

GPT-3 überflügeln: Quellcode des KI-Modells MAGMA steht auf GitHub
Aleph Alpha stellt wesentliche Teile des multimodalen KI-Modells der Community zur Verfügung – MAGMA kann Bilder und Text in beliebiger Kombination verarbeiten.
(Bild: Aleph Alpha)
- Silke Hahn
Aleph Alpha stellt die Codebasis seines KI-Modells MAGMA ab sofort auf GitHub als Open Source bereit. Das Team des deutschen Machine-Learning-Unternehmens Aleph Alpha mit Sitz in Heidelberg und Berlin hatte gemeinsam mit Forscherinnen der Universität Heidelberg das Modell mit rund 7 Milliarden Parametern trainiert. Es ist Transformermodellen wie GPT-3 ähnlich, geht als Vision-Language-Modell mit multimodalen Fähigkeiten jedoch über das Sprachmodell von OpenAI hinaus und versteht laut seinen Herausgebern potenziell jegliche Kombination von Text und Bild. Optional lässt es sich weiterhin auch als reines Sprachmodell einsetzen, seine Sprache ist Englisch.
Laut dem Firmengründer und KIT-Ingenieur Jonas Andrulis ist das Open-Source-Release vom Umfang her ideal für visuelles Q&A sowie Standard-Captioning-Aufgaben, da es kein "gigantisch großes Cluster" zum Betreiben braucht. Auf den Fähigkeiten des Forschungsmodells MAGMA bauen auch die 200 Milliarden großen Modelle auf, die er und sein Team mehrsprachig trainiert haben (in den fünf europäischen Sprachen Englisch, Deutsch, Französisch, Spanisch und Italienisch). Die großen Modelle sitzen bei Aleph Alpha hinter der API im Playground, und das Open-Source-Release entspricht dem kompakteren Forschungsmodell der Heidelberger.
Großes Sprachmodell, das auch Bilder versteht
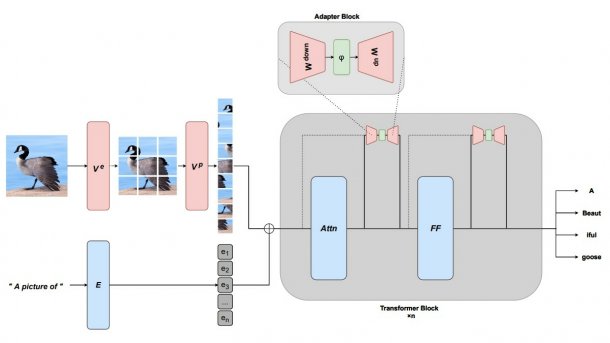
Aleph Alpha hat eine Methode entwickelt, um generierende Sprachmodelle durch adapterbasiertes Feintuning um zusätzliche Modalitäten wie die Bilderkennung zu erweitern. MAGMA steht für "Multimodal Augmentation of Generative Models through Adapter-based Finetuning" – im Kern handelt es sich um selbstüberwachtes Lernen von Repräsentationen nach dem Transformer-Modell. Das Team von Aleph Alpha machte sich den Ansatz des "Einfrierens" von Sprachmodellen zunutze (gemeint ist das "Multimodal few-shot learning with frozen language models", kurz: Frozen). Anders als Frozen hat MAGMA eine Reihe zusätzlicher Adapter-Layer erhalten, und als Encoder kommt die visuelle Komponente von CLIP zum Einsatz (einem von OpenAI Anfang 2021 vorgestellten Modell, das frei Bilder zu Textbeschreibungen entwirft).

Ein Vortrainieren (Pretraining) im großen Stil gilt zunehmend als die Norm für das Modellieren großer Vision-Language-Modelle (VL). Allerdings stößt die herkömmliche Methode des Daten-Labelns im mehrstufigen Trainingsverfahren bei neuronalen Netzen mit wachsendem Umfang der Modelle an Grenzen. Hinsichtlich der Performance soll das VL-Modell MAGMA mit hoher Treffsicherheit punkten, dabei eine deutlich geringere Menge an gesampelten Daten für das Training benötigt haben als SimVLM ("Simple visual language model pretraining with weak supervision") – MAGMA benötigte laut Team nur 0,2 Prozent der für SimVLM eingesetzten Menge an Beispieldaten. Einem gängigen Benchmarkvergleich zufolge stellt das in Python geschriebene VL-Modell wohl auch den Vorgänger Frozen in den Schatten. Ein auf arXiv.org veröffentlichtes Paper des Aleph-Alpha-Teams erläutert die Funktionsweise von MAGMA und präsentiert die Vergleichswerte (die Peer Review steht noch aus).

(Bild: Aleph Alpha)
Multimodales Modell herunterladen und adaptieren
Wer MAGMA ausprobieren oder für eigene Zwecke abwandeln möchte, findet im GitHub-Repository von Aleph Alpha den Code samt einer Anleitung zur Installation. Vorab müssen PyTorch und Torchvision installiert sein, mit dem Befehl pip install -r requirements.txt lassen sich die darüber hinaus notwendigen Elemente installieren. Developer haben die Wahl zwischen den vortrainierten Weights von CLIP (als Default greifbar) oder denen von GPT-J. Zum Trainieren von MAGMA empfiehlt das Team den Weg über Deepspeed, und zwar mit folgendem Befehl: deepspeed train.py --config path_to_my_config.
Das Open-Source-Release eröffnet laut seinem Herausgeber die nächste Stufe der KI-Entwicklung nach GPT-3 und könnte zudem durch die zusätzlichen Fähigkeiten (Multimodalität) und die nun erfolgte Offenlegung des Codes dazu beitragen, dass sich europäische Alternativen zu dem Produkt von OpenAI etablieren. Weiterführende Informationen zu MAGMA und den darauf aufbauenden größeren Modellen lassen sich auch der Website von Aleph Alpha entnehmen.
[Update-Hinweis vom 18.03.2022: Differenzierung im zweiten und im letzten Absatz – das hier besprochene Open-Source-Release ist das 7 Milliarden Parameter große englischsprachige Forschungsmodell MAGMA. Die 200 Milliarden Parameter großen mehrsprachigen Modelle sitzen bei Aleph Alpha hinter der API im Playground, auch sie verfügen über MAGMA-Funktionalität.]
Videos by heise
(sih)