

Make-a-Videoschnipsel: Googles KI-Diffusionsmodell Imagen macht Kurzvideos in HD
Kurz nach Meta präsentiert auch Google ein KI-Werkzeug zum Video-Erstellen nach Textvorgaben. Imagen Video wirkt etwas ausgereifter als Metas "Make a Video".

- Silke Hahn
Im Bereich KI-basierter Bilderzeugung verfeuern die großen Anbieter mittlerweile gefühlt im Sekundentakt ihr Pulver: Statt statischer Bilder ist man bereits beim Bewegtbild angelangt, früher als selbst Insider unlängst noch vermutet hätten. Dass es sich mitunter um Schnellschüsse handelt, zeigt der teils etwas unausgereift wirkende Stand der Ergebnisse, die vor allem eins ausstrahlen: Jeder will Erster sein – oder zumindest rasch präsentieren, was man schon hat. Offenbar hat die quelloffene, (fast) ohne Einschränkung für jeden greifbare Bildmaschine Stable Diffusion nicht nur dem DALL·E-Anbieter OpenAI einen Schrecken eingejagt, sondern auch in den KI-Entwicklungsabteilungen der Facebookmutter Meta und bei Google Brain aufs Gaspedal gedrückt. Oder hatte man beiderorts die KI-Systeme schon halbfertig in der Lade? Doch eins nach dem anderen.
Hochauflösende Video(-Schnipsel) durch Diffusionsmodelle
Knapp eine Woche nach der Vorstellung des KI-Videogenerators "Make a Video" durch den US-Konzern Meta zeigt Googles KI-Abteilung den Stand der eigenen Forschung in einem Paper und der ergänzenden Website mit Video-Demos. Diese sind wie bei Meta nur wenige Sekunden lang im Stile kurzer GIF-Animationen und zeigen teils noch das für KI-generierte Bildsequenzen typische Flackern, das beim Wechsel der mit Textprompt erstellten Einzelbilder auftritt. Allerdings flackern die Imagen-Videoschnipsel weniger als die Demos von Meta, die auf den unbedarften Betrachter Ende September (rein subjektiv) etwas ungelenk wirkten. Auffällig ist die offenbar ausgeprägte Fähigkeit des Imagen-Video-Modells, lesbaren Text zu visualisieren.

(Bild: Google Research)
Videos by heise
Text-zu-Bild plus räumlich-zeitliche Komponente
Imagen Video ist eine Erweiterung des im Mai 2022 vorgestellten Text-zu-Bild-Systems Google Imagen um die zeitliche Dimension. Laut Imagen-Team beruht das System zum Videoerstellen auf einer "Kaskade von Diffusionsmodellen". Ausgehend von einer Textvorgabe (Prompt) erzeugt das Werkzeug stufenweise hochauflösende Videos. Imagen Video verwendet ein neuronales Netz zum Generieren von Videos sowie daran anschließend eine Reihe miteinander verschachtelter Modelle (das ist offenbar mit dem Begriff Kaskade gemeint), die in mehreren Bearbeitungsetappen die räumliche Wiedergabetreue und zeitliche Dynamik verbessern sowie den Eindruck von High-Resolution bewirken.

(Bild: Google Research)
Wer sich die Architektur dieser Waschstraße genauer anschauen mag, kann in das Forschungspaper schauen, das das Team ergänzend zur Website veröffentlicht hat. Schaut man in das Forschungspaper, fällt direkt auf, dass eine Reihe vorangegangener Arbeiten die Grundlage bilden, so unter anderem ein Paper der OpenAI-Forscher zu DALL·E 2 und mehrere Forschungsberichte zu Diffusionsmodellen, unter anderem das von Robin Rombach und Team zu Stable Diffusion sowie Arbeiten zum 3D-Modellieren KI-erzeugter Grafiken.
Pipeline aus Diffusionsmodellen
Der technische Hintergrund ist komplexer und mathematisch anspruchsvoller, als der auf optische Wirkung abzielende Webauftritt vermitteln kann. Instruktiv ist die Veranschaulichung der Einzelschritte anhand von Beispielen von einem ersten, unscharfen Entwurf bis hin zum fertigen Video in hoher Auflösung, die auf der Website einsehbar ist. Laut Team sind bis zu 24 Bilder pro Sekunde (Frames per Second, kurz: FPS) in einer Auflösung von 1280 x 768 Pixeln möglich.
Das Rendern geschieht also nicht in einem Satz, sondern schrittweise. Dabei erzeugt das Basis-Diffusionsmodell zum Videogenerieren zunächst eine Sequenz von 16 Bildern (Frames) in der Auflösung 24 x 48 Pixel bei einer Bildrate von 3 Bildern pro Sekunde. Mit den weiteren Diffusionsmodellen skaliert das KI-System das Video sukzessive hoch und ergänzt weitere Bilder bis zur derzeit höchstmöglichen Auflösung von 24 FPS. Das Ergebnis nach dem Durchlaufen aller Schritte ist ein 5,3 Sekunden langes Video in HD. Die Pipeline skizzieren die Forscherinnen und Forscher im Paper wie folgt:

(Bild: Google Research)
T5: Text-To-Text Transfer Transformer in XXL für das Finetuning
Zum Training der Inputseite (kontextbezogenes Erkennen von Textprompts) hatte das Google-Team einen T5-XXL-Textencoder verwendet, T5 steht hierbei für fünfmal T (Text-To-Text Transfer Transformer) und XXL offenbar für die Dimensionen – die Library des T5-Modells ist auf GitHub verfügbar, dort finden Interessierte auch weitere Infos zum Thema. Die Weights des Modells wurden "eingefroren", wie eine Technik beim Trainieren und Modifizieren großer künstlicher neuronaler Netze heißt. Indem das Team einen Layer des neuronalen Netzwerks "einfriert" (freeze), behält es Kontrolle darüber, wie die Weights (Gewichtungen) weiter aktualisiert werden. Sie lassen sich dann zunächst nicht weiter modifizieren. Die Technik kommt beim Feintuning zum Einsatz.
Unter anderem lässt sich hierbei Rechenzeit sparen, während die Genauigkeit wenig darunter leiden soll. In weiteren Trainingsstufen sind dann entsprechend weniger Layer durchzutrainieren. Ein Überblick lässt sich einem Beitrag im Magazin Analytics India entnehmen. Das genaue Vorgehen und die einzelnen Design- und Architektur-Entscheidungen des Google-Research-Teams hat das Imagen-Team im Paper dargelegt. Dem Team zufolge war der Einsatz des Textencoders T5-XXL entscheidend, um die Passung zwischen Textvorgabe und Videooutput herzustellen. Dem Modell liegen 14 Millionen Video-Textpaare und 60 Millionen Bild-Textpaare zugrunde sowie ein Bilddatensatz aus der öffentlich zugänglichen Datenbank LAION-400M (mit rund 400 Millionen Bild-Textpaaren, wobei LAION die im Netz verfügbaren Paare lediglich indiziert und so zugänglich macht).
3D bis Destillieren
Für die Videoerstellung ist der Schritt von zweidimensionalen Bildern zu 3D wichtig, weshalb das Team sich für Video U-Net als Diffusionsarchitektur entschied. Die Text-zu-3D-Methode hatte der Google-Brain-Forscher Ben Poole am 29. September separat vorgestellt unter dem Namen DreamFusion. Bei Video U-Net können die miteinander verschachtelten Diffusionsmodelle offenbar simultan mehrere Videoframes blockweise bearbeiten, wobei SSR- und TSR-Modelle verkettet sind (SSR steht für Spatial Super-Resolution, TSR für Temporal Super-Resolution). Damit lassen sich offenbar längere zeitliche Dynamiken und Abläufe darstellen, ohne bildliche Kohärenz einzubüßen. Die weiteren Schritte bis hin zu einem progressiven Destillieren (Distillation) zum Beschleunigen und Sampeln sind im Forschungspaper nachzuvollziehen.
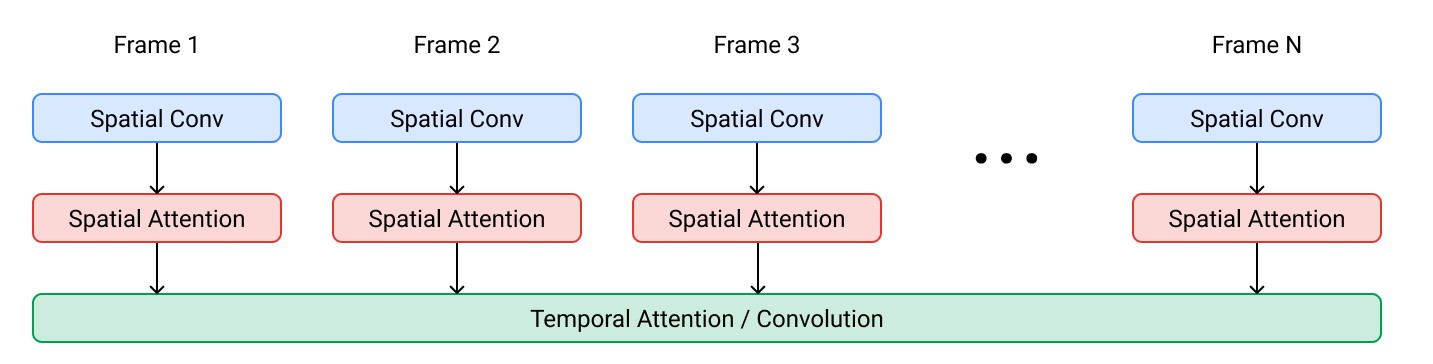
(Bild: Google Research)
Noch keine Demo zum Ausprobieren
Seitens Google besteht noch keine Möglichkeit, selbst ein solches Video zu erstellen oder das Tool anderweitig zu testen. Das Imagen-Team begründet das mit Sicherheitsbedenken: Zunächst seien noch problematische Bilder auszufiltern, um potenziellen Missbrauch in die Schranken zu weisen. Da das Modell mit frei verfügbarem Bildmaterial aus dem Internet trainiert worden ist, sind offenbar noch gefälschte, hasserfüllte, "explizite" (soll heißen: bildliche Nacktheit und sexuelle Handlungen) sowie schädliche Inhalte darin enthalten und ergo damit erzeugbar. Die internen Arbeiten daran, Eingabeaufforderungen sowie den Output zu filtern, scheinen noch nicht abgeschlossen zu sein.
Offenkundig gewalttätige oder pornografische Inhalte lassen sich dem Imagen-Team zufolge relativ leicht ausfiltern. Schwieriger ist es offenbar mit Stereotypen und Darstellungen, die einen impliziten (sozialen) Bias enthalten. "Wir haben beschlossen, das Imagen-Videomodell oder seinen Quellcode nicht zu veröffentlichen, solange diese Bedenken nicht ausgeräumt sind", lautet die Abschlussformel im Blogeintrag des Teams. Hierzu gilt anzumerken, dass auch von Google Imagen, dem Tool zum Erstellen statischer Bilder über Textvorgaben, bislang nur handverlesene intern erstellte Outputs zu sehen waren, aber weiterhin keine Demoversion greifbar ist. Der Text-zu-Bild-Generator Imagen war im Mai 2022 präsentiert worden, kurz nach dem im April 2022 erschienenen DALL·E 2.
Ausblick: Googles Schaufenster und Stable Diffusion
Wer sich die Imagen-Demos anschauen mag, wird auf der Forschungsseite von Google fündig. Zurzeit sind nur etwa fünf Sekunden lange Filmsequenzen im Netz greifbar, also bislang eher Videoschnipsel als Filme, die aber das Potenzial der neuen Technik bereits vor Augen führen. Diese Einschränkung gilt für das vom Google-KI-Team veröffentlichte Anschauungsmaterial ebenso wie die Demos von Meta – im Internet zirkulieren bereits Filmstücke von einigen Minuten Länge und erste Musikvideos, die von kreativen Programmierern mit Filmkenntnis mittels Stable Diffusion erstellt wurden.
Hier gilt insbesondere der KI-Filmpionier Glenn Marshall als Wegbereiter neuer Techniken: Nach der Auszeichnung seines KI-Kurzfilms The Crow in Cannes experimentiert er nun unter anderem mit Stable Diffusion und präsentiert in seinem Twitterkanal laufende Forschungs- und Kunststücke wie ein Projekt, bei dem er Texte von James Joyce und Gedichte bildlich umsetzt.

(sih)