
Cloud-Datenbank YugabyteDB 2.13 mit verbesserter Geo-Replikation
Die neue Version von YugaByteDB soll Entwicklern durch etliche neue Features, darunter die Integration in einige Werkzeuge, die Arbeit spürbar erleichtern.
- Martin Gerhard Loschwitz
Die verteilte Datenbank Yugabyte ist in Version 2.13 erschienen. Diese bringt neben verbesserten Konfigurationsmöglichkeiten bei der Geo-Replikation auch eine eigene, web-basierte Shell für den direkten Zugriff auf Yugabyte, eine Integration in HashiCorp Vault sowie eine Zertifizierung nach SOC 2 Typ 1.
Folgt eine Anwendung dem Cloud-Native-Prinzip und besteht aus vielen kleinen Mikrokomponenten, sehen ihre Entwickler sich regelmäßig einem Problem gegenüber: Zwar wollen sie die Daten ihrer Anwendung wie in konventionellen Umgebungen üblich auch in einer Datenbank speichern, doch finden sich am Markt kaum Datenbanken, die für cloud-native Architekturen ausgelegt sind. MariaDB, PostgreSQL & Co. sind ab Werk nicht für implizite Replikation geeignet. Mit Lösungen wie Galera für MySQL lassen sich diverse Features zwar nachrüsten, aufgrund der Architektur der eigentlichen Datenbank gehen Administratoren und Entwickler dabei jedoch regelmäßig unschöne Kompromisse ein – die im Falle eines Falles sogar die Integrität der Daten negativ beeinflussen.
Mehrere Anbieter am Markt treten mittlerweile allerdings mit Datenbanken auf, die zu konventionellen Datenbanken einerseits kompatibel sein wollen, dabei den Ansprüchen der cloud-native-Welt aber gerecht werden. Citus Data etwa wirbt mit grenzenlos skalierbarem PostgreSQL, und in ein ähnliches Horn stößt Yugabyte: Die Datenbank bezeichnet sich nicht nur hochtrabend als "erste echte Datenbank für cloud-native Umgebungen", sondern erweitert ihr Featureset regelmäßig auch in Form neuer Releases. Die Version 2.13 bringt mehrere Verbesserungen, die laut Hersteller für Entwickler von zentraler Bedeutung sind.
Wie Yugabyte funktioniert
Vereinfacht dargestellt funktioniert YugabyteDB, indem es zunächst die Schicht des Zugriffs auf die Datenbank von der Schicht, die Daten speichert, trennt. Unter der Haube werkelt die "DocDB", die im Kern auf Facebooks RocksDB auf den einzelnen (virtuellen) Knoten eines YugabyteDB-Clusters fußt. Hinter den Kulissen werkelt bei YugabyteDB mithin ein hochperformanter Key-Value-Store.


Wie sich Yugabyte in der Praxis im Verleich zu konventionellen Datenbanken schlägt, zeigt ein aktueller iX-Test auf heise+. Der Artikel entstammt dem kommenden Mai-Heft – alle Informationen zur iX 5/2022 vorab gibt's im kostenlosen Newsletter.
Hinzu gesellt sich ein Cluster-Manager, der den RAFT-Algorithmus zur Replikation nutzt und die Daten nach dem Sharding-Prinzip aufteilt. Jede Tabellenzeile bildet dabei einen Shard ("Tablet" im YugabyteDB-Sprech), für den es einen clusterweiten Leader und beliebig viele Follower gibt. Erfolgreiche Schreibvorgänge bestätigt Yugabyte, sobald ein Write es auf hinreichend vielen Knoten in das dortige Write-Ahead-Log der DocDB geschafft hat. Den Zugriff auf die Daten realisiert YugabyteDB über eine Abstraktionsschicht, die sowohl den größten Teil der PostgreSQL-Befehle beherrscht, als auch die Protokolle von RedisDB sowie Cassandra.
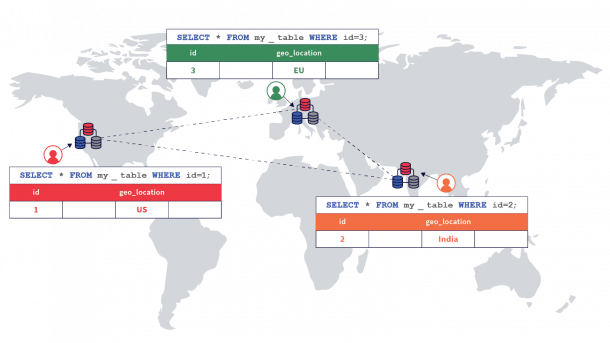
Eine zentrale Neuerung in Yugabyte DB 2.13 sind Performance-Verbesserungen bei den sogenannten "regional-lokalen" Transaktionen. Hinter dem sperrigen Begriff verbirgt sich die in YugabyteDB bereits angelegte Möglichkeit, einzelne Tabellenzeilen im Datensatz so zu konfigurieren, dass sie lediglich in regionalen Teilclustern von YugabyteDB abgelegt sind. Wer sich mit Storage-Systemen schonmal näher befasst hat, kennt das Problem: "Stretched" Cluster, bei denen ein ganzer Cluster über mehrere Regionen gespannt ist, liefern miserable Latenzzeiten beim schreibenden Zugriff, wenn dieser synchron erfolgt. Schließlich müssen die Daten dann bei jedem Zugriff die Grenzen zwischen den Regionen überwinden.
Latenz wird zum Problem
Was nicht dramatisch klingt, wird zum riesigen Problem, wenn die Latenz zwischen den Standorten auch nur wenige Millisekunden beträgt; denn jeder schreibende Zugriff verzögert sich dann um die gesamte Zeit, die für das Hin- und Herkopieren von Daten notwendig ist. Yugabyte ermöglicht das Bauen solcher gestreckten Cluster, bietet aber die Option, einzelne Datensätze darin auf Regionen zu beschränken. So soll nicht nur im Sinne etwa der DSGVO sichergestellt sein, dass Daten physisch nicht dorthin abwandern, wo sie nicht sein dürfen – der Hersteller versucht auf diesem Wege auch, das Handling der Datenbank aus Entwicklersicht so einfach wie möglich zu machen, gleichzeitig aber Replikation zu ermöglichen. Falls Datensicherheit etwa für Disaster-Recovery-Zwecke über die Grenzen eines Standorts doch gewünscht ist, lassen sich die Daten obendrein asynchron implementieren ("xCluster replication").
YugabyteDB 2.13 führt für Daten, die als Teil eines globalen Clusters lokal zwischen mehreren Instanzen synchron repliziert werden ("regionallokale Replikation") ein verbessertes Metadatenhandling ein. Mittels der obendrein neuen "Materialized Views" speichern Entwickler eine Art Schablone für den Zugriff auf Daten, deren Daten YugabyteDB dann im Vorlauf hält und deutlich schneller ausliefern kann, wenn eine entsprechende Abfrage stattfindet. Last but not least lassen sich Backups in YugabyteDB 2.13 nun so konfigurieren, dass die Daten geografisch definierte Regionen nicht verlassen, was besonders der Compliance dient.
Videos by heise
Mehr Integrationen für Entwickler
Für eine Lösung aus dem cloud-ready-Umfeld ist die Integration in andere Dienste aus diesem Dunstkreis von zentraler Bedeutung. YugabyteDB 2.13 geht hier forsch voran und stellt ein neues Werkzeug namens "Cloud Shell" vor. Die ist besonders im Kontext der Entwicklung relevant: Bis dato mussten Entwickler nämlich einen Client für YugabyteDB selbst implementieren und mit Queries füttern, um die passende Abfrage für eine Anwendung zu generieren. Die Cloud Shell hilft ihnen künftig, diesen Prozess angenehmer zu gestalten: Sie ist per Web-GUI zugänglich und funktioniert wie die nativen Clients für PostgreSQL, Cassandra und Redis auch, bietet im Gegensatz zu diesen aber eben eine Webschnittstelle für den schnellen Zugriff.
Obendrein bringt YugabyteDB 2.13 auch mehrere Neuerungen im Hinblick auf das Thema Security mit. Passwörter lassen sich dank einer nativen Integration künftig in HashiCorp Vault ablegen. Die Anbindung an das Tracing-Werkzeug Imperva Cloud Data erleichtert es Admins zudem, den Fluss von Daten in YugabyteDB nachzustellen, zu verfolgen und in Form eines Reports für Audits darzustellen.
YugabyteDB 2.13 ausprobieren
Wer YugabyteDB 2.13 ausprobieren möchte, findet die Open-Source-Software ab sofort auf ihrer Website. Obendrein besteht die Möglichkeit, YugabyteDB als gehosteten Dienst direkt von Yugabyte auszuprobieren.


(ur)
