

Open-Source-Datenanalyse: Apache Iceberg erreicht Version 1.0
Die Version 1.0 des Open-Source-Projekts Apache Iceberg bietet nicht nur mehr Stabilität bei den APIs, sondern nun auch einen Standard-REST-API-Katalog.

(Bild: Michal Balada/Shutterstock.com)
- Frank-Michael Schlede
Apache Iceberg, hinter dem das Unternehmen Dremio mit seinem Entwicklerteam steht, bietet die Spezifikation für ein offenes Tabellenformat für Big-Data-Analysen mit SQL. Die Software beinhaltet aber auch ein API-Set und entsprechende Bibliotheken, mit denen die Arbeit mit diesen Tabellen gemäß der Spezifikation erst möglich wird.
Videos by heise
Open-Source-Projekt für Data Warehousing
Es handelt sich um ein Open-Source-Projekt, das laut den Aussagen in einem Blogpost der Entwickler und Entwicklerinnen von Dremio bereits seit einiger Zeit produktionsreif sein soll. Es kommt unter anderem bei Unternehmen wie Netflix, Adobe und Apple für die Analyse zum Einsatz. Weiter führt das Entwicklerteam aus, dass die nun zur Verfügung stehende Version 1.0 die API-Stabilität garantiert. Dadurch soll sich die Technik besonders gut für Data Warehousing und Data Science-Anwendungsfälle in Verbindung mit Open-Lakehouse-Architekturen eignen.
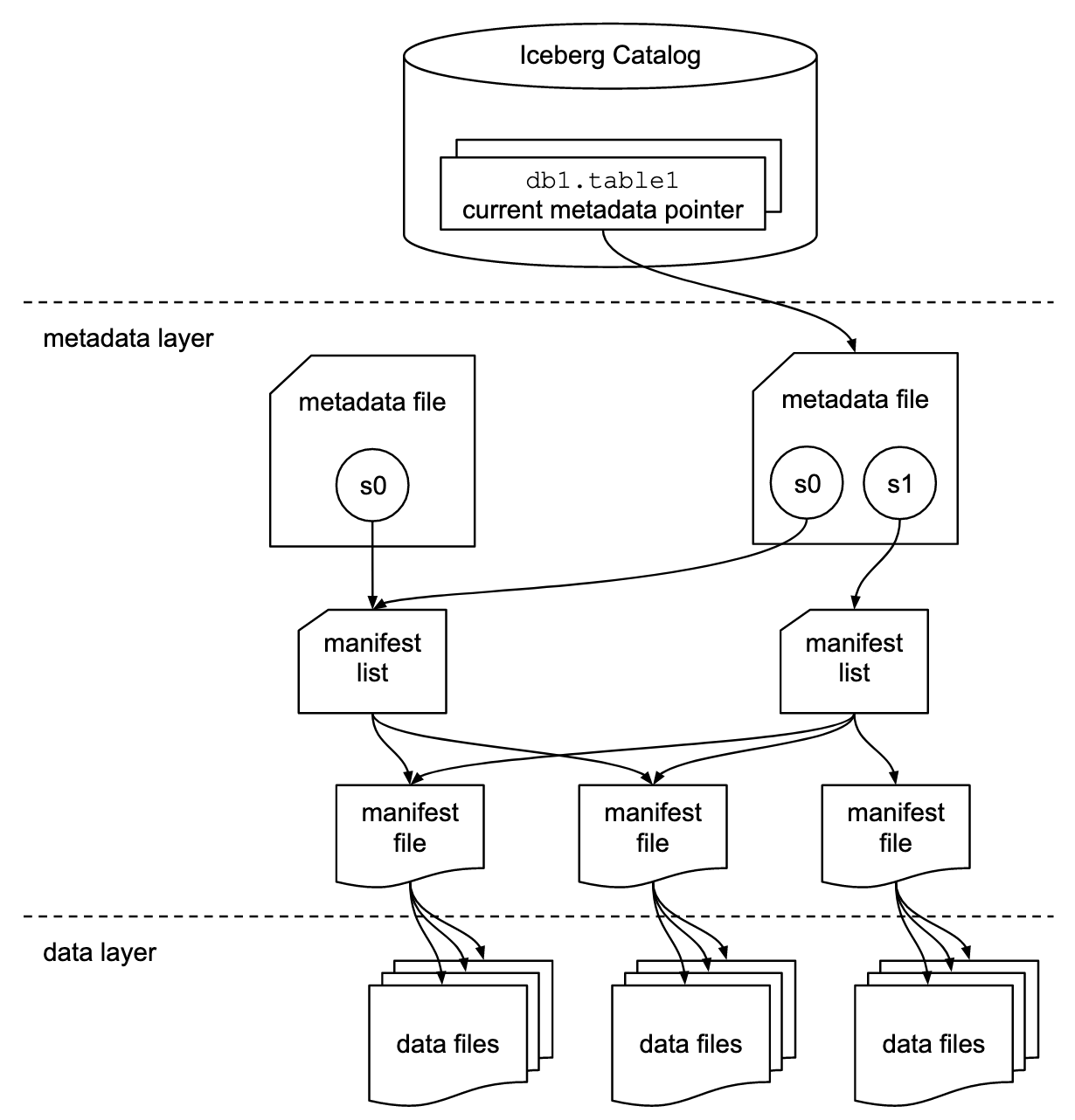
(Bild: Dremio)
Einfrieren der APIs garantiert Stabilität
Das Iceberg-Entwicklerteam betont, dass die APIs zwar schon seit einiger Zeit als stabil gelten, doch dass die Community rund um diese Open-Source-Software sich mit dem aktuellen 1.0-Release auch darauf geeinigt hat, die APIs auf dem gegenwärtigen Stand "einzufrieren". Damit sollen auch Entwicklerinnen und Entwickler, die bisher noch nicht bereit waren, auf ihnen aufzubauen, dies in Ruhe tun können. Neben den Garantien für die API-Stabilität beinhaltet das Major Release auch neue Funktionen und Verbesserung. Dazu gehören beispielsweise im Bereich “Leistung und Unterstützung für zusätzliche Anwendungsfälle“ die folgenden Features:
- Spark-Unterstützung für Merge-on-Read-Updates und -Löschungen,
- Optimierung der Sortierung in Z-Reihenfolge,
- das Puffin-Format für Statistiken und Indizes,
- neue Schnittstellen für die inkrementelle Verarbeitung von Daten,
- Unterstützung von Bloom-Filtern für Parquet-Zeilengruppen,
- Unterstützung für
mergeSchemabei Schreibvorgängen sowie - vektorisiertes Lesen für Parquet als Standard.
Breitere Integration des Ökosystems
Iceberg verwendet Kataloge dazu, die neueste Metadaten-Datei in einer bestimmten Tabelle atomar zu verfolgen. Viele Kataloge wie Hive Metastore, AWS Glue und Project Nessie unterstützen bereits Iceberg. In der Vergangenheit mussten Entwicklerinnen viele Schnittstellen und unterstützende Bibliotheken neu implementieren, um einen weiteren Katalog einbinden zu können.

Der neue REST-Katalog schafft jetzt eine universelle Schnittstelle zur Vereinfachung bestehender Kataloglösungen. Es handelt sich dabei um eine offene API-Spezifikation, die Interessierte hier einsehen können. Sie ermöglicht es jedem, seinen eigenen Katalog als REST-API zu implementieren. Wer neue Katalogimplementierungen erstellen möchte, muss keinen neuen Konnektor erstellen, solange er sich an die API-Spezifikation hält: Jede Engine, die die REST-API-Katalogimplementierung unterstützt, kann den neuen Katalog sofort verwenden.
Der sehr ausführliche Blog-Beitrag erläutert weitere Verbesserungen und Erweiterungen, die das Release 1.0 zu bieten hat. Zudem erleichtert ein umfassender Einsteigerkurs, der auch zahlreiche weitere Iceberg-Ressourcen auflistet, den Einstieg in die Konzepte und den Einsatz der Software.
(fms)