

Snowflake: Anwendungsentwicklung in der Data-Cloud mit Python und Open Source
Die Softwarefirma Snowflake hat auf ihrem "Snowday 2022" Verbesserungen ihrer Datenplattform vorgestellt, die die Anwendungsentwicklung vereinfachen sollen.

(Bild: Yurchanka Siarhei / Shutterstock.com)
- Frank-Michael Schlede
Snowflake hat im März 2022 die Firma Streamlit übernommen. Dadurch kann das Unternehmen den Entwicklerinnen und Entwicklern nun ein Open-Source-Framework anbieten, das es ihnen erleichtern soll, Datenanwendungen mit Python zu erstellen. Diese Integration, die sich aktuell noch in der Entwicklung befindet, soll es ihnen dann erlauben, Anwendungen zu erstellen, die die Daten direkt in Snowflake nutzen können.
Videos by heise
Entwickler-Framework jetzt allgemein verfügbar
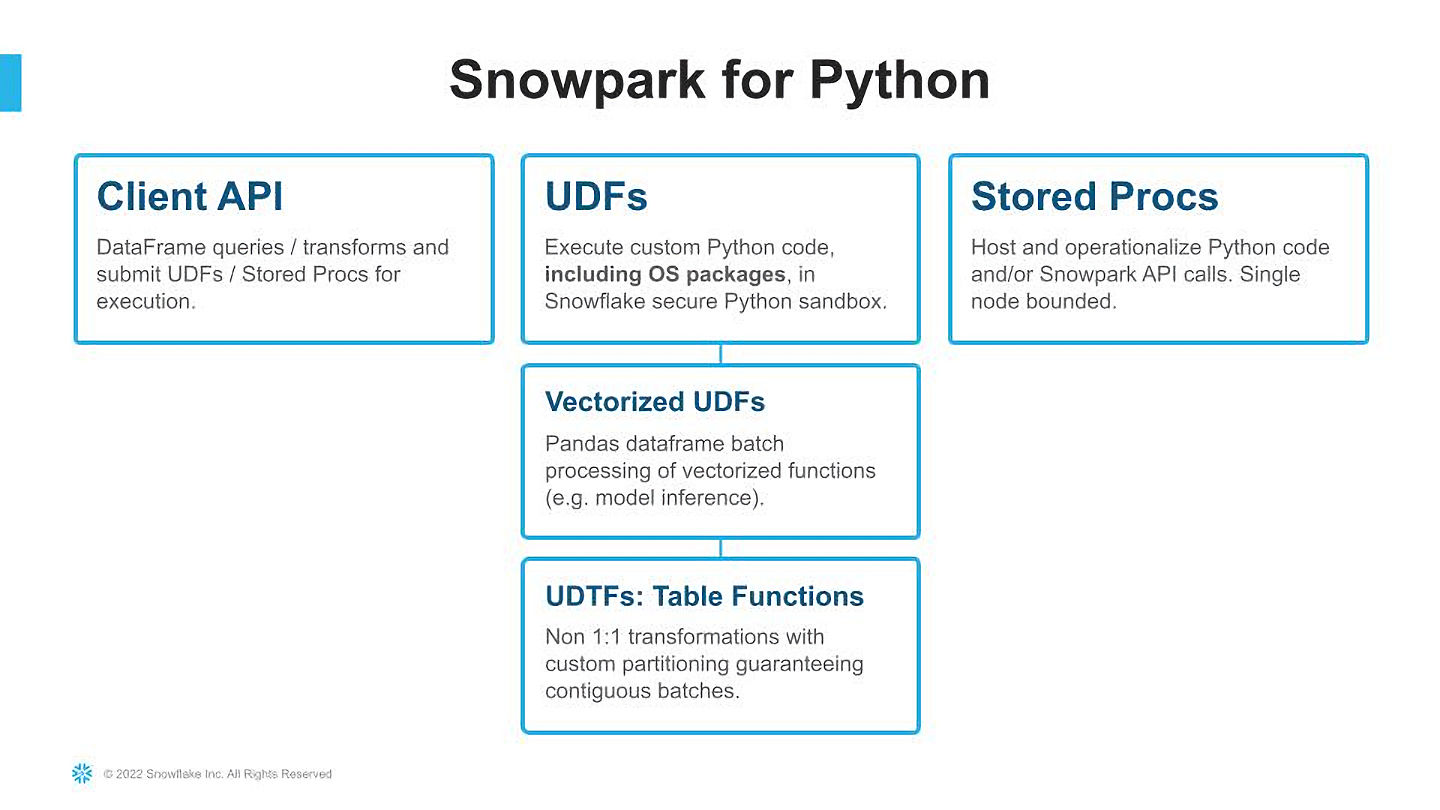
Bereits Ende 2021 hat Snowflake die Unterstützung von Python durch die eigene Entwicklungsumgebung Snowpark verkündet. Bis zu diesem Zeitpunkt unterstützte das Framework Java, Scala und SQL. Mit der nun im Rahmen des virtuellen Events Snowday 2022 offiziell verkündeten allgemeinen Verfügbarkeit von Snowpark für Python soll eine große Auswahl an entsprechenden Open-Source-Bibliotheken für alle Benutzer und Teams zur Verfügung stehen.
(Bild: Snowflake)
Dank neuer Funktionen sollen Entwickler und Entwicklerinnen ihre Anwendungen, Pipelines und Modelle mit einer einzigen Datenplattform auf der Basis der in der Daten-Cloud verfügbaren Daten und Machine-Learning-Modelle erstellen können. Sie können dabei durch den Einsatz von Snowflake für Python auf einer einheitlichen Plattform mit einer hochsicheren Python-Sandbox arbeiten.
Erweiterte Werkzeuge für die Arbeit in der Data-Cloud
Snowflake stellt zudem noch erweiterte Werkzeuge vor, die es Entwicklern noch leichter machen sollen, in der Data Cloud zu arbeiten. Dazu gehören unter anderem dynamische Tabellen (Private Preview): Sie wurden nach Aussagen des Entwicklerteams zunächst als "Materialized Tables" eingeführt und sollen die Grenzen zwischen Streaming- und Batch-Pipelines aufheben. Dieses Werkzeug soll die stufenweise Verarbeitung durch die Entwicklung von sogenannten deklarativen Datenpipelines automatisieren, um auf diese Weise die Kodierung effizienter und einfacher zu gestalten. Das soll zudem auch Anwendungsfälle wie das Erfassen von Änderungsdaten und das Isolieren von Snapshots erleichtern können. Weiterhin sollen sie Daten mit Schema Inference (Private Preview) schneller einbinden und Pipelines mit Serverless Tasks leichter innerhalb der Snowflake-Plattform ausführen können.
Um die Anforderungen von Entwicklern und Entwicklerinnen besser zu unterstützen, führt das Unternehmen nun auch eigene Funktionen zur Überwachung und Benutzerführung ein, damit die Entwickler Datenpipelines mit erhöhter Produktivität erstellen, testen, debuggen, bereitstellen und überwachen können. Das soll dann beispielsweise durch Alarmierung (Private Preview), Protokollierung (Private Preview), Ereignisverfolgung (Private Preview), Aufgabendiagramme und -verlauf (Public Preview) geschehen.
Wer sich weiter über diese Thematik informieren möchte, findet in einem ausführlichen Blogbeitrag der Snowflake-Entwickler umfangreiche Informationen, Beispiele und Links.
(fms)
