

Datenanalyse mit R, Teil 2
Seite 3: Prognose, Test und Fazit
Prognose und Test
Um das Zahlverhalten eines Kunden aufgrund seiner Zahlungshistorie vorherzusagen, ist eine sogenannte Prädiktor-Funktion von Nöten. Als Input dienen die Attribute des Verkaufsauftrags (in unserem Fall der Kunde und das DeliveryDate). Intern benutzt sie die abgeleiteten Attribute (Datenobjekt Pd). Eine einfache Prädiktor-Funktion ergibt sich beispielsweise aus den zuvor berechneten Mittelwerten der Zeitreihen der einzelnen Kunden.
Um eine Funktion in R zu definieren findet der Befehl function(arg1,arg2,...) Verwendung. Die angestrebte Funktion sollte als Input-Argument die Kunden-ID verwenden und als Ergebnis die wahrscheinlichste Dauer bis zum Zahlungseingang zurückgeben. Um die Vorhersage aussagekräftiger zu gestalten, soll außerdem die Standardabweichung erscheinen, da die Aussage, der Kunde zahlt innerhalb von 21 Tagen, nicht viel Wert ist, wenn die Vorhersage zwischen sieben Tagen und einem Jahr schwankt. Aus diesen Voraussetzungen ergäbe sich die folgende Prädiktor-Funktion:
# define predictor
predict.payDur <- function(ID) {
i <- match(ID, Pd$Customer, nomatch = 0)
if(i==0) {
# unknown customer, best guess:
# return mean value and standard deviation of
# all historical PaymentDuration
payDur.mean <- mean(unlist(Pd[,"TimeSeries"]))
payDur.sd <- sd(unlist(Pd[,"TimeSeries"]))
} else {
payDur.mean <- Pd[Pd$Customer == Pd$Customer[i], "Mean"]
payDur.sd <- Pd[Pd$Customer == Pd$Customer[i], "StdDev"]
}
return(c(payDur.mean, payDur.sd))
}
In der ersten Zeile bestimmt das Skript mit dem Befehl match(), ob die übergebene ID einem bereits bekannten Kunden zuzuordnen ist. Ist dem so, werden seine mittlere Zahlungsdauer und die Standardabweichung aus dem Modell PD zurückgeliefert. Ist es ein unbekannter Kunde, gibt die Funktion den Mittelwert und die Standardabweichung aller Zahlungen zurück.
Mit der definierten Prädiktor-Funktion lässt sich das Modell jetzt testen. Dafür sind nur Daten zu nutzen, die bei der Modellerstellung nicht berücksichtigt wurden. Würde ein Modell auf den gleichen Daten getestet, die man auch für die Modellerstellung verwendet, würde der Test immer die Modellannahmen bestätigen, da sie ja aus diesen Trainingsdaten hervorgegangen sind. Das folgende Beispiel (in der Datei createTestData.R abzuspeichern) generiert deshalb einige Testdaten:
# create some sample SalesOrders for testing
set.seed(1234) # set seed for random number generation
d0 <- as.Date("1970-01-01") # set constant: begin of date
date.min <- as.Date("2012-07-01") # earliest date for SalesOrder
date.max <- as.Date("2012-08-31") # latest date for SalesOrder
nr <- 1000 # create 1000 SalesOrders
# select 1000 customer IDs randomly
cust.test <- round(runif(nr, min=1001, max=1100))
# create 1000 dates randomly between earliest and latest date
date.test <- d0 + round(runif(nr, min = date.min-d0,
max = date.max-d0))
# create 1000 total prices randomly
total.test <- 10000+round(rnorm(nr, mean=10000, sd=5000))
# combine all data into a data.frame
SO.test <- data.frame(Customer=cust.test,
DeliveryDate=date.test,
TotalPrice=total.test)
Soll die Prädiktor-Funktion auf die so erzeugten Daten angewendet werden, ergibt sich:
# apply predictor
cust.pred <- t(sapply(SO.test$Customer, FUN=predict.payDur))
# enhance sample SalesOrder with predicted attributes
SO.test <- cbind(SO.test,
predict.pd.mean=cust.pred[,1],
predict.pd.sd=cust.pred[,2],
predict.date=SO.test$DeliveryDate+cust.pred[,1]
)
Da die Funktion predict.payDur() einen Vektor mit zwei Elementen zurückliefert und sapply() sie 1000-mal aufruft (für jeden einzelnen Verkaufsauftrag aus dem Data Frame SO.test), entsteht als Ergebnis eine 2x1000-Matrix. Sie lässt sich mit dem Befehl t() transponieren.
Um nun zu ermitteln, wie viele Einnahmen über die nächsten Monate aus bestehenden Forderungen an Kunden zu erwarten sind, addiert man beispielsweise alle vermuteten Zahlungen pro Woche auf und plottet das Ergebnis. Dafür ist zunächst die Woche aus dem vorhergesagten Zahlungsdatum zu bestimmen und dem Testdatensatz mit format() hinzuzufügen:
SO.test$predict.week <- as.numeric(format(SO.test[,6], "%W"))
Anschließend summiert aggregate() alle Preise einer bestimmten Woche auf:
# plot sum per week
sum.week <- aggregate(x=SO.test$TotalPrice,
by=list(SO.test$predict.week), FUN=sum)
names(sum.week) <- c("predicted.week","TotalSum")
plot(sum.week, type="b"))
Das Resultat lässt sich in Abb. 4 betrachten.
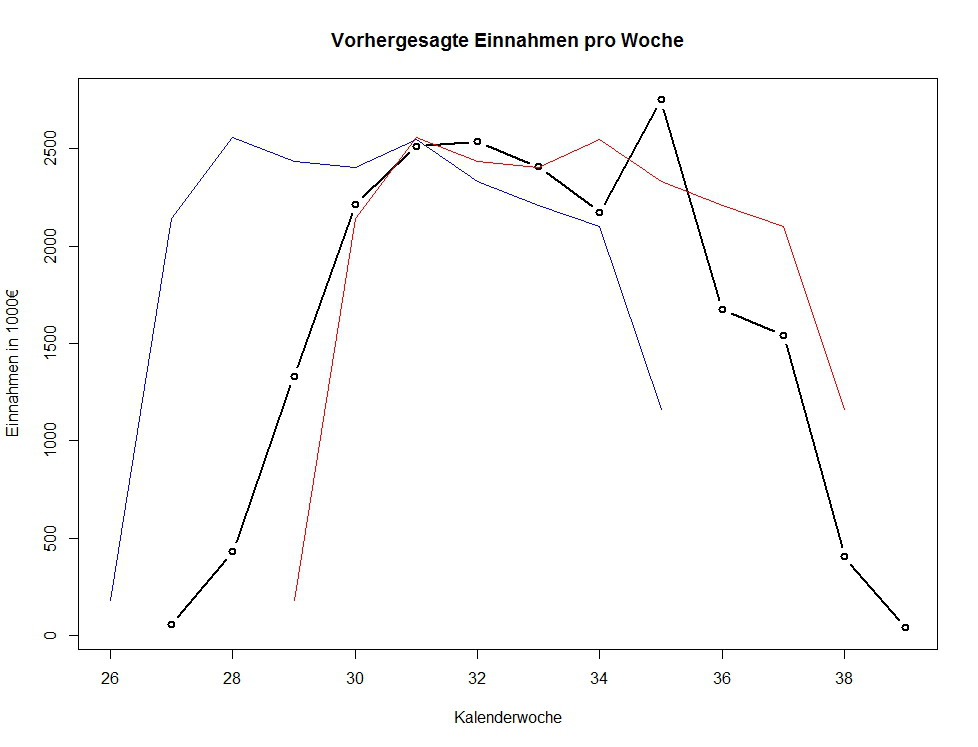
Die Kurve zeigt in Schwarz die Vorhersage der Einnahmen pro Kalenderwoche für die offenen Aufträge. In Blau und in Rot sind alte Abschätzungen für die minimale und maximale Zahlungsdauer gezeigt. Der Darstellung lässt sich entnehmen, dass in KW 28 circa 500.000 Euro eingenommen werden. Nach der früheren minimalen Abschätzung (in Blau), sollen laut Modell bereits Einnahmen in Höhe von 2,5 Millionen Euro vorliegen. Ein Unterschied von 2 Millionen Euro! Das maximale Modell sagt in KW 28 dagegen überhaupt keine Einnahmen voraus.
Dieses Ergebnis soll hier genügen. In der Realität fehlen jedoch ein paar Dinge: Zum einen wurde keine Fehlerbetrachtung der Abschätzung durchgeführt, zum anderen benötigt man noch einige Funktionen zur Ermittlung der Güte des vorliegenden Modells. Außerdem flossen nur drei Parameter in die Modellerstellung ein. Typischerweise unterscheiden sich die Kunden aber viel stärker. Es wird länderspezifische Zahlungsverhalten ebenso geben wie Abhängigkeiten anderer Merkmale, wie ob es sich um einen Großkonzern, Mittelständler oder sogar einen Privatkunden handelt. Zuletzt sei noch angemerkt, dass ein konstantes Zahlverhalten (wie in der durchgeführten Analyse) der Kunden in der Regel nicht zugrunde zu legen ist.
Fazit
Die analytischen und statistischen Möglichkeiten, die die Sprache R bietet, sind sehr umfangreich und werden durch eine aktive Community ständig erweitert. Neue Algorithmen im Bereich Data Mining werden häufig als erstes in R implementiert, was die Sprache besonders interessant macht. Sie ist frei verfügbar und hilft sowohl bei der Bildung von Modellen als auch bei deren Auswertung.
Dr. Ralf Ehret
arbeitete von 1991 bis 1998 am europäischen Teilchenforschungszentrum CERN an Datenanalysen bevor er zur SAP AG wechselte. Dort beschäftigte er sich unter anderem mit dem Thema Predicitve Analytics für die HANA-In-Memory-Technik.
Benjamin Graf
entwickelt als Data Scientist bei der SAP AG statistische Algorithmen und Prognosemodelle auf der HANA-Plattform. Vor seiner Tätigkeit bei SAP beschäftigte er sich an der Universität von Edinburgh mit automatischer Übersetzung und maschinellem Lernen.
Literatur
- H. Steinhaus; Sur la division des corps matériels en parties; Bull. Acad. Polon. Sci.. 4, p. 801-804, 1957
- C. Fraley, A. E. Raftery; MCLUST Version 3 for R: Normal Mixture Modeling and Model-Based Clustering; Technical Report no. 504, 2006, revised 2010
- C. Fraley, A. E. Raftery; Model-based clustering, discriminant analysis, and density estimation; Journal of the American Statistical Association 97, pp. 611-631, 2002
- R. I. Kabacoff ; R in Action – Data analysis and graphics with R; Manning, 2011
- S. P. Lloyd; Least squares quantization in PCM; IEEE Transactions on Information Theory. 28, p. 129-137, 1982
- S. P. Lloyd; Least square quantization in PCM ,1957
- J. Adler; R in a Nutshell – A Desktop Quick Reference; O'Reilly, 2010
- R-Manual: An Introduction to R
