

Intel: Rechenbeschleuniger Ponte Vecchio soll Nvidia A100 deklassieren
Mit 45 FP32-Teraflops sollen die riesigen Intel-Kombichips mehr als doppelt so schnell sein wie Nvidia Ampere; auch zu Xeons und SmartNICs gibt es Neuigkeiten.

Bis zu acht Intel-Ponte-Vecchio-Karten kommunizieren via Xe-Link
(Bild: Intel)
Die aus bis zu 47 Silizium-Dies mit insgesamt über 100 Milliarden Transistoren zusammengesetzten Rechenbeschleuniger "Ponte Vecchio" sollen Exaflops-Supercomputer wie Aurora befeuern. Auf einem "Architecture Day" nannte Intel nun weitere Details zu den kommenden Prozessoren und betonte, dass schon frühe Prototypen im Labor über 45 TFlops Rechenleistung bei einfacher (FP32-)Genauigkeit erreichten. Das ist mehr als das Doppelte, was eine Nvidia A100 schafft. Zudem soll Ponte Vecchio bei doppelt genauen FP64-Berechnungen, wie sie der Linpack-Benchmark für Top500-Supercomputer verlangt, ebenso schnell sein wie bei FP32.
Auch zu der mit Ponte Vecchio kommenden Xeon-SP-Generation Sapphire Rapids verriet Intel weitere Details. Zudem kündigte Intel neue SmartNICs für Cloud-Rechenzentren an, also spezielle Netzwerkkarten mit eigenen x86-, FPGA- oder ARM-Rechenwerken, um Server-Instanzen vom Cloud-Unterbau zu entlasten beziehungsweise zu entkoppeln.
Videos by heise
Dies von Intel und TSMC gemischt

(Bild: Intel)
Wie bereits bekannt ist, koppelt Intel für Ponte Vecchio mehrere Dies aus eigener Fertigung und vom Zulieferer TSMC: An das 640 Quadratmillimeter große Base Die koppelt Intel die anderen Dies mit den hauseigenen Verfahren EMIB und Foveros, teils sitzen mehrere Dies übereinander (Stacks). Auch HBM2e-Stapelspeicher ist direkt angebunden.
Anders als bisher erwartet, fertigt Intel die "Compute Tiles" mit je bis zu acht Xe-HPC-Cores und 4 MByte L1-Cache nicht selbst, sondern sie stammen aus der 5-Nanometer-Fertigung von TSMC (N5). Je zwei dieser Compute Tiles bilden ein Xe HPC Compute Slice mit 8 Xe-Cores und 8 MByte L1-Cache. Dazu kommen bis zu 144 MByte L2-Cache auf dem Base Tile, gefertigt mit der 10-Nanometer-Technik "Intel 7".
Weitere Tiles mit TSMC-N7-Technik stellen pro Ponte-Vecchio-Prozessor acht sogenannte Xe-Links bereit. Damit lassen sich bis zu acht Ponte Vecchios direkt miteinander verbinden. Bei den Serverknoten für den Supercomputer Aurora nutzt Intel je sechs Ponte Vecchios, die untereinander mit Xe-Links verbunden sind. An die beiden Sapphire-Rapids-Xeons sind sie per PCIe 5.0 gekoppelt beziehungsweise via Compute Express Link CXL 1.1, der auf PCIe 5.0 aufsetzt.
Xe-Cores für HPC anders als Xe HPG

(Bild: Intel)
Die Xe-HPC-Kerne (HPC steht für High Performance Computing) haben im Prinzip dieselben Vektor-, Matrix- und Raytracing-Recheneinheiten wie die Xe-HPG-Kerne für High Performance Gaming. Doch die Vektor- und Matrix-Engines der HPC-Kerne verarbeiten "breitere" Datenformate, nämlich 512-Bit-Vektoren und 4096-Bit-Matrizen. Ein Xe-HPC-Core enthält je acht Vektor- und Matrix-Engines sowie 512 KByte L1-Cache.
Xeon-SP Sapphire Rapids
Wie bisher schon spekuliert wurde, bestehen die kommenden Sapphire-Rapids-(SPR-)Xeons aus vier Tiles, in denen jeweils mehrere CPU-Kerne vom Typ "Golden Cove" stecken, die auch bei Alder Lake zum Einsatz kommen – allerdings in einer für Server optimierten Version mit mehr L2-Cache. Wie viele Kerne es pro Tile beziehungsweise CPU sein werden, verriet Intel noch nicht. Man munkelt von 56 (14 pro Tile), was weiterhin weniger wäre als bei AMD Epyc 7003 Milan (64) und erst recht weniger als beim 2022 erwarteten AMD Genoa mit 96 oder gar 128 bei Bergamo.
Allerdings verspricht starke Steigerungen der KI-Rechenleistung durch die neuen AMX-Rechenwerke.
Intel bestätigte, dass jede Tile einen Speicher-Controller für zwei DDR5-SDRAM-Kanäle besitzt; es gibt also acht RAM-Kanäle pro CPU, auch für Optane-300-Module. Zudem kommen SPR-Xeons mit angeflanschtem HBM-Stapelspeicher, der sich auch gleichzeitig mit DDR5-RAM nutzen lässt. AMD will bei Genoa aber wohl bis zu 12 RAM-Kanäle anbinden.
PCIe 5.0 mit CXL 1.1 hatte Intel schon mehrfach für SPR hervorgehoben. Doch auch der Ultra Path Interconnect (UPI) wurde beschleunigt; er ermöglicht wie bisher die Kopplung von bis zu acht Prozessoren (Acht-Socket-Server, 8S).
IPU auch mit ARM Neoverse
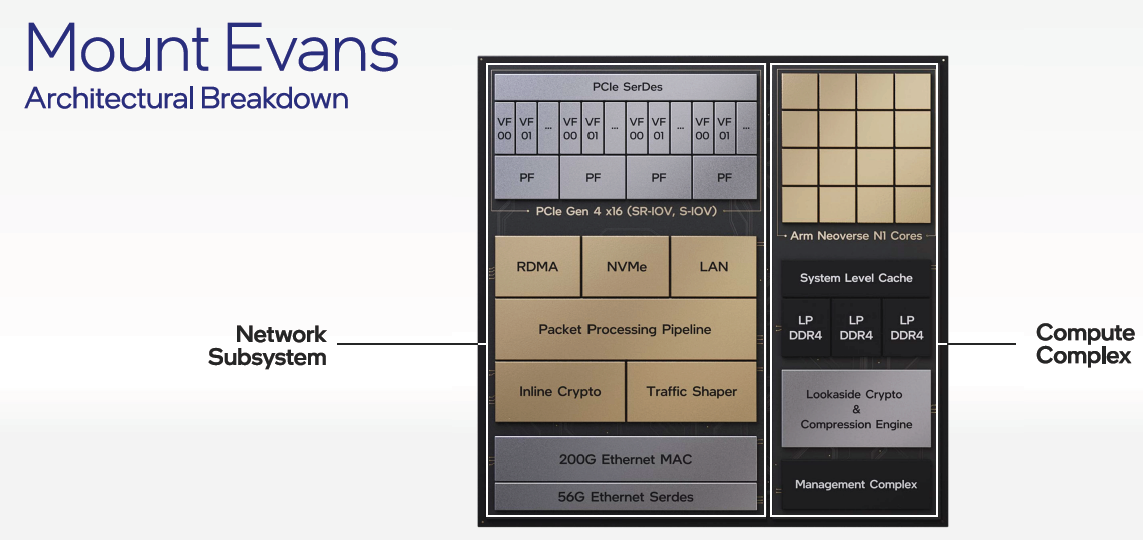
(Bild: Intel)
Vor allem für Cloud-Dienstleister sind SmartNICs beziehungsweise Data Processing Units (DPUs) interessant, die die CPU-Kerne in Servern entlasten und Infrastrukturaufgaben wie Netzwerk, Storage und Verschlüsselung übernehmen. Intel spricht von Infrastructure Processing Units (IPUs) und kündigte drei neue an: Oak Springs Canyon (Agilex-FPGA plus Xeon D), Arrow Creek (Agilex-FPGA und Max10-FPGA) sowie Mount Evans. Letztere soll auch Ethernet mit 200 GBit/s bewältigen und enthält 16 ARM-Kerne vom Type Neoverse N1.


(ciw)
