
DeepMind stellt neuen KI-Agenten vor: den Multitasker und Generalisten Gato
Der KI-Agent von DeepMind kann Atari spielen, Textanweisungen befolgen, Bilder beschriften, chatten und einen Roboterarm kontrollieren – aus einem Transformer.

(Bild: Ociacia / Shutterstock.com)
- Silke Hahn
Zurzeit treten im Deep Learning größere Neuerungen schon gestaffelt zutage: So hat DeepMind, die KI-Forschungsabteilung von Google, nach dem 540-Milliarden-Parameter-Modell PaLM und unmittelbar nach einer neuen Visual-Language-Modellfamilie (VLM Flamingo) nun Gato vorgestellt und verweilt bei der Namensgebung nach Flamingo und Chinchilla im Tierreich: Gato heißt Katze.
Der neue KI-Agent beherrscht laut Forschungsteam ein Multitasking über Mediengrenzen hinweg, also die multimodale Verarbeitung unter anderem von Text und Bild. Dabei unterstützt ihn multiples Embodiment (zu Deutsch etwa "Verkörperung im Raum") – eine Fähigkeit, die in der Virtual-Reality-Forschung und in der Robotik eine Rolle spielt durch räumliche Sensorik, die physische Präsenz mit den dazugehörigen Sinneswahrnehmungen ansatzweise simuliert. Der von seinen Herausgebern als Generalist bezeichnete KI-Agent basiert auf den aktuellen Fortschritten bei der Sprachmodellierung großer Transformermodelle.


Am 2. und 3. Juni findet die Minds Mastering Machines 2022 wieder vor Ort statt – diesmal in Karlsruhe. Die Machine-Learning-Konferenz von Heise hat einen technischen Schwerpunkt und wendet sich an Fachleute, die ML-Projekte in die technische Realität umsetzen: Data Scientists, Softwareentwickler, Softwarearchitektinnen, Projekt- und Teamleiter.
Zwei Tage, drei Tracks: viel Praxis am Puls der KI-Zeit – in Person
Zwei prominente Keynotes sind geplant: Frank Kraemer von IBM berichet über aktuelle Entwicklungen für autonomes Fahren, und Jonas Andrulis, CEO von Aleph Alpha, über Deep-Learning-Weltmodelle und deren neueste Fähigkeiten frisch aus dem Forschungslabor für die Anwendung unter anderem in der Industrie. Erfahrungsberichte stehen im Zentrum, aktuelle ML-Themen wie Symbolic Reasoning, Sentence Embeddings, Kausale Inferenz, Data Mesh und Knowledge Destillation auf dem Plan – alle Tracks finden sich im Programm:
- Continuous Integration für ML – Praxisbeispiel
- Interaktive Datenverarbeitung
- Deployment von ML
- Data Poisoning: Risiken für ML-Anwendungen minieren
- Bildbasierte Betrugsprävention
- ML und Rechtsfragen
Tickets kosten 980 Euro (alle Preise zzgl. MwSt.). Die Workshops "Einführung in das Reinforcement Learning", "Anomalieerkennung und Zeitreihen" sowie "MLOps mit Python und TensorFlow" kosten jeweils 495 Euro, und es gibt vergünstigte Kombitickets.
Multitasking mit Aktionsradius im Raum
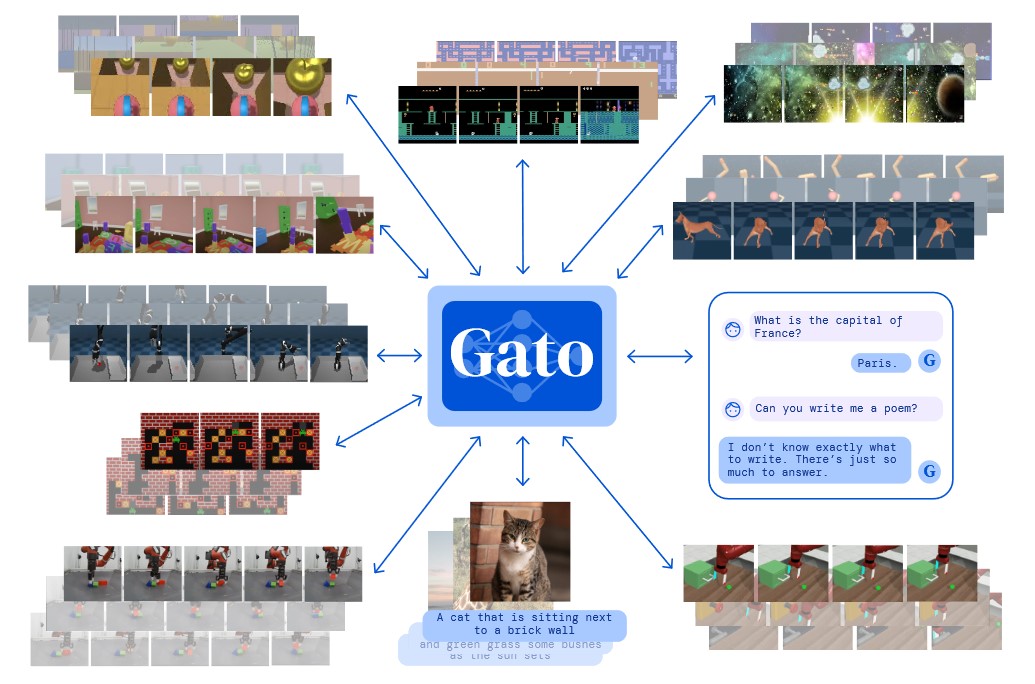
Dabei soll die eierlegende KI-Wollmilchkatze laut flankierend veröffentlichtem Forschungsbericht auf einem einzigen, einheitlich gewichteten Transformermodell aufsetzen. Das zugrundeliegende neuronale Netzwerk vermag demzufolge mehr, als reine Textaufgaben zu lösen: Es soll auch Bilder beschriften (Image Captioning), physische Blöcke mit einem Roboterarm stapeln und Atari spielen können. Je nach Kontext entscheidet es offenbar eigenständig, welche Tokens es ausgibt: Text, Drehmomente für Gelenke (joint torques), Tastendruck oder eine andere Variante des Outputs im Rahmen seiner vergleichsweise umfangreichen Möglichkeiten.
Videos by heise
Agent Gato: Trainingsansätze für größere Geschmeidigkeit
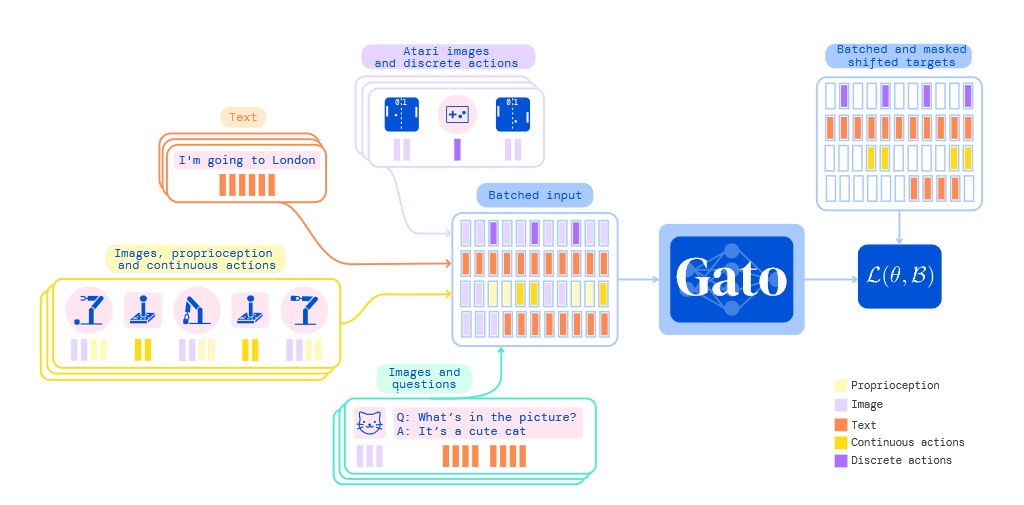
Das DeepMind-Team hat Gato in der Trainingsphase mit Daten unterschiedlicher Aufgaben und Modalitäten (wie Text und Bild, aber wohl auch sensorischem Input) in einer flachen Sequenz von Tokens serialisiert, als Batch gestapelt und in einem durch ein neuronales Transformernetzwerk ähnlich verarbeitet, wie es von großen KI-Sprachmodellen bekannt ist. Bei dem Verfahren maskierten Machine-Learning-Ingenieure den Schwund (Loss-Funktion) und trainierten das Modell dahingehend, dass es nur Handlungs- und Textziele vorhersagt. Zurzeit beruhen die bekannten Transformermodelle auf dem Ansatz der Predictions (Vorhersagen), indem sie bei einer Eingabeaufforderung (Prompt) aus ihrem Datensatz und den gelernten Verknüpfungen die wahrscheinlichsten Antworten berechnen und als Antwort ausgeben.
(Bild: Google DeepMind)
Agent Gato soll laut dem zwanzigköpfigen Forschungsteam einen größeren Handlungsspielraum besitzen als GPT-3- oder DALL-E-artige Modelle, indem es nicht nur Text und Bild verarbeitet, sondern auch räumliche Aktionsimpulse für einen Roboterarm in Tokenform ausgeben kann, je nach Eingabe und Kontext. Dabei soll der generalistische Agent durch eine Vielzahl verschiedener Embodiments "spüren" (sense) und handeln können (act). Im Training hatte Gato 604 spezifische Aufgaben zu lösen, die mit variierenden Modalitäten, Beobachtungen und Aktionen einhergingen.
(Bild: Google DeepMind)

Diskussion auf Twitter und weiterführende Ressourcen
Über den genauen Hergang des Trainings informiert der Forschungsbericht des DeepMind-Teams, das an Gato gearbeitet hatte. Die Neuigkeit teilten die Forscherinnen und Forscher von DeepMind zuerst auf Twitter, wo Gato von der Machine-Learning-Community bereits mit regem Interesse aufgenommen wird. Diskussionen über mögliche Implikationen für allgemeinere Künstliche Intelligenz (AGI) aus dem Deep Learning heraus sind in Gange:
Eine vollständige PDF-Version des Gato-Papers steht auf der Storage-Website von Google bereit.
Forschung für Perceptual und Embodied AI
Im Bereich Perceptual AI hatte sich Ende April 2022 jenseits von Google bereits etwas getan: Das Allen Institute for AI hatte Continuous Scene Representations (CSR) for Embodied AI vorgestellt, einen neuen Ansatz für KI-Agenten mit räumlicher Wahrnehmung (Embodied Agents). Der Quellcode zu dem Projekt ist auf GitHub im AllenAI-Repository zu finden, und bei ArXiv.org lässt sich der Forschungsbericht nachlesen. Das Team von Allen AI stellt ergänzendes Videomaterial bereit, das das Konzept der kontinuierlichen Repräsentation dreidimensionaler Szenen für KI-Agenten in der Embodied-AI-Forschung vorführt.
(sih)