

Patterns in der Softwarearchitektur: Das Pipes-and-Filters-Muster
Das Pipes-and-Filters-Architekturmuster beschreibt die Struktur für Systeme, die Datenströme verarbeiten.

(Bild: Blackboard/Shutterstock.com)
- Rainer Grimm
Patterns sind eine wichtige Abstraktion in der modernen Softwareentwicklung und Softwarearchitektur. Sie bieten eine klar definierte Terminologie, eine saubere Dokumentation und das Lernen von den Besten. Das Pipes-and-Filters-Architekturmuster ist dem Schichtenmuster ähnlich und beschreibt die Struktur für Systeme, die Datenströme verarbeiten.

Die Idee hinter dem Schichtenmusters ist es, das System in Schichten zu strukturieren, sodass die höheren Schichten auf den Diensten der niedrigeren Schichten basieren. Das Pipes-and-Filters-Muster erweitert das Schichtenmuster auf natürliche Weise, indem es die Schichten als Filter und den Datenfluss als Pipes verwendet.
Pipes-and-Filters
Zweck
- Ein System, das Daten in mehreren Schritten verarbeitet.
- Jeder Schritt verarbeitet seine Daten unabhängig von den anderen.
Umsetzung
- Aufteilung der Aufgabe in mehrere Verarbeitungsschritte.
- Jeder Verarbeitungsschritt ist die Eingabe für den nächsten Verarbeitungsschritt.
- Der Verarbeitungsschritt wird als Filter bezeichnet; der Datenkanal zwischen den Filtern wird als Pipe bezeichnet.
- Die Daten kommen von der Datenquelle und landen in der Datensenke.
Struktur
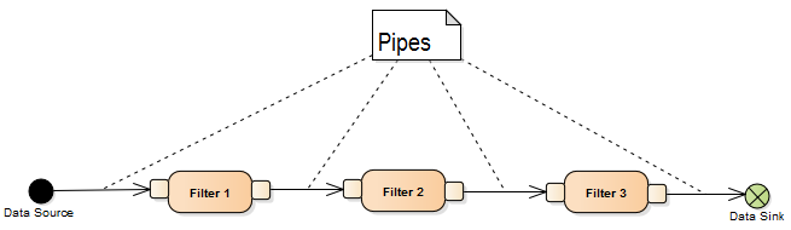

Filter
- erhält Eingabedaten,
- führt seine Operation mit den Eingabedaten durch und
- produziert Ausgabedaten.
Pipe
- überträgt Daten,
- puffert Daten in einer Warteschlange und
- Synchronisiert Nachbarn.
Data Source
- erzeugt Input für die Verarbeitungspipeline.
Data Sink
- verbraucht Daten.
Der interessanteste Teil des Pipes-and-Filters-Musters ist der Datenfluss.
Datenfluss
Es gibt mehrere Möglichkeiten, den Datenfluss zu steuern.
Push-Prinzip
- Der Filter wird durch Übergabe der Daten des vorherigen Filters gestartet.
- Der (n-1)-te Filter sendet (Schreiboperation) Daten an den n-ten Filter.
- Die Datenquelle startet den Datenfluss.
Pull-Prinzip
- Der Filter wird gestartet, indem er die Daten des vorherigen Filters anfordert.
- Der n-te Filter fordert Daten vom (n-1)-ten Filter an.
- Die Datensenke startet den Datenfluss.
Gemischtes Push/Pull-Prinzip
- Der n-te Filter fordert Daten vom (n-1)-ten Filter an und gibt sie explizit an den (n+1)-ten Filter weiter.
- Der n-te Filter ist der einzige aktive Filter in der Verarbeitungskette.
- Der n-te Filter startet den Datenfluss.
Aktive Filter als unabhängige Prozesse
- Jeder Filter ist ein unabhängiger Prozess, der Daten aus der vorherigen Warteschlange liest oder Daten in die folgende Warteschlange schreibt.
- Der n-te Filter kann Daten erst lesen, nachdem der (n-1)-te Filter Daten in die verbindende Warteschlange geschrieben hat.
- Der n-te Filter kann seine Daten erst schreiben, nachdem der (n+1)-te Filter die Verbindungs-Warteschlange gelesen hat.
- Diese Struktur wird als Producer/Consumer bezeichnet.
- Jeder Filter kann den Datenfluss starten.
Beispiele
Das bekannteste Beispiel für das Pipes-and-Filters-Muster ist die UNIX Command Shell.
Unix Command Shell
- Finde die fünf Python-Dateien in meiner python3.6-Installation, die die meisten Zeilen besitzen:
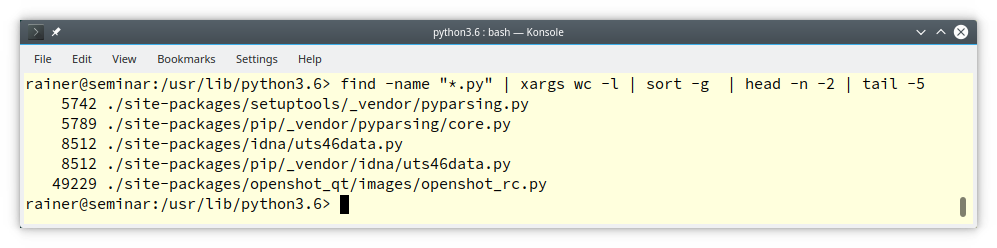
Hier sind die Schritte der Pipeline:
- Finde alle Dateien, die mit
pyenden:find -name "*.py". - Erhalte von jeder Datei die Anzahl der Zeilen:
xargs wc -l. - Sortiere numerisch:
sort -g. - Entferne die letzten beiden Zeilen mit irrelevanten statistischen Informationen:
head -n -2. - Ermittle die letzten fünf Zeilen:
tail -5.
Zum Schluss hier noch der Klassiker der Kommandozeilenverarbeitung mit Pipes von Douglas Mcllroy.
tr -cs A-Za-z '\n' |
tr A-Z a-z |
sort |
uniq -c |
sort -rn |
sed ${1}qWer wissen will, wie diese Pipeline funktioniert, findet die ganze Geschichte dahinter in dem Artikel "More shell, less egg".
C++ unterstützt das Pipes-and-Filters-Muster dank der Ranges-Bibliothek in C++20.
Ranges
Das folgende Programm firstTenPrimes.cpp zeigt die ersten zehn Primzahlen beginnend mit 1000 an.
// firstTenPrimes.cpp
#include <iostream>
#include <ranges>
#include <vector>
bool isPrime(int i) {
for (int j = 2; j * j <= i; ++j){
if (i % j == 0) return false;
}
return true;
}
int main() {
std::cout << '\n';
auto odd = [](int i){ return i % 2 == 1; };
auto vec = std::views::iota(1'000)
| std::views::filter(odd) // (1)
| std::views::filter(isPrime) // (2)
| std::views::take(10) // (3)
| std::ranges::to<std::vector>(); // (4)
for (auto v: vec) std::cout << v << " ";
}Die Datenquelle (std::views::iota(1'000)) erzeugt die natürliche Zahl, beginnend mit 1000. Zuerst werden die ungeraden Zahlen herausgefiltert (1) und dann die Primzahlen (2). Diese Pipeline hält nach zehn Werten an (3) und schiebt die Elemente in den std::vector (4). Die praktische Funktion std::ranges::to erstellt einen neuen Range (4). Diese Funktion ist neu in C++23. Deshalb kann ich den Code nur mit dem neuesten Windows-Compiler im Compiler-Explorer ausführen.

Vor- und Nachteile
Ich verwende in meinem folgenden Vergleich den Begriff universelle Schnittstelle. Das bedeutet, dass alle Filter die gleiche Sprache sprechen, wie beispielsweise xml oder json.
Vorteile
- Wenn ein Filter die Daten direkt von seinem Nachbarn pullt oder dies pusht, ist keine Zwischenpufferung der Daten notwendig.
- Ein n-ter Filter implementiert das Schichtenmuster und kann daher leicht ersetzt werden.
- Filter, die die universelle Schnittstelle implementieren, können neu geordnet werden.
- Jeder Filter kann unabhängig vom anderen arbeiten und muss nicht warten, bis der benachbarte Filter fertig ist. Dies ermöglicht eine optimale Arbeitsteilung zwischen den Filtern.
- Filter können in einer verteilten Architektur laufen. Die Pipes verbinden die entfernten Einheiten miteinander. Die Pipes können den Datenfluss auch aufteilen oder synchronisieren. Pipes-and-Filters wird häufig in verteilten oder nebenläufigen Architekturen eingesetzt und bietet große Möglichkeiten für Performanz und Skalierbarkeit.
Nachteile
- Die parallele Verarbeitung von Daten kann aufgrund des Kommunikations-, Serialisierungs- und Synchronisierungs-Overheads ineffizient sein.
- Ein Filter wie das Sortieren benötigt die gesamten Daten.
- Wenn die Verarbeitungsleistung der Filter nicht homogen ist, braucht man große Speicher zwischen ihnen.
- Um die universelle Schnittstelle zu unterstützen, müssen die Daten zwischen den Filtern formatiert werden.
- Der wahrscheinlich komplizierteste Teil dieses Pattern ist die Fehlerbehandlung. Wenn die Pipes-and-Filters-Architektur während der Datenverarbeitung abstürzt, sind die Daten eventuell nur teilweise oder gar nicht verarbeitet worden. Nun gibt es die folgenden Möglichkeiten:
- Den Prozess noch einmal zu starten, wenn die ursprünglichen Daten noch vorhanden sind.
- Nur die vollständig verarbeiteten Daten zu verwenden.
- Nach dem Einfügen von Markierungen in die lässt sich der Prozess noch einmal anhand der Markierungen starten, wenn das System abgestürzt ist
Wie geht's weiter?
Der Broker strukturiert verteilte Softwaresysteme, die mit entfernten Dienstaufrufen interagieren. Er ist für die Koordination der Kommunikation, ihrer Ergebnisse und Ausnahmen zuständig. In meinem nächsten Artikel werde ich tiefer in das Architekturmuster Broker eintauchen.
In eigener Sache: Mein einziges offenes C++ 20 Seminar in 2023
Für Kurzentschlossene. Alle Details rund um C++20:
