

Fachliche Schulden als Kontrapunkt zu "Technical Debt"
Seite 2: Schulden analysieren
Um diese Fragen zu beantworten, soll folgendes reales Beispiel betrachtet werden. Ein Eisenbahnunternehmen arbeitet mit mehreren Teams an der Neuimplementierung eines größeren Softwaresystems. Wer ein System für ein solches Unternehmen entwickelt, modelliert (manchmal nicht so) offensichtliche Dinge wie Zugfahrten, Segmente, Abschnitte, Halte oder Bahnhöfe.
Das Projekt hatte das System in unterschiedliche Kontexte gegliedert. Die darin verankerten Anwendungsfälle basierten auf unterschiedlichen Modellen von Zugfahrten. In einem Kontext bestand eine Zugfahrt aus einer Sequenz von Halten. Ein Halt bezog sich auf einen Bahnhof sowie eine Abfahrts- und Ankunftszeit. In einem anderen Kontext nutzte ein Anwendungsfall ein Modell, in dem eine Zugfahrt aus einer Sequenz von Abschnitten bestand. Ein Abschnitt hatte einen Abfahrts- und Ankunftsbahnhof jeweils mit Abfahrts- und Ankunftszeit. In anderen Kontexten wiederum bestand eine Zugfahrt aus einer Sequenz von Segmenten und jedes Segment aus einer Sequenz von Abschnitten. Wieder andere hatten Segmente, die aus Halten bestanden.
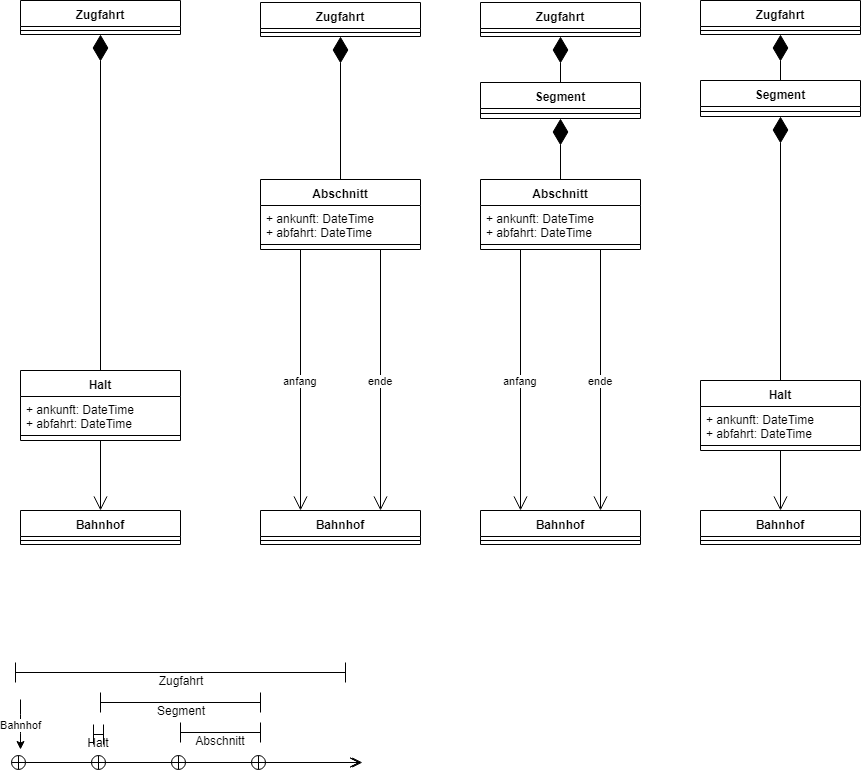
Manchmal sahen die Modelle austauschbar aus, obwohl sie sich in Feinheiten unterschieden. Beispielsweise lässt sich eine Sequenz von Abschnitten in eine Sequenz von Halten umrechnen. Je nach Kontext war das eine oder andere Modell jedoch geeigneter für den jeweiligen Anwendungsfall.
Eines der Teams tat sich schwer mit der Implementierung eines Anwendungsfalls. Sie fühlte sich sperrig an, und jede Änderung an der Software dauerte länger als erwartet. Das Team führte einige Diskussionen dazu mit einem der Architekten und diese führten zu einem neuen Modell. Im Kern stand ein neues UML-Klassendiagramm, mit dem alle Beteiligten zufrieden waren. Letztlich kam es zu einer hohen Aufwands- und Kostenschätzung für ein Refactoring, das im Wesentlichen einer Neuimplementierung einiger Kernmodule gleichkam. Aufgrund des hohen Aufwands sollte ein inkrementeller Weg zum Refactoring gefunden werden, der einige schnelle "Quick Wins" erlauben sollte.
Ein Lernprozess
So wurde zunächst der Code analysiert und insbesondere die Historie sämtlicher Änderungen am Code. Dabei ließen sich einige Hotspots ermitteln. Es handelte sich um Teile des Codes, die eine hohe Komplexität beziehungsweise hohe Kopplung aufwiesen sowie oft und von fast allen Entwicklern verändert wurden. Weitere Analysen der Hotspots und deren Veränderungshistorie ergaben weitere spannenden Einblicke. Beispielsweise gab es folgende Methode:
List<Abschnitt> getAbschnitte() {
return getSegmente()
.map(segment -> segment.getAbschnitte().stream())
.collect(Collectors.toList();
}
Die Methode wurde im Rahmen einer Delta-Berechnung genutzt, die zum Beispiel bei der Planung neuer Halte einer Zugfahrt zum Einsatz kommt:
List<Delta> calculateDelta(Zugfahrt base, Zugfahrt new) {
return calculateDelta(base.getAbschnitte(), new.getAbschnitte()) {
}
Darüber hinaus ließ sich folgende Zeile finden:
List<Abschnitt> abschnitteAdded = detectAbschnitteAdded()
Sie nutzte die oben genannte calculateDelta-Methode. Bei weiterer Betrachtung der Änderungshistorie fiel folgende kleine Änderung an der Zeile auf:
List<Abschnitt> halteAdded = detectAbschnitteAdded()
Es stellte sich die Frage, ob hier ein Algorithmus auf Basis von Abschnitten oder von Halten für die Berechnung der Deltas sinnvoller war. Mit der Änderung ging eine weitere in der calculateDelta-Methode einher:
List<Delta> calculateDelta(Zugfahrt base, Zugfahrt new) {
return calculateDelta(calculateHalteFrom(base.getAbschnitte()), calculateHalteFrom(new.getAbschnitte()));
}
List<Stop> calculateStopsFrom(List<Section> sections) {
// ...
}
Noch später in der Änderungshistorie gab es eine Änderung, die den betrachteten Hotspot in eine andere Klasse verschob und umformulierte:
List<Halt> halteAdded = detectHalteAdded();
Auf den ersten Blick sahen die Änderungen aus wie ein einfaches Refactoring. Die Delta-Erkennung wurde von einem auf Abschnitten basierenden auf einen auf Halten basierenden Algorithmus umgestellt. Allerdings war nun die Codebasis durchzogen mit Transformationen hin und zurück von Segmenten auf Abschnitte und diese wiederum auf Halte.
