

Intel APX: Effizienter und schneller mit neuer x86-Befehlssatzerweiterung AVX10
Mit den Advanced Performance Extensions APX sortiert Intel die x86-Befehlssatzerweiterung AVX neu und strebt eine gemeinsame ISA für kommende x86-CPUs an.

Intel Xeon Max mit HBM-Speicher
(Bild: c't/Carsten Spille)
Intels neue Advanced Performance Extensions (APX) sollen auch für Endkunden relevant werden, denn kommende Prozessoren können auch mit bestehender Software schneller und energieeffizienter arbeiten. Dazu soll es laut Intel ausreichen, bestehende Programme, die bereits AVX nutzen, einfach neu zu kompilieren. Programme in dynamischen Sprachen wie Python oder Ruby profitieren schon durch das entsprechende Update der Laufzeitumgebung. Einen Zeitpunkt für die Einführung passender Hardware nennt Intel derzeit nicht.
Eine der wesentlichen Änderungen ist die Verdoppelung der General Purpose Register. Durch die von 16 auf 32 verdoppelte Zahl dieser Architekturregister in Prozessoren mit APX-Unterstützung kann das Rechenwerk zum Beispiel mehr Inhalte in den Registerspeichern bereithalten. Energieaufwendige Lade- und Speichervorgänge sollen im Vergleich zu herkömmlichem Intel-64-Programmcode um 10 respektive 20 Prozent abnehmen, wenn Intels Simulationen an einem Prototyp zutreffen.
Mit dem Compiler-Prefix REX2 wird der Zugriff auf die neuen Register auch für herkömmliche Integer-Instruktionen ermöglicht, während die Floating-Point- und AVX-Befehler über neue Bits im EVEX-Prefix darauf zugreifen. Das EVEX-Prefix erlaubt jetzt auch Integerbefehlen in ein bestimmtes Zielregister zu schreiben; durch diese 3-Operand-Instruktionen entfallen MOV-Befehle, um Registerinhalte zu verschieben, sodass auch hier Einsparungen von 10 Prozent möglich seien, sagt Intel. Zugleich lassen sich Befehle zusammenfassen, sodass der Programmcode nicht notwendigerweise aufgebläht wird.
Vor wenigen Wochen hat Intel mit x86-S oder x86S bereits einen Überarbeitungsvorschlag für seine x86-Prozessoren gemacht, der Ballast abwerfen und alte Zöpfe abschneiden soll.

(Bild: c't/Carsten Spille)
Videos by heise
Bedingter Code: MOV it
Mit APX gibt es auch bei den mit dem Pentium Pro eingeführten bedingten Befehlen weitreichende Änderungen. Das sogenannte Conditional Instruction Set wird mit neuen CMOV-SET-Befehlen erweitert, um das Potenzial auch bei stark verzweigtem und schwer vorhersagbarem Programmcode zu nutzen. Solcher Programmcode hängt bei modernen Prozessoren mit Out-of-Order-Ausführung stark an der Genauigkeit der Sprungvorhersage – liegt die daneben und ein invalider Zweig wurde ausgeführt, sind viele Berechnungen und energetisch teure Datenbewegungen für die Katz. Die Conditionals sind bisher zu unflexibel, um große Vorteile bei sogenannten If-Conversions zu bringen, die die teuren Abhängigkeiten beim Control Flow (Programmverzweigungen) in solche bei den Daten umwandeln und die von modernen Compilern häufig genutzt werden.
Mit APX gibt es bedingte Versionen von Lade-, Speicher- und Vergleichsbefehlen (Load, Store, Compare/Test), mit denen die If-Conversions auch auf größere Codeabschnitte angewandt werden können, um teure Fehlausführungen bei Programmverzweigungen zu verringern. Auch diese Funktionen sollen bei APX-fähigen Prozessoren durch einfache Neukompilieren nutzbar sein. Conditional Loads/Stores mit Fault Suppression (Fehlerunterdrückung) haben sich Entwickler schon länger für die x86-Vektoreinheiten gewünscht, nachdem es in den Scalable Vector Extensions (SVE) von ARM64 enthalten war.
Zum Abschluss seiner Ankündigung kann Intel sich einen Seitenhieb auf ARM nicht verkneifen, indem man die x86-Flexibilität durch variable Instruktionslängen betont, durch die diese Änderung überhaupt erst ohne komplettes Neudesign der Instruktionsdekoder möglich gemacht würde und die den Grundstein für die vergangenen vier Jahrzehnte der Weiterentwicklung ermöglicht hätten.
(Bild: Intel)
Einheitliches AVX10 für Server und Client
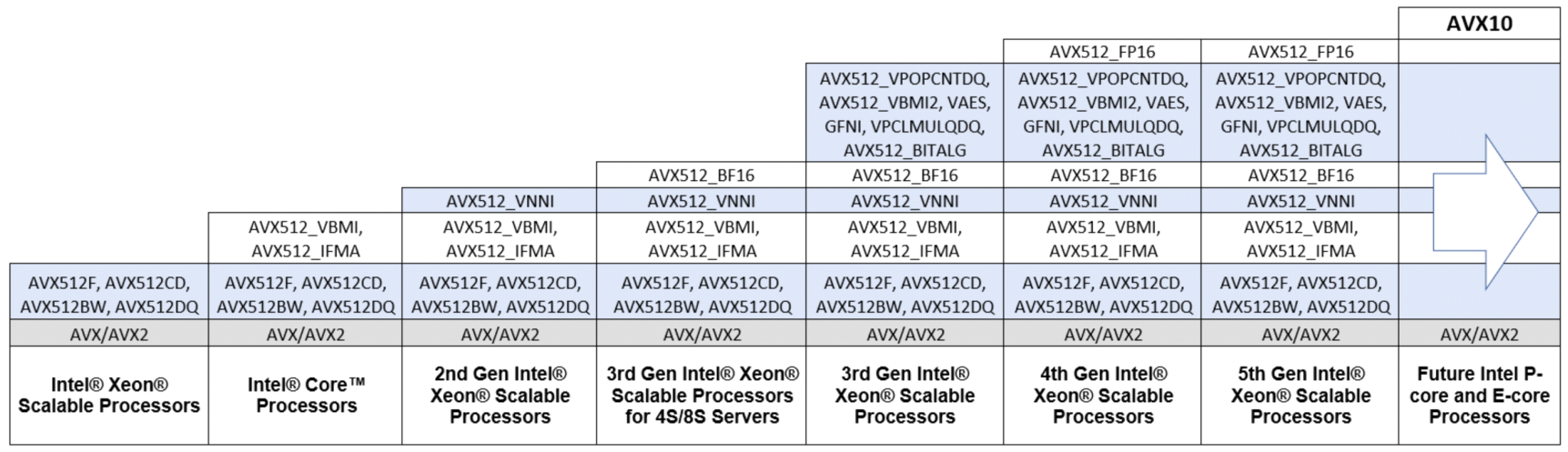
Intel kündigte auch eine umfassende Überarbeitung seiner x86-Befehlssatzerweiterung AVX an. Entwickler hatten sich verstärkt über den zunehmenden Wildwuchs speziell bei AVX-512 für Server-CPUs beschwert. Mit der kommenden Granite-Rapids-Generation von Serverprozessoren gibt es mehr als 20 verschiedene Varianten von AVX-512 alleine bei Intel-Prozessoren, die die Entwickler per Flag abfragen müssen und ihre Software auf einen oder mehrere Codepfade optimieren. Das ist einer der Gründe für die geringe Verbreitung von AVX-512 außerhalb von spezieller HPC-Software und damit wiederum ein Grund, die flächenmäßig und energetisch teure Hardware-Implementierung aus den sparsamen E-Cores von Core i-12000/13000/14000 zu streichen. Das wiederum führte in Folge dazu, dass die in den P-Cores der genannten Prozessoren vorhandene Hardware nur als AVX256-Einheit genutzt wird. Eine für alle Parteien unbefriedigende Situation.
Beginnend mit den Serverprozessoren Codename Granite Rapids, will Intel nun die Voraussetzungen für ein gemeinsames AVX schaffen und nennt das AVX10. Granite Rapids, genauer dessen Performance-Kerne, sollen als Wegbereiter für AVX10.1 dienen, bevor kommende Intel-Prozessoren AVX10.2 dann in P- und E-Kernen unterstützen.

(Bild: Intel)
Dafür friert Intel das derzeitige AVX-Featureset ein und definiert es als Untermenge von AVX10 mit optionaler Vektorlänge von 128, 256 oder 512 Bit. Für AVX10 gibt es dann ein einziges Bit in der Vector-ISA, eine Versionsnummer und drei Bits, die die Vektorenlänge bei dem jeweiligen kommenden Prozessor anzeigen. Ab welcher Prozessorgeneration AVX10.2 dann breitflächig unterstützt wird, sagt Intel noch nicht. Wahrscheinlich ist aber, dass die E-Kerne für platz- und stromsparende Ausführung kleinere Vektoren als 512 bekommen.
Durch das dann wieder vereinheitlichte Featureset hofft Intel, die Verbreitung der neuen AVX-Version zu verbessern und dann endlich nicht mehr so viel überflüssiges Silizium auf seinen Chips mit durchzuziehen. AMDs Zen4-Kerne in Ryzen 7000 und Epyc 9004 unterstützen viele AVX-512-Befehle bereits mit einer Vektorenlänge von 256 Bit und sind den Intel-Prozessoren in dieser Hinsicht einen Schritt voraus.


(csp)
