

Das Hochwasserportal für das Land Niedersachsen in Windows Azure
Seite 2: Umsetzung
Von der Messstelle zur Cloud
Auch wenn die Website stets den Wasserstand mit nur 15 bis 30 Minuten Verzögerung zeigt, ist der Weg der Daten weiter und komplexer, als sich vermuten lässt, denn der größere Teil des Betriebsdateninformationssystems (BIS) des NLWKN arbeitet nicht in der Cloud, sondern im hauseigenen Rechenzentrum. Dort steht eine Serverfarm, die zunächst einmal die Daten von den eigenen Pegelmessstellen abruft (Pull-Verfahren) oder entgegennimmt (Push-Verfahren). Für den Datenabruf wird unter anderem eine mit Linux laufende Appliance benötigt. Hinzu kommen Wetterdaten, die das NLWKN zum Teil selbst misst oder vom Deutschen Wetterdienst (DWD) bezieht. Der DWD liefert darüber hinaus die Wettervorhersage für die nächsten 24 Stunden, denn Niederschlag und Schneeschmelze sind entscheidend für die Vorhersage der Pegelstände in den darauf folgenden Stunden.
Die hausinternen Server importieren und prüfen die Daten im Hinblick auf ihre Plausibilität. Außerdem finden Umrechnungen statt, wie das Bestimmen des Wasserdurchflusses in Quadratmetern aus dem gemessenen Wasserstand in Zentimetern. Über eine selbstentwickelte Windows-Anwendung (mit Windows Presentation Foundation, WPF) oder verschiedene externe Fachanwendungen können die Pegelarbeiter und die Hochwasservorhersagezentrale die Daten betrachten, vergleichen, für Vorhersagen verwenden und bei Bedarf offensichtliche Messfehler korrigieren. Für den Internetauftritt ermittelt das Betriebsdateninformationssystem jedoch selbstständig und ohne Benutzerinteraktion einen sinnvollen Wert, den es dann per Webservices an die in der Cloud betriebene Website sendet (s. Abb. 3). Das Cloud-System kann umgekehrt Daten an die lokale Infrastruktur liefern. Derzeit sind es nur Daten über die eigene Auslastung, denkbar ist aber auch die Registrierung von Benutzern zur Alarmierung mit E-Mail und Telefax, die von der In-House-Struktur ausgeführt wird.
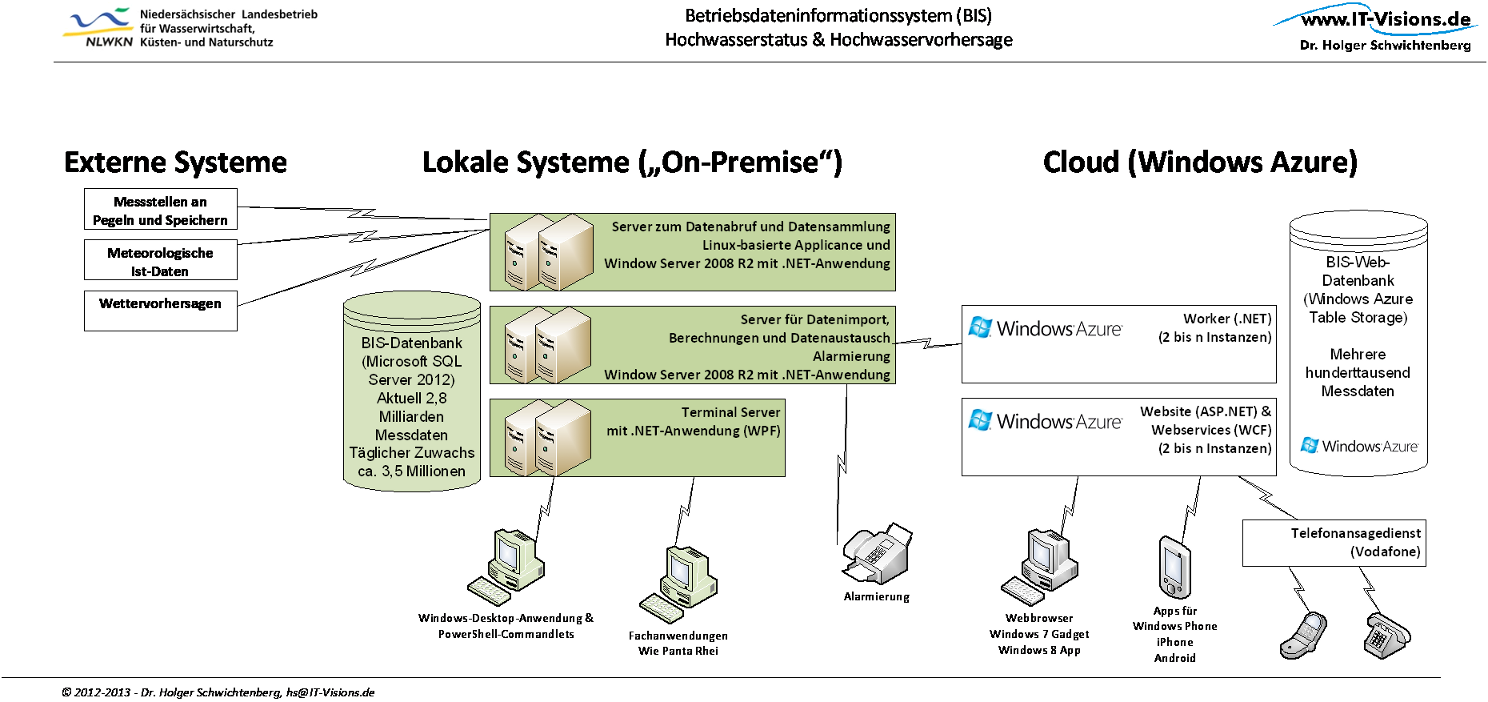
Das In-House-System speichert aktuell 2,8 Milliarden Messdaten bei einem täglichen Zuwachs von 3,5 Millionen Datensätzen. Ein Messdateneintrag besteht aus einem Zeitpunkt, einem Messwert und erweisen auf Masterdaten, die die Herkunft und Bedeutung der Messdateneinträge klären. Eine Reihe von Messdateneinträgen bezeichnet das System als eine Datenspur. Das Datenbankschema ist flexibel und daher nicht nur für hydrologische und meteorologische Daten, sondern jegliche Form von Messdaten geeignet.
SQL Server versus Table Storage
Als Datenbank kommt bisher SQL Server 2008 R2, zukünftig SQL Server 2012 zum Einsatz. Der Optimierung der Datenbankzugriffe kam bei der zu verwaltenden Datenmenge eine besondere Bedeutung zu. 95 Prozent der Datenzugriffe erfolgen über Microsofts Objekt-Relationalen-Mapper Entity Framework. Nur in etwa 5 Prozent der Fälle mussten andere Verfahren wie Stored Procedures, Bulk Import oder direkte SQL-Befehle eingesetzt werden, die einen unmittelbaren und daher schnelleren Draht zur Datenbank bieten.
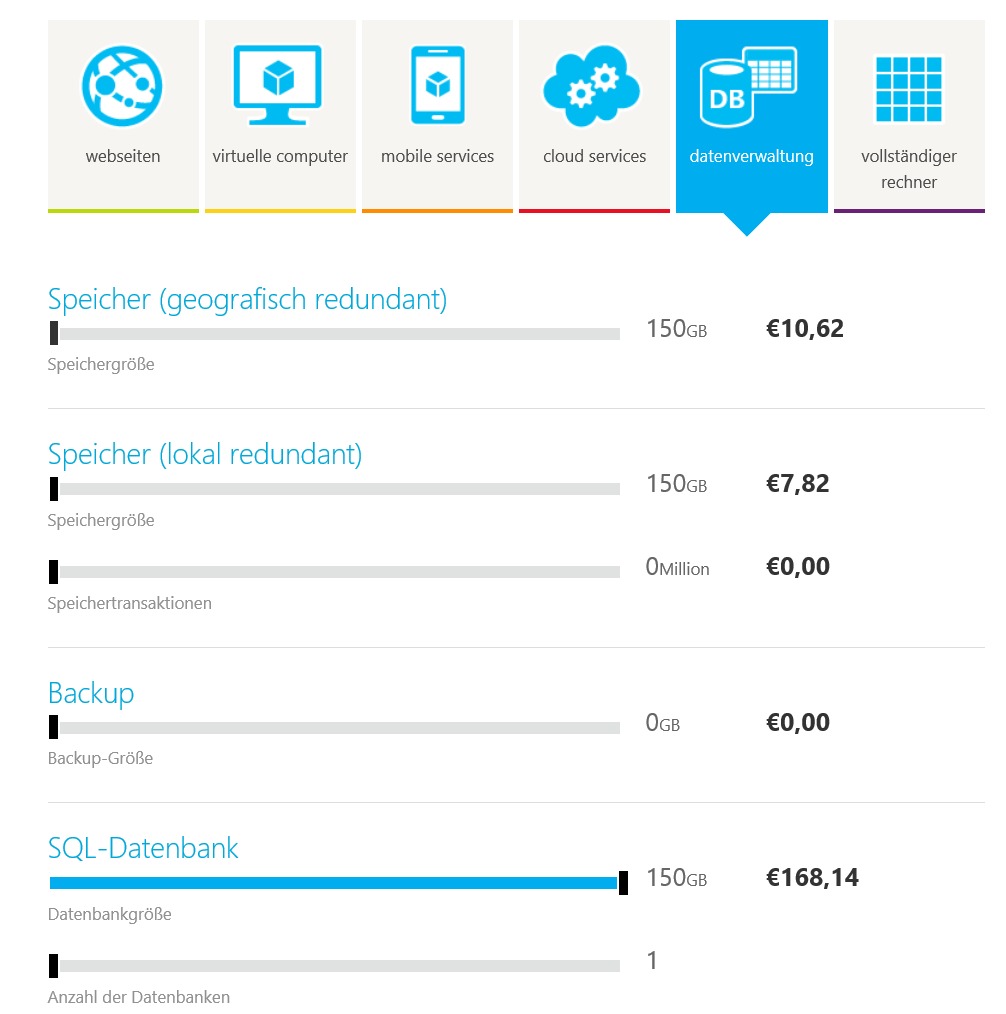
Im Cloud-System ist die Datenmenge wesentlich geringer, da hier keine Rohdaten, sondern nur geprüfte Daten bereitstehen. Windows Azure bietet auch eine abgespeckte Version des SQL Server als Datenspeicher unter dem Namen Windows Azure SQL Database an, die man direkt befüllen oder via SQL Data Sync mit lokalen SQL-Server-Datenbanken synchroniseren kann. Im Hochwasserportal des NLWKN fiel die Wahl aber auf die Redmonder Implementierung einer nicht-relationalen NoSQL- Datenbank, den Windows Azure Table Storage. Neben schnelleren Zugriffszeiten bietet Microsoft beim Table Storage auch einen viel günstigeren Preis. Der Preiskalkulator in Abbildung 4 zeigt für 150 GByte im Table Storage einen Preis von 10,62 Euro im Monat. Für die gleiche Datenmenge in SQL Azure wäre monatlich fast 16-mal so viel fällig. 150 GByte sind auch das Maximum, was man in einer SQL-Azure-Datenbank speichern kann. Bei Table Storage kommt man hingegen bis 100.000 GByte und muss mit Mengenrabatt 5605,57 Euro im Monat zahlen. Beim Verzicht auf geografische Redundanz in mehreren Kontinenten sinkt der Preis für 150 GByte Table Storage sogar auf 7,82 Euro/Monat.
Die vom In-House-System gelieferten Messdaten wandern in Windows Azure nicht sofort in die
Datenbank, denn absolute Priorität hat der Lesezugriff auf die Daten. Der Benutzer der Website soll lieber Daten sehen, die älter als 30 Minuten sind, statt gar keine Daten vorzufinden, denn Wasserstandsdaten ändern sich nicht so rasant. Daher landen alle neuen Messdaten zunächst im Rahmen einer "Azure Worker Role" in einer Warteschlange (vgl. Queue Services Concepts), die die Daten dann sukzessive im Table Storage ablegt.
Eine "Web-Rolle" hostet dann die in ASP.NET geschriebene Website sowie Webservices auf Basis der Windows Communication Foundation (WCF), die Daten zu Gadgets und Apps liefern.
Automatische Skalierung
In Friedenszeiten nutzt das NLWKN nur vier Server, jeweils zwei Instanzen für die Worker-Rolle und zwei Instanzen für die Web-Rolle. Das reicht, damit Microsoft eine Verfügbarkeit von 99,95 Prozent im Service Level Aggreement (SLA) zusichert. Die Server langweilen sich meist. Sollte aber im Hochwasserfall das Interesse steigen und die Server vorher definierte Belastungsgrenzen überschreiten, sorgt ein eigens für den Zweck entwickelter "Scale Agent" für die vollautomatische Hinzubuchung weiterer Server. Die Bereitstellung weiterer Server dauert nur 10 bis 15 Minuten. Microsoft bietet für die komplette Verwaltung der Server eine API auf Basis von REST-Webservices zum Zugriff auf die sogenannten Azure Management Services. Die definierbaren Schwellenwerte können sich auf Aspekte wie CPU-Auslastung, freien Hauptspeicher, Anzahl der Anfragen pro Sekunde oder auf die Anzahl der Anfragen pro Sekunde, die sich nicht sofort beantworten ließen, beziehen. Beim Unterschreiten von Schwellenwerten erfolgt ebenfalls automatisch die Freigabe von Servern.
Der Scale Agent wird auf einer der verfügbaren Worker-Instanzen in der Cloud selbst ausgeführt. Wird dieser Server heruntergefahren oder stürzt der Scale Agent aus irgendeinem Grund ab, übernimmt eine andere Instanz dessen Aufgabe (Failover). Er ließe sich jedoch auch in einer eigenen Rolle mit eigenen Instanzen ausführen.
Außerdem ist ein manuelles Skalieren über das Azure Management Portal möglich. Auch die selbstentwickelte WPF-Anwendung für Pegelbearbeiter und HWVZ erlaubt die Steuerung der Skalierung. Zielsetzung ist es, die Nutzungsgebühren so niedrig wie möglich zu halten, indem nur wirklich benötigte Ressourcen in Anspruch genommen werden, wobei Rechenzeit stundenweise abgerechnet wird. Microsoft bietet neben der Möglichkeit der Abrechnung am Monatsende auch Prepaid-Tarife an.
