

From Task 'til Dawn – Tasks versus Threads
Seite 2: Zöpfe abschneiden
Zurück zu den Tasks. So elegant sie auch erscheinen mögen, es gibt einen Punkt, an dem es zu viele werden und die Effizienz des parallelen Programms leidet! Betrachten wir noch einmal die rekursive Berechnung der Fibonacci-Zahlen in Abbildung 1 und analysieren, was in einem einzelnen Task an Arbeit erledigt wird. Es finden sich dort eine Ganzzahlsubtraktion und -zuweisung sowie ein Funktionsaufruf, der zur Rekursion führt. Dem steht für jeden einzelnen Task der Aufwand gegenüber, den die OpenMP-Laufzeitumgebung zu erledigen hat. Ohne an dieser Stelle näher ins Detail gehen zu können, ist nachvollziehbar, dass die Ausführung eines Tasks durch einen Thread (inklusive Vor- und Nachbereitung) mehr Aufwand mit sich bringt, als an eigentlicher Arbeit in einem Task im obigen Programm steckt.
Die ersten Tasks, die zu Beginn der Rekursion erzeugt werden, beinhalten in ihrer Ausführung die gesamten weiteren Tasks aus allen folgenden Rekursionsschritten. Diese Betrachtung der Ausführungszeit mitsamt allen enthaltenen Aufrufen wird in vielen Analysewerkzeugen als „inclusive time“ bezeichnet, die reine Ausführungszeit eines einzelnen Tasks ohne der enthaltenen Aufrufe als „exklusive time“. Um feststellen zu können, ob und wie weit sich Tasks lohnen, sind diese beiden Blickwinkel zu unterscheiden.
Die ersten beiden erzeugten Tasks machen mit der Summe ihrer "inclusive time" fast die gesamte Programmlaufzeit aus und sind somit sicherlich lohnend. Für die letzten Tasks, die keine weiteren Funktionsaufrufe mehr enthalten, sind "inclusive time" und "exclusive time" gleich und, wie oben diskutiert, ist der Mehraufwand wohl höher als die Ausführungszeit. Irgendwo dazwischen gibt es also einen Punkt, an dem genügend Tasks erzeugt wurden, um alle Threads und Rechenkerne gut zu beschäftigen, aber weitere Tasks nur noch Mehraufwand erzeugen. Zusätzlich zu obiger Daumenregel zur Größe eines Tasks gilt, dass mindestens zehnmal mehr Tasks erzeugt werden sollen als Threads eingesetzt werden.
Ab diesem Punkt gibt es dann genügend Tasks. Um in der Rekursion die Erstellung weiterer Tasks zu beenden, erlaubt OpenMP die Verwendung der if-Klausel („#pragma omp task if(condition)“ ). Ergibt die Auswertung der Bedingung ein negatives Ergebnis (also false), wird der Task direkt ausgeführt, was einen Großteil des Mehraufwands gegenüber einem regulär ausgeführten Task vermeidet. Im obigen Beispiel lässt sich die Abbruchbedingung beispielsweise so wählen, dass sie um einen konstanten Wert (zum Beispiel 12) kleiner ist als die Eingabe. Damit lassen sich auch für Vielkernsysteme noch genügend Tasks zur Ausführung bringen.
Möchte man den Mehraufwand komplett einsparen, sind weitergehende Anpassungen am Programmcode erforderlich. Mittels einer Verzweigung kann nach Erreichen der Abbruchbedingung eine serielle Version des Codes ausgeführt werden, der keine Task-Konstrukte mehr enthält.
Das Problem, dass die eigentliche Arbeit in einem Task abnimmt, während der Aufwand der Task-Ausführung gleich bleibt, tritt in fast jedem rekursiven Task-parallelen Programm auf. Die hier beschriebene Problemlösung der Einführung einer Abbruchbedingung, die in der Literatur auch als Cut-off bezeichnet wird, ist dann generell anzuwenden. Eine Herausforderung kann sich im Finden einer passenden Abbruchbedingung ergeben, wenn wenig Informationen über die erwarteten Eingabedaten vorliegen.
Abhängigkeiten
In der parallelen Programmierung kann leicht Chaos entstehen. Daher ist ab und an dafür Sorge zu tragen, dass Tasks nicht wild durcheinander ausgeführt werden, sondern in der richtigen Reihenfolge. Beispielsweise sollte ein Task, der gewisse Daten erzeugt, vor demjenigen Task ausgeführt worden sein, der diese Daten benötigt. Hierfür ist das Programm mit einer Synchronisation zu versehen, die genau das sicherstellt.
In der parallelen Programmierung gibt es unterschiedliche Mechanismen, wie diese Synchronisation auszudrücken ist. Es gibt Barrieren, die Threads solange aufhalten, bis alle Threads eines Teams ebenfalls an der Barriere angelangt sind. Dann gibt es natürlich noch Sperrobjekte (engl. Locks), die gegenseitigen Ausschluss realisieren. Spezielle Synchronisationskonstrukte für Task-parallele Programme sind Task-Barrieren und Task-Abhängigkeiten.
Abbildung 2 zeigt den Unterschied zwischen einer Task-Barriere (#pragma omp taskwait) und den mit OpenMP 4.5 eingeführten Task-Abhängigkeiten. Der linke Code erzeugt drei Tasks: lila mit einer langlaufenden Berechnung, sowie blau und rot. Der blaue Task berechnet einen Wert, den der rote Task nutzen möchte. Daher müssen wir die Ausführung von diesen beiden Tasks so trennen, dass der rote garantiert nach dem blauen anläuft.
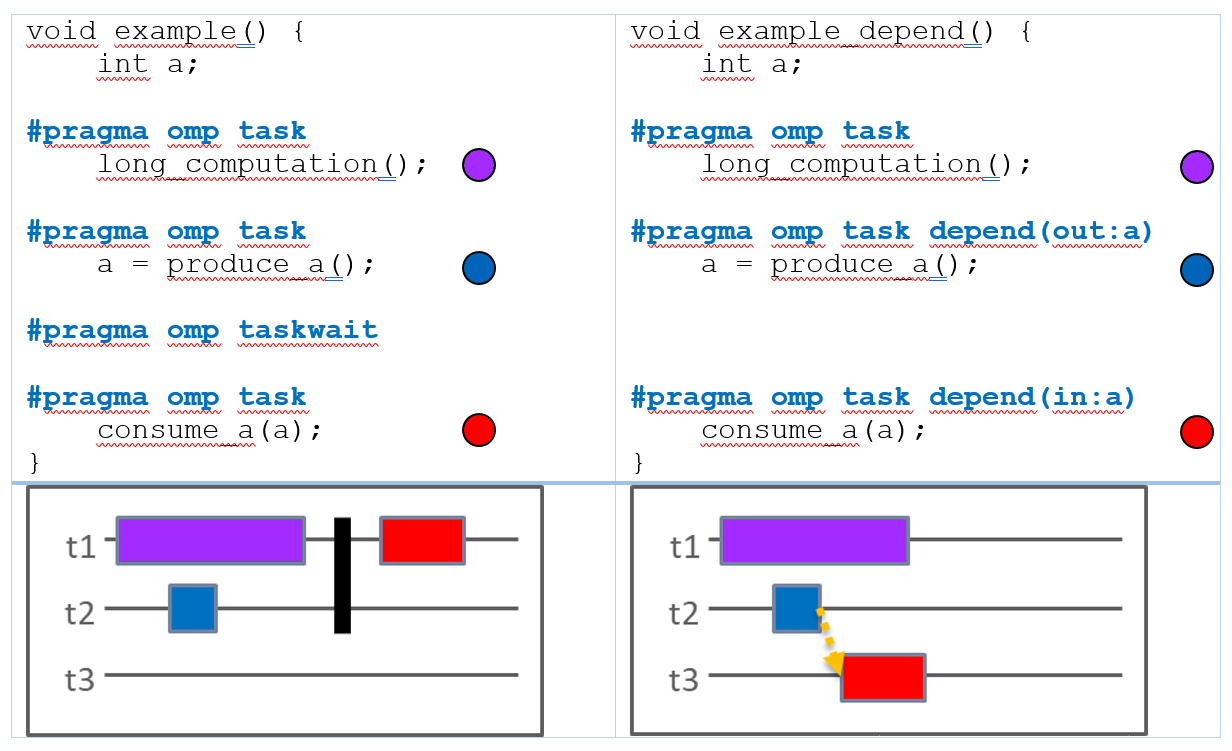
Im linken Code fügen wir zu diesem Zweck ein taskwait-Konstrukt ein. Damit wird der rote Task erst gestartet, wenn der blaue Task fertig gerechnet hat. Soweit so gut. Allerdings hat dieses Vorgehen den unschönen Nebeneffekt, dass der rote erst dann anläuft, wenn auch der lila Task seine Arbeit beendet hat. Da dieser im Beispiel ein Task ist, der sehr lange für die Berechnung benötigt, hält er den roten Task unnötig lange auf.
Der rechte Code nutzt dagegen zur Synchronisation die Task-Abhängigkeiten von OpenMP 4.5. Mittels der depend-Klausel wird ausgedrückt, dass der rote Task eine Abhängigkeit zum blauen Task hat. Dass Rot Daten liest, die Blau erzeugt, drückt man durch in und out aus. Das Schlüsselwort in bedeutet, dass ein Task erst dann mit der Ausführung beginnen darf, wenn alle Tasks abgeschlossen sind, die die gleichen Variablen als out-Abhängigkeiten haben. OpenMP unterstützt noch inout, das die Bedeutung von in und out in einem Wort zusammenfasst. Wie in der graphischen Darstellung in Abbildung 2 ersichtlich, vermeidet die Nutzung der Abhängigkeit das übermäßig lange Warten auf den lila Task.
