

Data Mesh: Daten verantwortungsvoll dezentralisieren
Seite 3: Übergang zu domänenorientierten Datenprodukten
Indem Unternehmen ihre Daten anstelle eines Monolithen nach Domänen organisieren, können sie ihre Domänen-Expertise mit den technischen Fähigkeiten kombinieren, und so einen unternehmerischen Mehrwert generieren. Unter dem Kriterium der Domäne lassen sich Daten zu einem Portfolio diskreter Produkte bündeln. Jedes erfolgreiche Produkt muss seine Kunden begeistern, in diesem Fall die breitere Organisation: Data-Teams und alle anderen, die damit arbeiten müssen.

Wie aber gelingt es, Produkte zu erschaffen, die begeistern? Ganz einfach: Indem die Fülle an Wissen einfließt, die das Produktdenken bietet. Wenn Unternehmen außerdem verteilte Data-Teams mit entsprechendem Fachwissen ins Leben rufen, entfällt ein Großteil der bei Extraktion, Bereinigung und Analyse der Daten sonst üblichen Reibungsverluste.
Wie man den erfolgreichen Umgang mit Daten skaliert
Damit solch ein dezentraler und domänenorientierter Ansatz Erfolg haben kann, müssen Datenprodukte auffindbar, adressierbar, interoperabel, selbsterklärend, vertrauenswürdig und sicher sein. Sind alle diese Eigenschaften gegeben, lässt sich das Modell skalieren.
Der wichtigste Gradmesser für den Erfolg eines Datenprodukts ist die Zufriedenheit der Datenkonsumierenden. Dann kann es auch sinnvoll sein, den Erfolg des Produkts klar und messbar zu definieren. Ein naheliegender Leistungsindikator wäre zum Beispiel die Vorlaufzeit, die ein an Daten interessiertes Team benötigt, um die relevanten Daten zu finden und zu nutzen.
Durch Verknüpfung interoperabler Daten einen intelligenten Datenkreislauf entwickeln
Eines der zentralen Merkmale des Data Mesh ist sein Federated-Governance-Modell, das Interoperabilität durch Standards erreicht. Nur mit interoperablen Daten können Analysen unter Einbeziehung mehrerer Datenprodukte zu nützlichen Erkenntnissen und Handlungen führen. Sie jedoch beeinflussen bereits die nächste Datenverwendung. So entsteht ein zusammenhängender intelligenter Datenkreislauf.

Umstellung auf eine dezentrale Datenverantwortung
Unabdingbar ist darüber hinaus, dass sich die Datenproduzierenden für ihre eigenen Daten verantwortlich fühlen. Auch sind Entscheidungen darüber zu treffen, welche Daten zu speichern sind. Denn Daten zu extrahieren und zu transformieren, die niemand je nutzt, verursacht unnötige Kosten. Nach der Entscheidung, welche Daten den Stakeholdern zugänglich sein sollen, obliegt fachlichen Teams die Verantwortung, sie zu pflegen und zu analysieren. Der Datenqualität fällt damit die Rolle eines Vertrags zu zwischen Datenkonsumierenden und -produzierenden.
In der Umstellung von zentraler Datenverantwortung auf ein dezentrales Modell kann auch eine Lösung für den Engpass im Bereich Data Engineering liegen. Allerdings ist diese Lösung im Wesentlichen eine organisatorische. Während es vorher vielleicht niemanden gegeben hatte, der die uneingeschränkte Verantwortung für die Domänendaten trägt, sind die neuen Datenprodukte quellenbezogen und die Verantwortung verbleibt nun für den gesamten Lebenszyklus des Datenprodukts bei der Domäne.
Und wie sieht es mit bestehenden Infrastrukturen aus?
Bei der Evaluierung des Data-Mesh-Konzepts könnten Entscheiderinnen und Entscheider befürchten, dass etwaige kürzlich getätigte Investitionen – beispielsweise in einen Data Lake – sich als überflüssig erweisen, oder dass in einem verteilten System jedes Datenprodukt seine eigene separate Infrastruktur benötigen würde.
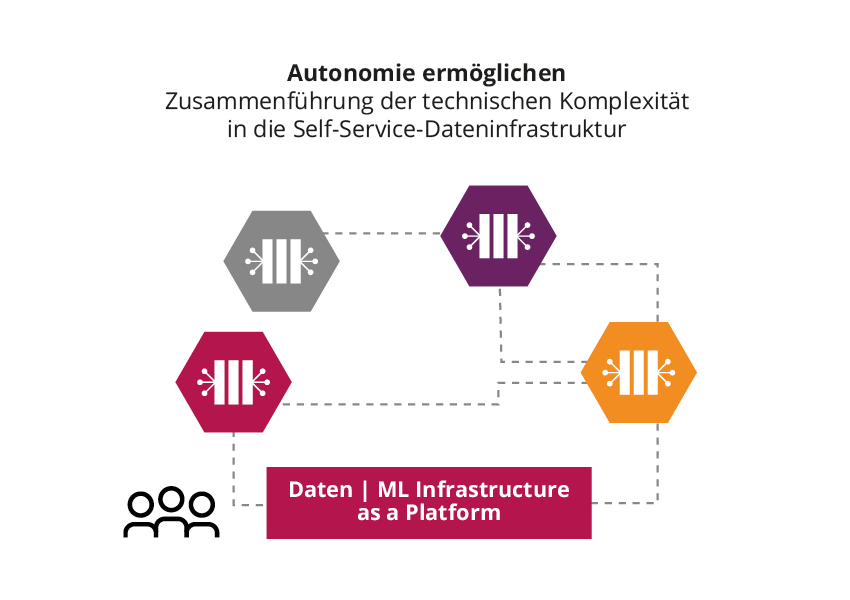
Data Mesh löst diese Probleme, indem es die Dateninfrastruktur als Plattform anbietet. So muss nicht jedes Domänen-Team seine eigene Datenplattform entwickeln, die notwendige Infrastruktur steht in Form einer Self-Service-Plattform bereit. Den Teams gibt das ein hohes Maß an Autonomie und es ermöglicht gleichzeitig die Integration zentraler Assets wie eines bestehenden Datenkatalogs.
Implementierung und organisatorischer Wandel
Im Data Mesh sollten Datenproduzierende und -konsumierende so eng wie möglich zusammenarbeiten. Im organisatorischen Idealfall verwendet ein datenproduzierendes Team die Daten selbst, ist also auch Konsument, sodass Datenverantwortung und Kompetenz vereint sind. Oftmals jedoch erfordern die vielen Aufgaben datenproduzierender Teams eine Aufteilung der Rollen auf zwei Teams – Produzierende und Konsumierende –, die fortlaufend direkt miteinander kommunizieren.
Es ist also nicht nur der Technologie-Stack, der sich ändern muss, auch Zuständigkeiten und Strukturen müssen sich verschieben. Dieser Wandlungsprozess erfordert die Zustimmung der obersten Führungsebenen im Unternehmen. Durch eine Implementierung in kleinen Schritten lässt sich der Wandel inkrementell umsetzen. In der Übergangsphase – also vor Fertigstellen einer Infrastructure-as-a-Service-Plattform (IaaS) – bilden sich Teams um Domänen herum, die bei Bedarf ein Data Warehouse oder einen Data Lake als Zwischenquelle nutzen.
Zwar erfordert die Erstellung der IaaS-Plattform die gleichen Data-Engineering-Fähigkeiten, die häufig zum Engpass in einer Data-Warehouse- oder Data-Lake-Architektur führen. Jedoch sind Domänenwissen und Infrastruktur voneinander entkoppelt, sobald die Plattform etabliert ist. Zentrale Data-Teams müssen sich nachfolgend nicht mehr mit dem Domänenwissen auseinandersetzen, um ihre Arbeit zu erledigen. Das reduziert den Druck, der beim Betrieb monolithischer Systeme entsteht.
