earth-Simulator von NEC und der K-Computer vor fast 10 zehn Jahren setzt auch diesmal ein japanisches System als neue Nummer Eins neue Maßstäbe. Diesmal ist das System gut 2,8 mal so schnell wie der bisherige Spitzenreiter, der amerikanische Summit mit IBM Power9 und Nvidia Tesla V100.
Japan hängt bisher schnellsten Supercomputer ab
Beim HPCG-Benchmark, der wesentlich speicherlastiger ausfällt als der gängige Linpack, zeigt sich die Dominanz noch gravierender: Mit 13,4 PFlops ist er über viermal so schnell wie der Summit. In einfacher Genauigkeit kommt die theoretische Spitzenleistung des Fugaku gar auf über 1 Exaflops, weshalb man Fugaku durchaus auch als erstes Exascale-System bezeichnen kann. Der Fujitsu-A64FX-Prozessor mit 48 CPU-Kernen benötigt dazu keine zusätzlichen Beschleunigungs-Chips, sondern hat eine integrierte Scalable Vector Extension (SVE), die ähnlich wie Intels AVX512 derzeit mit 512 Bit Breite, 32 Registern und Predication-Registern aufwartet. Vom Konzept her soll SVE allerdings bei späteren Implementierungen mit 1024 oder 2048 Bit Breite ohne Softwareänderung automatisch skalieren.

(Bild: Nvidia)
Aber Fugaku stellt nicht das einzige neue System in den Top Ten der Liste dar. Der neue schnellste Rechner in Europa, der italienische HPC5 des Mineralölkonzerns ENI von Dell mit Intels Cascade-Lake-Prozessoren und Nvidias Tesla-V100-Beschleunigern, zieht mit 51,7 PFlops auf Platz 5 in die Liste ein.
Auch dahinter auf Platz 6 folgt mit 23,5 Pflops ein weiteres Neusystem, das erste namens Selene mit Nvidias Ampere-GPUs A100, das den firmeneigenen Saturn V mit Tesla V100 ersetzt – Nvidia betreibt es also selbst. Die zugrundeliegenden 280 DGX-Systeme sind nunmehr mit AMDs Epyc (Rome) und nicht mehr mit Intels Xeon bestückt.
Und damit nicht genug an Neulingen in den Top 10: Italien hat nun auch den zweitschnellsten Rechner in Europa: Der Marconi100 des italienischen Forschungsverbundes Cineca ist ein kleiner Bruder des amerikanischen Summits samt IBM-Power9-CPUs und Nvidia Tesla V100. Mit 21,6 PFlops verdrängt er den bisherigen europäischen Spitzenreiter Piz Daint des schweizerischen Supercomputerzentrums in Lugano mit 21,2 PFlops auf Platz 10. Soviel Neuerungen auf den ersten Plätzen hat man seit vielen Jahren nicht mehr gesehen. In der letzten 54. Liste gab es bis auf ein Upgrade gar keine.
Top10 der Top500-Liste vom Juni 2020 (10 Bilder)

Nr. 1
(Bild: Riken Center for Computational Science)
Vermisstes …
So mancher hatte mit leistungsfähigen neuen chinesischen Systemen gerechnet, aber China hält sich auffallend zurück. Und von Microsofts auf der Build angekündigtem Supersystem für Azure ist auch weit und breit nichts zu sehen. Das gleiche gilt für die letztes Jahr von Intel vollmundig angekündigten 56-Kern-Module Cooper Lake für HPC (CPL-SP). Vor wenigen Tagen hatte Intel die Roadmap neu geordnet, also alles nach hinten verschoben, dabei aber als Ausgleich eine neue Advanced Matrix Extension AMX angekündigt, vielleicht so etwas ähnliches wie Nvidias Tensor-Engine.
Aus deutscher Sicht hatte man zudem eigentlich mit einem möglichen neuen deutschen Spitzenreiter mit etwa 20 PFlops gerechnet, doch völlig überraschend taucht der im Februar eingeweihte Hawk des HLR Stuttgart mit AMD-Rome-Prozessoren überhaupt nicht in der Liste auf, jedenfalls nicht in der Vorabversion. Hier findet man nur den Vorgänger Hazel Hen, der aber eigentlich schon deinstalliert sein müsste. Hat das HLRS gar nicht gemeldet? Man weiß ja, dass HLRS-Chef Prof. Resch nicht gerade großer Linpack-Fan ist.
… und Verpasstes
Nvidia wollte mit dem Selene vor allem in der Energie-Effizienz und damit in den Green500 ganz oben landen. Mit 20,5 GFlops/Watt sah das auch sehr gut aus, damit konnte man das in speziellen Öltanks eingetauchte japanische Zettascale-System mit Pezy-Beschleunigern (18,6 GFlops/Watt) klar übertrumpfen – doch damit hatte Nvidia die Rechnung ohne einen anderen japanischen Wirt gemacht. Die Firma Preferred Networks hat nämlich einen hocheffizienten Matrix-Beschleuniger MAU entwickelt, der auf PCIe-Karten zusammen mit Low-Power-Xeons auf 21,1 GFlops/Watt kommt und damit knapp vor Nvidia die Green500 anführt. Der Fugaku liegt mit 14,6 GFlops/Watt in dieser Disziplin auf Platz 9.
(Bild: top500.org)
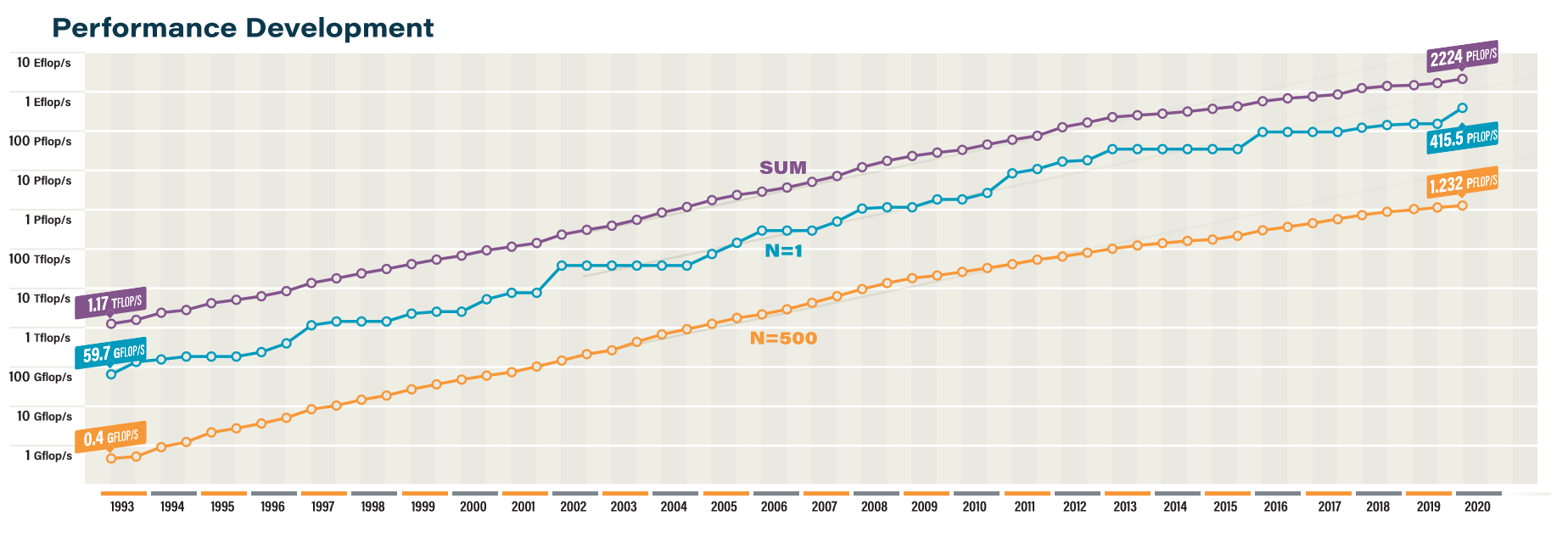
Insgesamt hat China mit 226 (zuvor 228) bei weitem die meisten Systeme in der neuen Liste, vor den USA mit 114 (117) und Japan mit 29 (29). Dahinter kommen Frankreich 19 (18), Deutschland 16 (16) und die Niederlande 15 (15). In Performance ausgedrückt führt weiterhin die USA (639 PFlops) vor China (566 PFlops) und Japan (528 PFlops). Dank der beiden neuen Top10-Systeme und in Abwesenheit des Stuttgarter Hawk hält dann Italien mit 87,2 PFlops die europäische Spitzenposition vor Frankreich (79,9 PFlops) und Deutschland (68,8 PFlops).
Hierzulande gibt es ein einziges neues System, den Lichtenberg II (Phase 1) der TU Darmstadt, der sich mit 3 PFlops und Platz 93 auf der Liste nun schnellster Uni-Rechner Deutschlands nennen kann. Der von Megware aufgebaute Rechner arbeitet mit Xeon Platinum 8260 und Nvidia Tesla V100. Großbritannien hat derzeit offenbar andere Probleme und nur noch zehn Systeme mit insgesamt 31 PFlops in der Liste platziert, kein einziges neues ist dabei.
Hersteller-Supercomputer
Bei den Herstellern dominiert die chinesische Phalanx mit Lenovo (180 Systeme), Sugon (68) und Inspur (64) vor allem mit anonymen Industriesystemen weiterhin. HPE ist mit 38 und die zu HPE gehörende Firma Cray mit 36 Systemen dabei. Fujitsu baute zwar nur 13 Systeme in der Liste, darunter aber den neuen Spitzenreiter Fugaku, und hat daher in installierter Performance mit 478 PFlops klar die Nase vorn vor Lenovo mit 355 PFlops. An die Uni Nagoya in Japan konnte Fujitsu auch gleich ein zweites Primehpc-FX1000-System mit A64FX verkaufen, "Flow" liegt mit rund 6,6 PFlops auf Platz 37.
Insgesamt ist diesmal wieder die Gesamtleistung der Liste deutlich um 35 Prozent auf 2,22 EFlops gestiegen (zuvor waren es nur 5,5 Prozent Anstieg), obwohl nur 58 neue Systeme hinzugekommen sind. Die Mindestleistung, um überhaupt in die Liste zu kommen, beträgt nun 1,23 PFlops auf Platz 500.
| Top10 der 55. Top500-Liste | ||||||||
| Platz (zuvor) | System (Hersteller) | Einrichtung | Land | CPU-Cores | GPU-Cores | Linpack Rmax (PFlops) | Energie-effizienz (GFlops/W) | HPCG (TFlops) |
| 1 (-) | Fukagu (Fujitsu) | Riken | Japan | 152.064 × 48 A64FX 2,2 GHz | 0 | 415,5 | 14,67 | 13.400 |
| 2 (1) | Summit (IBM) | Oak Ridge National Lab | USA | 9.216 × 22 Power9, 3,07 GHz | 27.648 × 80 Tesla V100 | 148,6 | 14,72 | 2925,75 |
| 3 (2) | Sierra (IBM) | Lawrence Livermore National Lab | USA | 8.640 × 22 Power9, 3,1 GHz | 17.280 × 80 Tesla V100 | 94,64 | 12,72 | 1795,67 |
| 4 (3) | Sunway TaihuLight (NRCPC) | National Supercomputing Center in Wuxi | China | 40.960 × 260 ShenWei 26010, 1,45 GHz | 0 | 93,01 | 6,05 | 480,84 |
| 5 (4) | Tianhe-2A (NUDT) | National Supercomputing Center in Guangzhou | China | 35.584 × 12 Xeon E5-2692v2, 2,2 GHz | 35.584 × 128 Matrix 2000 | 61,44 | 3,33 | k.A. |
| 6 (-) | HPC5 (DellEMC) | Eni | Italien | 3.640 × 24 Xeon Gold 6252 | 7280 × 80 Tesla V100 | 35,45 | k.A. | 1.344,19 |
| 7 (-) | Selene | Nvidia | USA | 560 × 64 AMD Epyc 7742, 2,25 GHz | 2240 × 108 Nvidia A100 | 27,58 | 20,5 | k.A. |
| 8 (5) | Frontera (DellEMC) | Texas Advanced Computing Center (TACC) | USA | 16.016 × 28 Xeon Platinum 8280, 2,7 GHz | 0 | 23,52 | k.A. | k.A. |
| 9 (-) | Marconi-100 (IBM) | Cineca | Italien | 1.976 × 16 Power9 | 3952 × 80 Tesla V100 | 21,64 | k.A. | 14,66 |
| 10 (9) | Piz Daint (Cray) | Centro Svizzero di Calculo Scientifico (CSCS) | Schweiz | 5.704 × 12 Xeon E5-2690v3, 2,6 GHz (+2862 × 18 Xeon E5-2695v4) | 5704 × 56 Tesla P100 | 21,2 | 10,4 | 486,39 |
(as)
