

Fotorealistische KI-Bildsynthese: Google macht DALL·E 2 Konkurrenz – mit Imagen
Nach OpenAI schickt auch Google ein neues KI-System ins Rennen, das mit tiefem Sprachverständnis durch Text-zu-Bild-Synthese fotorealistische Bilder erzeugt.

"An Alpaca is smiling and under water in a swimming pool." #imagen
(Bild: Zoubin Ghahramani)
- Silke Hahn
Der im Frühjahr 2022 begonnene Space Race neuer großer KI-Modelle von Google, Meta und OpenAI setzt sich beschleunigt fort: Rund vier Wochen nach der Veröffentlichung des KI-Bildgenerators DALL·E 2 durch OpenAI legt Google nach und stellt Imagen vor, ein Text-zu-Bild-Diffusionsmodell mit tiefem Sprachverständnis, das aus Textvorgaben fotorealistische Bilder generiert. Zum jetzigen Zeitpunkt veröffentlicht das Google-Brains-Team allerdings weder den Code noch eine öffentliche Demoversion des Modells, was die am Projekt beteiligten Forscherinnen und Forscher in einem längeren Abschnitt ihres Berichts mit ethischen Bedenken begründen.
Zum Vergleich: OpenAI hatte eine Demoversion von DALL·E 2 ausgewählten Testnutzern zugänglich gemacht und erst vor Kurzem den Nutzerkreis sogar erweitert. Allerdings gibt auch OpenAI den Code nicht preis und behält sich vor, die an zahlreiche Bedingungen und Auflagen geknüpfte Nutzung jederzeit wieder einzuschränken. Die mit DALL·E 2 erzeugten Bilder gehören nicht denen, die sie erstellt haben, und eine kommerzielle Nutzung beispielsweise für NFTs hatte OpenAI von Vorneherein ebenso ausgeschlossen wie das Erstellen fotorealistischer Bilder lebender Menschen oder eine Verwendung für Pornografie und die Darstellung von Gewalt.
Imagen untermauert bisherige Text- und Bildansätze
Technisch stecken in dem neuen KI-System von Google zwei Grundideen: Imagen baut laut Google-Brains-Team für das Verarbeiten von Text auf großen Transformer-Sprachmodellen auf und stützt sich für das Erzeugen realistisch wirkender Bilder auf den Ansatz von Diffusionsmodellen. Dass sich generische große Sprachmodelle (Large Language Models, kurz: LLM), die auf großen Mengen reiner Textdaten vortrainiert sind, beim Kodieren von Text für die Bildsynthese als erstaunlich leistungsfähig erweisen, darf mittlerweile als erwiesen gelten – auch die Google-Forscherinnen und -Forscher kommen in ihrem Paper zu diesem Schluss und können ihn mit ihren Ergebnissen weiter untermauern.
Videos by heise
Im Kern nutzt Imagen für die Visualisierung einen großen, "eingefrorenen" T5-XXL-Encoder zum Kodieren von Texteingaben. Ein Diffusionsmodell bildet die numerische Texteinbettung jeweils auf ein Bild in niedriger Auflösung ab (64 mal 64 Pixel). Zudem verwendet Imagen textbedingte (text-conditional) hochauflösende Diffusionsmodelle, um die Bilder von der Grundgröße auf 256 mal 256 sowie auf 1024 mal 1024 Pixel hochzurechnen, was der Auflösung bei DALL·E 2 entspricht. Von Diffusionsmodellen ist die Rede bei Machine-Learning-Modellen, die während des Trainings mit Bildern gespeist werden, die zunehmend verrauscht sind (noisy). Nach abgeschlossenem Training vermögen sie auch, den Prozess umzukehren, also aus dem Rauschen (Noise) vernünftige Bilder herzustellen.

(Bild: Google Research)
Hochskalieren des Sprachmodells steigert die Leistung
Interessanterweise habe laut Paper des Google-Teams eine Vergrößerung des Sprachmodells in Imagen sowohl die Sample-Treue als auch das Alignment von Bild und Text stärker gesteigert als eine Vergrößerung des Bild-Diffusionsmodells. Mit Alignment ist hier die Abstimmung und das aufeinander Ausrichten von Texteingaben und Bildausgaben zu stimmigen Ergebnissen gemeint, bei denen der Output sich möglichst weitreichend mit der in Textform eingegebenen Zielvorgabe deckt.
(Bild: Google Research)
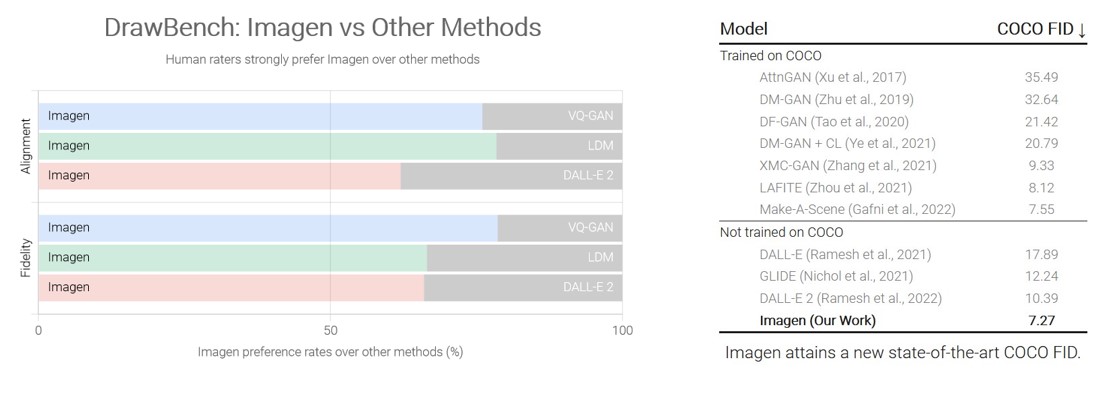
Die Leistungsfähigkeit von Modellen wird oft an der Performance auf Vergleichsdatensätzen mittels Standard-Benchmarks gemessen. So verweisen die Forscherinnen und Forscher auf den COCO-Datensatz (Common Object in Context), bei dem Imagen einen vergleichsweise hohen Score erreicht, ohne zuvor auf diesen Daten trainiert worden zu sein, während menschliche Tester offenbar fanden, dass die Imagen-Beispiele beim Bild-Text-Abgleich mit COCO gleichauf liegen. Das Google-Brains-Team hat Imagen mit neueren Methoden wie VQ-GAN und CLIP, Latent Diffusion Models und DALL·E 2 verglichen und stellt in seinem Forschungsbericht mit DrawBench eine neu entwickelte Methode zum Vergleichen und Bewerten von Text-Bild-Modellen vor.

Besser als DALL-E 2 laut menschlichen Testern?
Für Machine-Learning-Teams dürften zusammenfassend fünf Ergebnisse der Imagen-Forschung zentral sein:
- Für Bild-zu-Text-Aufgaben seien große, vortrainierte sowie "eingefrorene" (frozen) Text-Encoder besonders wirksam.
- Das Vergrößern des Text-Encoders ist für gute Ergebnisse offenbar wichtiger als ein Vergrößern des Bild-Diffusionsmodells.
- Imagen führt einen neuen Diffusions-Sampler für Schwellenwerte ein, der das Verwenden besonders großer, klassifikatorfreier Gewichte (Guidance Weights) erlaubt.
- Das Team führt eine neue U-Net-Architektur ein, die rechen- und speichereffizient sein soll sowie besonders schnell konvergiert und
- die Forscherinnen und Forscher heben einen hohen Score beim Vergleichsdatensatz COCO hervor, der dem Stand der Technik entspricht und belegt, dass die geprüften Bildproben in Bezug auf ihre Bild-Text-Übereinstimmung zu den Referenzbildern passen.
In ihrem Paper behauptet das Imagen-Team auch, dass menschliche Tester die Ergebnisse von Imagen gegenüber denen anderer Modelle im Vergleich stets bevorzugt hätten. Ob das generell zutrifft, lässt sich zurzeit – ohne öffentliche Demo und Testmöglichkeit – allerdings kaum überprüfen.
KI-Safety: Forschung braucht Zeit für Sicherheitsvorkehrungen
Wie bei den meisten anderen großen Sprach- und Bildmodellen im Machine Learning liegen Imagen meist unkuratierte, aus dem Internet gescrapte Datensätze zugrunde, aus denen unerwünschte Inhalte wie unter anderem Pornografie und toxische Sprache entfernt wurden. Dennoch nennen die Google-Forscher Sicherheitsbedenken und wollen ihr System zurzeit noch nicht öffentlich preisgeben, um zunächst "weitere Sicherheitsvorkehrungen" zu treffen, wie es im Paper heißt. Vorläufige Auswertungen deuteten darauf hin, dass Imagen eine Reihe sozialer Vorurteile und Stereotype kodiert wie auch eine allgemeine Tendenz, eher Menschen mit heller Hautfarbe darzustellen und bei Bildern von Berufen westliche Geschlechterstereotype reproduziert. Hier möchten die Google-Forscher mit ihrer weiteren Arbeit ansetzen und eingreifen.
Einige weiterführende Gedanken zur KI-Sicherheit finden sich beim Oxforder Wissenschaftler Sebastian Farquhar, der eine erste Einschätzung zu Imagen und den damit verwandten Modellen auf Twitter teilte.
Noch keine öffentliche Demo, dafür Website mit Doku
Wer sich die Ergebnisse von Imagen anschauen mag, ist zurzeit noch auf die Zuschauerrolle beschränkt. Interessierte können das bei arXiv.org publizierte Forschungspaper und die von Google Brains kuratierte Sammlung von Textprompts und ersten Bild-Outputs einsehen. Flankierend zur Website, die ein Bildarchiv, einen Link zur Forschung und Informationen über DrawBench bereitstellt, haben zahlreiche Google-Mitarbeiter – offenbar zeitlich untereinander abgestimmt – auf Twitter damit begonnen, mit Imagen erzeugte Bilder zu veröffentlichen.
Spannend zur vertiefenden Auseinandersetzung ist eine Zusammenstellung des New Yorker KI-Forschers und Philosophen Raphaël Millière, der seine Gedanken über den Fortschritt von Vision-Language-Modellen in einem mehrteiligen Twitter-Thread teilt.
Alle weiteren Details und anschauliche Beispiele sind auf der Imagen-Website von Google Research zu finden.
(sih)