

Programmiersprache C++: Benchmark der parallelen STL-Algorithmen
In einem Gastbeitrag zum Blog "Modernes C++" beschreibt Victor J. Duvanenko die parallelen STL-Algorithmen.

(Bild: MP_P/Shutterstock.com)
- Rainer Grimm
Heute freue ich mich, einen Gastbeitrag von Victor J. Duvanenko über meine Lieblingsfunktion der STL präsentieren zu können: die parallelen STL-Algorithmen. Victor hat ein Buch über "Practical Parallel Algorithms in C++ and C#" veröffentlicht. Damit springe ich direkt zu der Übersetzung von Victors englischem Gastbeitrag:

C++ enthält einen Standardsatz von generischen Algorithmen, die STL (Standard Template Library). Unter Windows bietet Microsoft parallele Versionen dieser Algorithmen an, die unten aufgeführt sind, wobei das erste Argument std:: ist. Auch Intel bietet parallele Implementierungen an, die im Folgenden mit dem ersten Argument dpl:: aufgeführt sind. Diese parallelen Versionen nutzen mehrere Kerne des Prozessors und bieten eine wesentlich schnellere Leistung für viele der Standardalgorithmen.
Die Angabe einer Single-Core- oder Multi-Core-Version von Algorithmen ist einfach, wie im Folgenden gezeigt wird:
sort(data.begin(), data.end()); // single-core
// or
sort(std::execution::seq, data.begin(), data.end()); // single-core
// Parallel multi-core
sort(std::execution::par, data.begin(), data.end()); // multi-coreDie ersten beiden Aufrufe von sort() sind gleichwertig und werden auf einem Single-Core-Prozessor ausgeführt. Der letzte Aufruf von sort()nutzt mehrere Kerne. Es gibt vier Varianten den Algorithmus auszuführen:
seq- sequentielle Ein-Kern-Versionunseq- Ein-Kern SIMD/SSE vektorisiertpar- Multicore-Versionpar_unseq- Multi-Core SIMD/SSE vektorisiert
Die folgende Tabelle zeigt die Algorithmen, die den höchsten Grad an paralleler Beschleunigung aufweisen, wenn sie auf einem 14-Core i7-12700 Laptop-Prozessor ausgeführt werden und ein Array von 100 Millionen 32-Bit-Ganzzahlen verarbeiten:
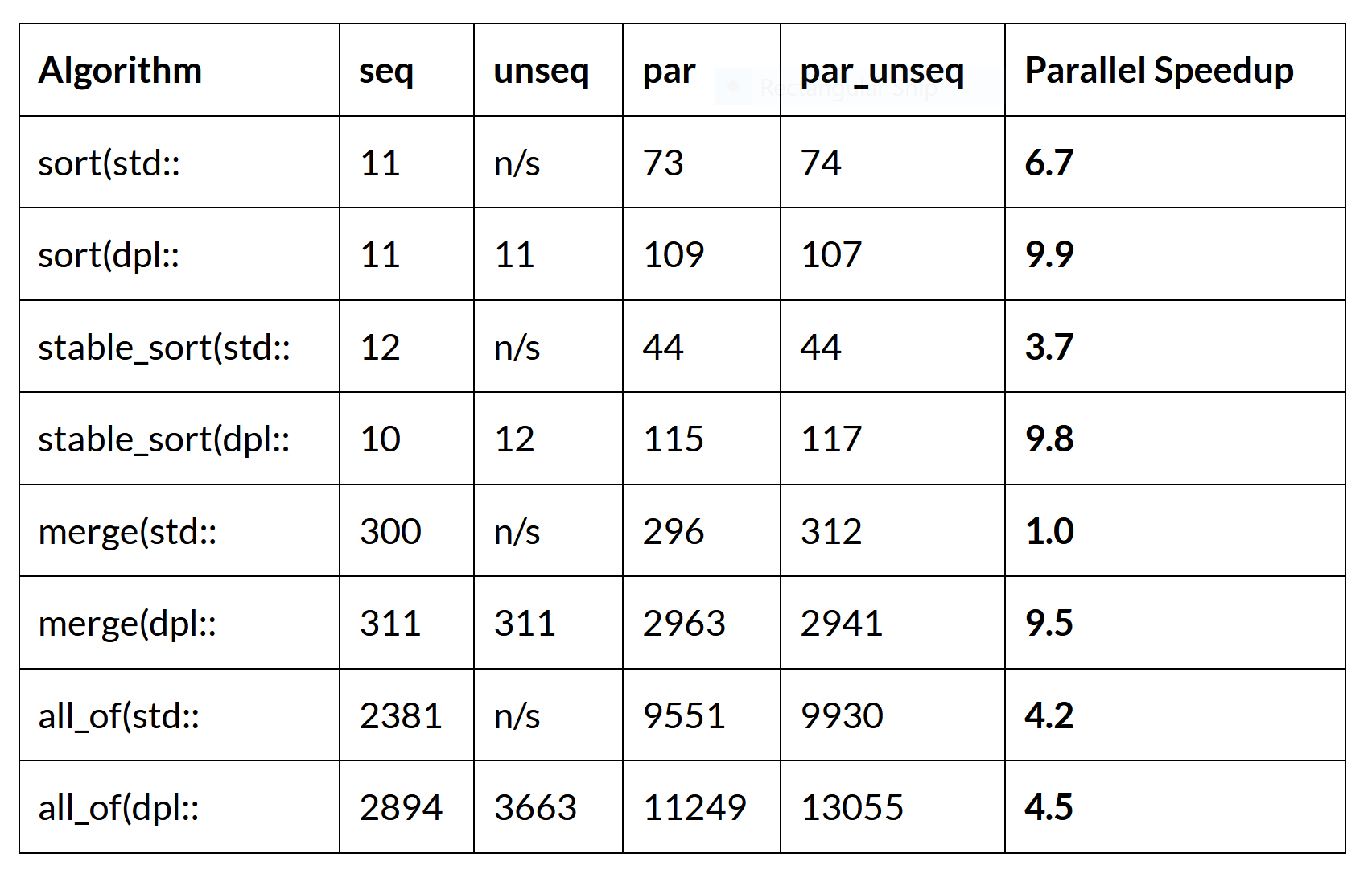
n/s bedeutet nicht unterstützt, das heißt, dass die Variante nicht implementiert ist.
Benchmarks auf einem Prozessor mit 48 Kernen werden später gezeigt. Die Einheiten für jedes Element in der Tabelle sind Millionen von ganzen Zahlen pro Sekunde. Beispielsweise läuft die par-Version von sort(std:: mit 73 Millionen ganzen Zahlen/Sekunde und die par-Version von sort(dpl:: mit 109 Millionen ganzen Zahlen/Sekunde. Jede Spalte zeigt die Performanz einer Implementierung, aus der die Array-Größe von 100 Millionen gewählt wurde. Diese Größe schließt Caching-Effekte aus, da das Array zu groß ist, um in den Cache des Prozessors zu passen. Damit lässt sich die parallele Verbesserung für den Anwendungsfall eines sehr großen Arrays messen.
Benchmark-Umgebung
Die obigen Benchmarks wurden mit VisualStudio 2022 im Release-Modus unter Verwendung des Intel C++ Compilers und der Intel OneAPI 2023.1 Umgebung durchgeführt. Dies ermöglichte den Zugriff sowohl auf Microsoft std:: Implementierungen als auch auf Intel dpl:: Implementierungen. Die Benchmarks wurden unter Windows 11 durchgeführt.
Beobachtungen
Nicht alle Standardfunktionen werden von Microsoft oder Intel implementiert.
Microsoft unterstützt die sequenzielle SIMD-Implementierung (unseq) für viele Algorithmen nicht, da sich diese Implementierung nicht kompilieren lässt. Bei anderen Algorithmen lassen sich die Microsoft-Implementierungen zwar kompilieren, bieten aber keinen Leistungsvorteil.
Intel implementiert mehr parallele Algorithmen mit höherer Leistung für die meisten Algorithmen, mit Ausnahme der Anzahl (bei 48 Kernen). Parallele Funktionen erfahren eine parallele Skalierung bei steigender Kernanzahl. Alle Algorithmen beschleunigen sich, wenn sie auf mehreren Kernen ausgeführt werden.
Weitere parallele Standardalgorithmen
Die folgende Tabelle enthält Benchmarks für Single-Core- und Multicore-Implementierungen von Standard-C++-Algorithmen auf dem 14-Core-Laptop-Prozessor:
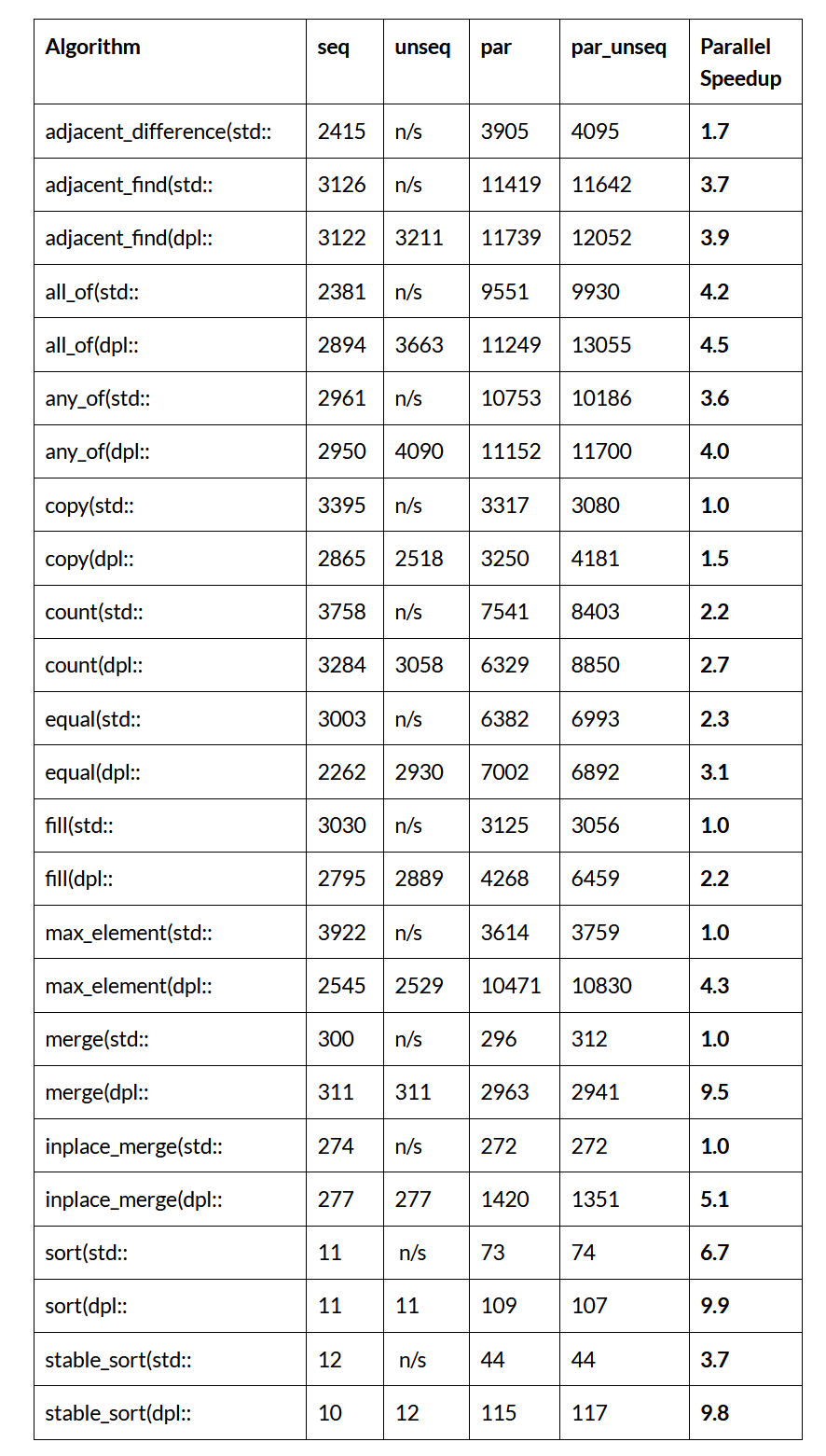
Mehr Kerne, mehr Leistung
Einige der Standard-C++-Algorithmen skalieren besser als andere, wenn die Anzahl der Prozessorkerne steigt. Die folgende Tabelle zeigt die Leistung von seriellen Single-Core- und parallelen Multi-Core-Algorithmen auf einem 48-Core Intel Xeon 8275CL AWS-Knoten bei der Verarbeitung eines Arrays von 100 Millionen 32-Bit-Ganzzahlen:
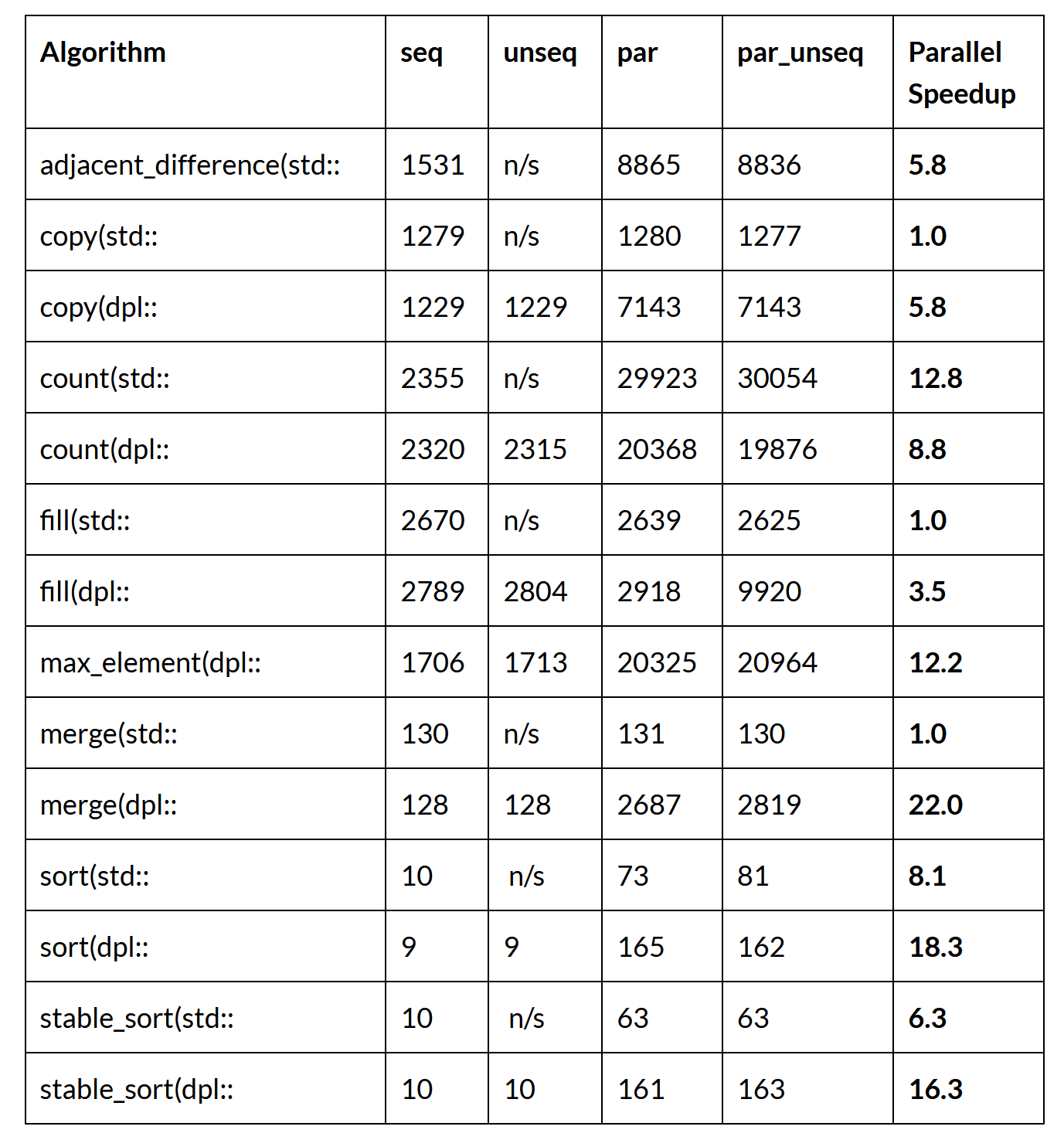
Jeder parallele Algorithmus wird stärker beschleunigt, wenn mehr Kerne und eine höhere Speicherbandbreite auf dem 48-Kern-Prozessor verfügbar sind. Bei großen Problemen bieten parallele Algorithmus-Implementierungen einen erheblichen Leistungsvorteil.
Parallele Algorithmen von Nvidia
Nvidia hat eine C++ Parallel-STL-Implementierung für den nvc++-Compiler entwickelt, die auf x86-Befehlssatzprozessoren wie denen von Intel und AMD ausgeführt werden kann. Die folgende Tabelle wird in Kürze für die Kompilierung des Benchmarks mit -stdpar=multicore aktualisiert:
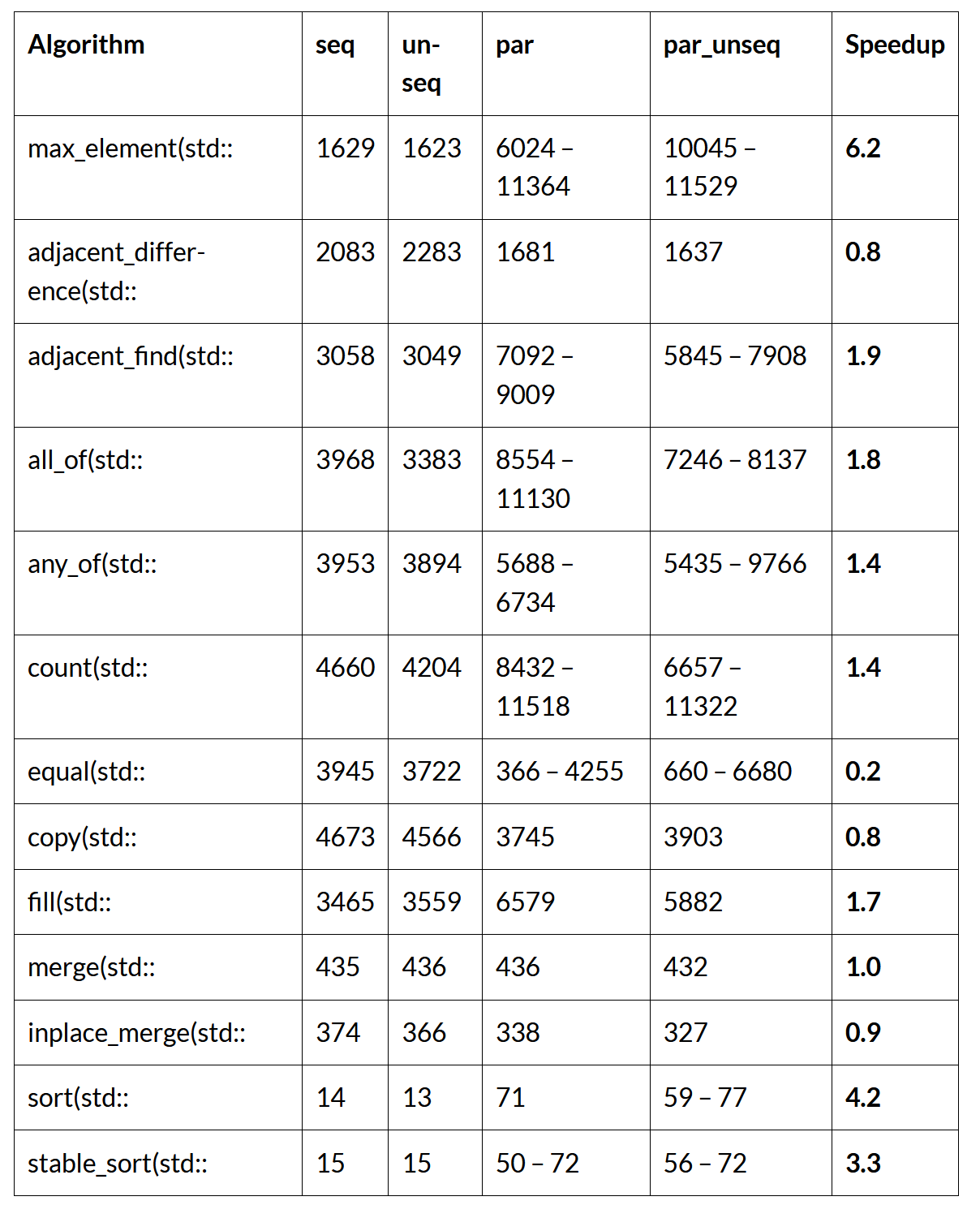
Die parallelen Implementierungen von Nvidia weisen im Vergleich zu denen von Intel und Microsoft erhebliche Leistungsunterschiede auf. Nvidia unterstützt auch die Beschleunigung von Standard-C++-Algorithmen mit GPUs. Siehe Benchmarks in diesem Blog.
Benchmark-Code
Der Quellcode für die Benchmark-Implementierung ist in diesem Repository frei verfügbar: https://github.com/DragonSpit/ParallelSTL
Eigene Algorithmen mit höherer Leistung
Wer eigene parallele Algorithmen entwickeln möchten, erfährt darüber mehr im folgenden Buch anhand von Beispielen. Die Standardalgorithmen implementieren zum Beispiel nur eine vergleichsbasierte Sortierung. Das im Buch entwickelte parallele Linear-Time Radix Sort steigert die Leistung um ein Vielfaches. Es werden verschiedene Strategien zur Vereinfachung der parallelen Programmierung demonstriert, wobei der gesamte Quellcode in einem Repository frei verfügbar ist:

Wie geht es weiter?
In meinem nächsten Artikel setze ich meine Reise durch C++23 fort. Diesmal werde ich über std::expected schreiben.
(rme)
