

Apache Hop – der nächste große Sprung in der Datenintegration
Dank visueller Drag-and-Drop-Benutzeroberfläche ermöglicht Apache Hop schnelles produktives Arbeiten mit Daten – ohne Code schreiben zu müssen.

(Bild: Volodymyr Burdiak / Shutterstock.com)
- Philipp Heck
Apache Hop ist eine neue, auf Metadaten basierende Open-Source-Plattform für Data Engineering und Datenorchestrierung. Das erste offizielle Release der Hop Orchestration Platform erschien im Oktober 2021, seit Mitte des laufenden Jahres liegt Version 2.0 vor. Warum sie für Dateningenieure interessant ist: Die visuelle Entwicklung per Drag-and-Drop- ermöglicht es, Workflows und Pipelines sehr einfach zu gestalten. Dabei sind Scripting und das Schreiben von Code eine Option, keine Notwendigkeit. So haben erfahrene Data Engineers die Möglichkeit, zusätzliche Skripte mitzuverarbeiten, während Nicht-Hardcore-Entwickler sich – mit einer steilen Lernkurve – selbst ihre Datenpipelines erstellen können.
Die visuelle Entwickleroberfläche ermöglicht es Entwicklerinnen und Entwicklern, produktiver zu sein als allein durch das Schreiben von "echtem" handgefertigtem Code. Die Hop GUI ist eine vollwertige visuelle IDE, die sowohl für den Desktop (Windows, macOS und Linux) als auch den Browser (Hop Web) verfügbar ist. Mit Hop GUI lassen sich Workflows und Pipelines visuell entwerfen, ausführen und debuggen.
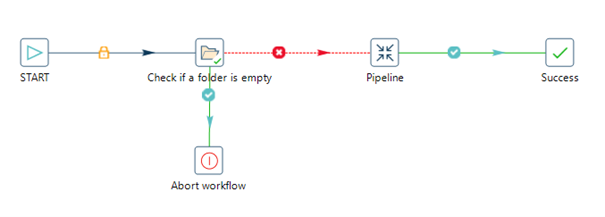
Der visuelle Editor ermöglicht es nicht nur, Hop-Workflows und -Pipelines einfach zu erstellen, auch die Pflege und Nachvollziehbarkeit des visuellen Codes ist einfacher als bei handgeschriebenem Code. Ein Problem zu identifizieren und zu beheben ist in einem klar definierten visuellen Layout viel einfacher, als durch die vielen Zeilen des Quellcodes scrollen zu müssen.

Die grafische Aufbereitung erleichtert auch das Verständnis der erzeugten Pipelines, wenn Entwicklerinnen und Entwickler die Business-Logik mit der Fachabteilung erstellen und abstimmen müssen. Die Fachabteilung bauen so auch mehr Vertrauen in die jeweiligen Daten-Pipelines auf, und gemeinsam kommen alle Beteiligten im Fehlerfall schneller zu Lösungen oder erzielen rascher ein gemeinsames Verständnis bei neuen Anforderungen. Während der Transformation und Zusammenführung der Daten erhält man auf jeder Transformationsstufe Echtzeiteinblicke basierend auf den Daten und verwandelt diese während der Entwicklung in nützliche Informationen.
Trotz aller Vorteile der visuellen Gestaltung sollten Hop-Nutzerinnen und -Nutzer beim Verwalten der Pipelines und Workflows nicht auf Versionskontrolle verzichten. Darüber hinaus empfiehlt sich die nahtlose Integration von Tests, CI/CD und Dokumentation – all das beherrscht Apache Hop.
Strikte Datentrennung
Apache Hop trennt Daten strikt von Metadaten, sodass sich die Datenprozesse unabhängig von den Informationen gestalten lassen. Jeder Objekttyp in Hop beschreibt sowohl, wie Daten gelesen, bearbeitet oder geschrieben werden, als auch, wie Workflows und Pipelines orchestriert werden. Auch intern ist Hop metadatengesteuert und verwendet eine Kernel-Architektur mit einer robusten Engine. Neue Funktionen lassen sich durch den Metadatenansatz in Form von Plug-ins einfach hinzufügen.
Das Hop-Entwicklerteam hat von Beginn an auf Flexibilität, Erweiterbarkeit und Wartbarkeit der Plattform konzentriert. Alles sollte austauschbar sein. Das bedeutet für Systemadministratoren, dass sie die volle Kontrolle über die Funktionsweise haben, schnell neue Funktionen in Form von Plug-ins hinzufügen können, und auch nur jene zulassen, die wirklich nötig sind. Damit fügt sich Hop gut in DevOps- und CI/CD-Umgebungen ein.
Viele Data Engineers sollten mit der Herausforderung vertraut sein, viele Projekte gleichzeitig umsetzen zu müssen. Dabei kann es leicht zu Fehlern kommen, wenn die Beteiligten in mehreren Projekten oder über mehrere Branches hinweg arbeiten: Schnell ist der erstellte Code im falschen Projekt gespeichert. Das integrierte Lifecycle Management in Hop ermöglicht es, zwischen verschiedenen Projekten und Umgebungen zu wechseln. Hop passt dabei automatisch alle Metadaten dem jeweiligen Projekt an, sodass ein Arbeiten im "falschen Raum" fast unmöglich ist.
Videos by heise
Typische Data-Engineering-Teams decken meist mehrere Themen ab und führen diese in einer Reihe von Umgebungen aus. In Hop können die Teams ihre Arbeit in separaten Hop-Projekten organisieren und mit unterschiedlichen Umgebungskonfigurationen pro Projekt speichern. Durch die Trennung von Projekten und Umgebungen behalten die Teams von der Entwicklung über das Testen bis hin zur Produktion die Übersicht und Kontrolle über den Code und die jeweiligen neuen Features.
In der Hop-Oberfläche erstellte Workflows und Pipelines sind laufzeitunabhängig und lassen sich auf unterschiedlichen Umgebungen wie einem lokalen Laptop, einem Remote-Server oder auch auf Apache Spark, Apache Flink und Google Dataflow über Apache Beam ausführen. Nutzerinnen und Nutzer können so eine einfache und schnelle Skalierung ihrer ETL-Datentransformationsprozesse (Extract, Transform, Load) vornehmen. Auch Upgrades schon länger bestehender ETL-Strecken auf neue Techniken gelingen leichter, wenn immer schnellere Zyklen die Projektteams vor Herausforderungen stellen. Erfahrungsgemäß verbraucht der Austausch eines ETL-Tools alle paar Jahre sehr viel Zeit und Ressourcen – und verursacht damit vermeidbare Kosten.
Vierfache Arbeitserleichterung
Bei der täglichen Arbeit profitieren Hop-Anwenderinnen und -Anwender regelmäßig von den gleichen vier großen Arbeitserleichterungen:
- Qualität der Datenprozesse durch Testen,
- verbesserte Zusammenarbeit in verteilten Teams durch visuelle Codevergleiche,
- individuelle Logging-Verfahren sowie
- flexible und schnell skalierende Laufzeit-Umgebungen.