

540 Milliarden Parameter: Googles KI-System kann Arithmetik und erkennt Humor
PaLM bringt einen Qualitätssprung für große KI-Sprachmodelle: Es kann Code generieren, mit Arithmetik umgehen und Witze erklären. Google spricht von Durchbruch.

(Bild: Shutterstock/Wit Olszewski)
- Silke Hahn
Vor einem Monat hatte der New Yorker Hirnforscher und Machine Learner Gary Marcus in einem Essay bekundet, dass Deep Learning sich in einer Sackgasse befinde (im flankierenden Tweet hielt er fest: "Deep Learning is hitting a wall" und löste damit eine Debatte aus). Die Frage, ob KI-Sprachmodelle durch das weitere Skalieren zu immer größeren neuronalen Netzwerken im Milliarden-Parameter-Bereich auch bedeutend an Fähigkeiten hinzugewinnen und ob zunehmende Masse (aber auch Qualität) an Trainingsdaten sie beispielsweise von reiner Mustererkennung – nach Art der sprichwörtlichen "stochastischen Papageien" – zu etwas wie "Reasoning" und tieferem Sprach- und Weltverständnis führt, spaltet die Fachwelt: Die Fähigkeiten großer Sprachmodelle wie GPT-3 von OpenAI sind durchaus beeindruckend. Eine Reihe von Fachleuten hält starke KI (Artificial General Intelligence, kurz: AGI) mit potenziell übermenschlicher Intelligenz durchaus für möglich, während andere das für Humbug und grundsätzlich ausgeschlossen halten.
(Bild: Google)
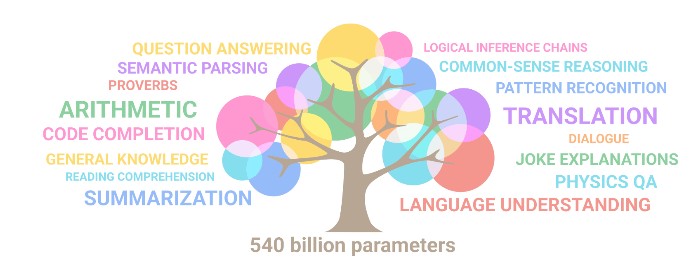
Dass der Plafond noch nicht erreicht ist und zumindest die Technik des Deep Learning noch Luft nach oben hat, zeigt eindrucksvoll das Pathways Language Model (PaLM), das neue große Sprachmodell von Google. PaLM beziehungsweise salopp "540B" umfasst 540 Milliarden ("Billion") Parameter und ist ein Transformer-Modell, das neben den von großen Sprachmodellen bekannten Fertigkeiten im Verarbeiten natürlicher Sprache (Sprachverständnis und Generieren von Text) mit einigen neuen Fähigkeiten glänzt, besonders in der Arithmetik und im Erkennen von Humor. Laut Team erreicht PaLM herausragende Leistungswerte in einem breiten Spektrum von Anwendungen des Natural Language Processing (NLP), im logischen Schlussfolgern (Reasoning) und in Programmieraufgaben (Coding).
Mehrstufige logische Inferenz und Gedankenketten
PaLM generiert explizite Erklärungen für komplexere Szenarios, die mehrstufige logische Inferenz erfordern, es scheint über ein tiefes Sprachverständnis und bis zu einem gewissen Grad über "Weltwissen" zu verfügen. So kann es Witze als solche erkennen und liefert zudem hochwertige Erklärungen zu neu erfundenen Witzen, die nicht in seinem Trainingsdatensatz oder im Netz vorhanden waren. Das Modell soll zwischen Ursache und Wirkung unterscheiden und Konzepte sowie Kontext verstehen können. Das Google-Team hatte PaLM "hochwertige" Webdokumenten, Bücher, Wikipedia, frei zugängliche Konversationen (Chats) aus dem Internet und GitHub-Code als Trainingsdaten zugeführt. Aus Sicht des Teams war auch wichtig, dass Zahlen in individuelle Token aufgelöst wurden und Unicode-Zeichen jenseits des vorhandenen Vokabulars übersetzten sie in Bytecode, um ein "verlustfreies" Vokabular zu erzeugen.
Videos by heise
Als Durchbruch im Bereich "Reasoning" hebt das Team im Blogeintrag hervor, dass PaLM auf Input-Prompts mit Output in Form von Gedankenketten reagiert (Chain-of-Thought-Prompting). So antwortet das Modell beispielsweise auf Textrechenaufgaben, indem es die Aufgabe Schritt für Schritt durchgeht und Zwischenergebnisse notiert. Das Team hatte PaLM unter anderem mit drei arithmetischen Datensätzen und zwei "Commonsense-Reasoning"-Datensätzen getestet, auf denen es teils beachtliche Leistungen zeigte. Sein Score nähert sich mit 58-prozentiger Erfolgsquote im Benchmark-Satz GSM8K den durchschnittlich 60 Prozent an Problemlösekönnen von 9- bis 12jährigen Kindern, wie mit Blick auf diesen Datensatz aus Schulmatheaufgaben festzustellen ist.

(Bild: Google)
Stark auch im Coding
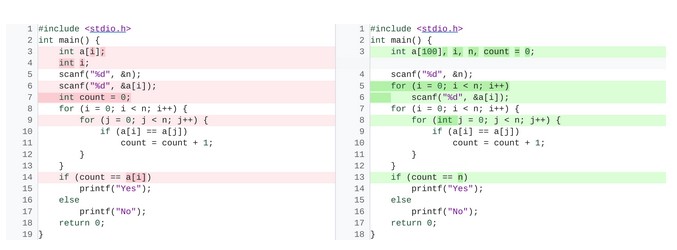
PaLM zeigt offenbar eine bemerkenswerte Coding-Performance im Umwandeln natürlicher Sprache zu Programmcode (text-to-code), im Übersetzen von Code zwischen mehreren Programmiersprachen und im Reparieren von Kompilierfehlern (code-to-code). Das ist insofern erstaunlich, als lediglich 5 Prozent seines Pre-Training-Datensatzes Code enthielten. PaLM gilt von den Performancewerten her als gleichauf mit dem Spezialmodell Codex, das explizit für Coding-Aufgaben und Pair-Programming gemacht ist.

(Bild: Google)
Codex umfasst 12 Milliarden Parameter und hatte beim Training beispielsweise etwa fünfzigmal soviel Python-Code "zu Gesicht bekommen" wie PaLM, weshalb dessen Coding-Performance durchaus eine Überraschung darstellte für das Google-Team. Beim Reparieren defekter Programme in der Sprache C soll PaLM die Programme mit einer 82-prozentigen Erfolgsquote wiederhergestellt haben, was weit über den bislang erreichten rund 72 Prozent liegt, die als State of the Art gelten (als Vergleich diente hier DeepFix).
(Bild: Google)
Unter der Haube: neuartige TPU-Architektur und Pathways
PaLM ist nach dem Pathway-System von Google auf einem TPU-basierten System trainiert. Tensorprozessoren (Tensor Processing Units, kurz: TPU) sind anwendungsspezifische Chips zum Beschleunigen von Anwendungen im Machine Learning, die zahlreiche Datenflüsse parallel verarbeiten können und durch ihre Architektur die Verarbeitungsgeschwindigkeit erhöhen. Google hatte sie 2016 für die hauseigene Softwaresammlung TensorFlow entworfen, und die Hardwareentwicklung befindet sich mittlerweile in der vierten Generation (TPU v4 von 2021). Das Skalieren auf die Größe von 540 Milliarden Parameter und 780 Milliarden Token verdankt das System laut Team der Beschleunigung und Parallelisierung von Datenflüssen durch die TPU-Chips.
Eine Besonderheit hebt das Google-Team hervor: Das Modell soll auch deutlich weniger Energie für seinen Betrieb benötigen als vergleichbare große Modelle bisher, da es "sparsely activated" wird. Das bedeutet, dass zum Erfüllen einer Aufgabe nicht stets das gesamte Netzwerk aktiv wird. Ähnlich wie beim menschlichen Gehirn aktiviert PaLM jeweils kleine Pfade (Pathways) durch das neuronale Netz, die nur bei Bedarf in Aktion treten. Das Modell soll dynamisch lernen, welche Teile seines Netzes für welche Art von Aufgabe geeignet sind, und greift dann jeweils gezielt auf die als relevant erkannten Bereiche zu. Dadurch lässt sich laut Google-Team die Verarbeitung beschleunigen und der Energiebedarf sinkt.
FLOPs als Vergleichsgröße für Hardware im Machine Learning
Für PaLM kamen laut Blogeintrag 6144 Chips der Bauart TPU v4 zum Einsatz, das bislang größte Trainingssystem bei Google. Vorgängermodelle wie GLaM, LaMDA, das Megatron-Turing-Modell oder Gopher waren teils noch auf herkömmlichen Grafikprozessoren (GPU) bis hin zu maximal rund 4000 Chips der vormaligen Generation TPU v3 trainiert. PaLM glänzt laut Blogankündigung mit einer "State-of-the-Art"-Performance (SOTA) in den meisten im Machine Learning üblichen Vergleichswerten. Seine Trainingseffizienz liegt bei 57,8 Prozent der FLOP-Hardwareausnutzung, was zurzeit laut Google-Team der höchste gemessene Wert für große Sprachmodelle (Large Language Models, kurz: LLM) dieser Größenordnung ist.
Zum Vergleich: GPT-3 lag hier bei 55 Prozent. FLOP steht für Floating Point Operations Per Second und bezeichnet eine Maßeinheit für die Geschwindigkeit von Computern und Prozessoren. Sie bezeichnet die Anzahl an Gleitkommazahl-Operationen, die sich pro Sekunde durchführen lassen, und durch FLOPs lassen sich unter anderem die Leistungen verschiedener Prozessoren vergleichen. Abschließend lässt sich festhalten, dass das KI-Team von Google mit PaLM seiner Vision eines generalisierenden KI-Systems für Abertausende unterschiedlicher Aufgaben ein gutes Stück näher gekommen ist. Perspektivisch arbeiten mehrere Anbieter zurzeit am Entwickeln großer Modelle, die unterschiedliche Arten von Daten (Multimodalität) und unterschiedlichste Aufgaben aus einem einzigen System heraus bewältigen können. Eine multimodale Revolution ist bereits in Gang, so scheint es.

Weitere Informationen zum Pathways Language Model "PaLM" und zur Architektur des zugrundeliegenden Pathway-Systems lassen sich dem Blogartikel zur Veröffentlichung des Sprachmodells und einem Fachartikel des Google-Teams bei arXiv.org entnehmen ("Pathways: Asynchronous Distributed Dataflow for ML").
(sih)