

GitOps in der Praxis
Den Lebenszyklus einer Software über Git abzubilden, hat zahlreiche Vorteile für Softwareentwickler.

(Bild: bearsky23/shutterstock.com)
- Jan Gertgens
Typische Softwareprojekte nutzen zahlreiche Werkzeuge zum Bau und zur Installation von Software, die zudem über viele Server in der Infrastruktur verteilt sind. Eine Pipeline besteht in der Regel aus einem CI-Server, einem Sourcecode-Repository, einem Artefakt-Server und gegebenenfalls einem Server zur Unterstützung beim Ausrollen.
Meist sind der Code der Build Jobs, die Deployment-Konfigurationen der Anwendungen und die Beschreibung der Infrastruktur unversioniert abgelegt. Das verhindert eine durchgängige Versionierung aller Artefakte des Softwareprojektes. Daraus ergibt sich ein höherer manueller Aufwand beim Verteilen und Testen der Software.
An der Stelle kommt GitOps ins Spiel. Das Verfahren sorgt dafür, dass der gesamte Inhalt eines Projektes als sogenannte Single Source of Truth (SSOT) in der Versionsverwaltung Git liegt. Ein Softwareentwicklungsprojekt dient im Folgenden als Beispiel für das Vorgehen.
Videos by heise
Gut versioniert
GitOps beschreibt ein Vorgehen, bei der das Source-Code-Verwaltungswerkzeug Git als zentrale Komponente dient, um den gesamten Lebenszyklus einer Software abzubilden. Das geht von der Entwicklung und dem Bau der Software über das Erzeugen der lauffähigen Artefakte bis zum Ausrollen und Warten. Die Beschreibung der Infrastruktur und der Konfiguration der Jobs zum Bauen der Software liegen ebenfalls als Source Code in Git. Dieses Vorgehen erhöht das Maß der Automatisierung der Deployments und der Installation der Infrastruktur.
Ein weiteres wichtiges Grundprinzip von GitOps ist das automatische Erkennen von Änderungen in der Beschreibung des Deployment oder des Sollzustands der Anwendung. Die Grundlage hierfür bildet die deklarative Beschreibung des Ausrollprozesses. Auf die Weise versucht beispielsweise Kubernetes anhand der Deklaration den beschriebenen Zustand des Deployment herzustellen. Das System überwacht ein zugehöriges Repository in Git und stellt bei jeder Änderung wie dem Hinzufügen weiterer Instanzen den neuen Zustand automatisch her.
Der ausschlaggebende Unterschied zwischen GitOps und dem Continuous-Integration-Verfahren CIOps ist die Art, wie Deployments angestoßen werden. GitOps setzt auf eine Überwachung des Infrastruktur-Repository und reagiert auf Änderungen des dort abgelegten Sourcecodes. Bei CIOps stoßen dagegen beispielsweise Trigger- oder Schedule-Jobs explizit das Ausrollen des Infrastruktur-Repository an.
Architektur des Projekts
Das Demoprojekt für diesen Artikel setzt sich aus gängigen Werkzeugen für die Softwareentwicklung zusammen. Als Zielplattform dient ein Kubernetes-Cluster. Das Beispiel richtet einen Spring-Microservice mit einer MongoDB im Cluster ein. Darüber hinaus dient die Webvariante von GitLab als Versionsverwaltung und die Docker-Registry zum Erstellen des Microservice, das GitOps-Werkzeug zum Überwachen des Repository und für das Deployment ist ArgoCD zuständig.

GitLab kommen im Projekt vielseitige Aufgaben zu. Es ist zunächst das Sourcecode-Repository und für das Erstellen der Anwendung verantwortlich. Zum Bau der Anwendung dienen Basis-Images von Docker Hub. Das Erstellen der Java-Archive als Executable JAR erfolgt mit einem maven:3.3.9-jdk-8-Image. Für das Docker Image greift ein docker:latest, das die benötigte Docker Executable enthält. Damit ergibt sich folgender Build Job:
stages:
- build
- docker
.docker: &docker
image: docker:latest
stage: docker
services:
- docker:dind
only:
- master
.build-maven: &build-maven
image: maven:3.3.9-jdk-8
stage: build
build-master:
<<: *build-maven
stage: build
script:
- 'mvn install'
only:
- master
artifacts:
paths:
- target/*.jar
docker-build-and-push:
<<: *docker
dependencies:
- build-master
script:
- docker login -u "$CI_REGISTRY_USER"\
-p "$CI_REGISTRY_PASSWORD" $CI_REGISTRY
- docker build -t\
registry.gitlab.com/artikel-gitops/refimpl:0.0.1-SNAPSHOT .
- docker push \
registry.gitlab.com/artikel-gitops/refimpl:0.0.1-SNAPSHOT
Nach dem Bau der Anwendung steht das Hochladen des Docker-Image in die private Docker-Registry des GitLab-Projekts an. Die Zugangsdaten für den Docker-Log-in stellt GitLab als Umgebungsvariablen zur Verfügung. Zum Ausrollen kommt ein eigens erstelltes Image zum Einsatz, das die CLIs (Command Line Interfaces) von Kubernetes und ArgoCD mitbringt. Des Weiteren müssen Entwickler die passende kubeconfig in das Image kopieren, um den Zugang zum Kubernetes-Cluster zu ermöglichen:
FROM ubuntu:18.04
COPY files/kubeconfig kubeconfig
ENV KUBECONFIG="kubeconfig"
# Install kubectl
RUN apt-get update && \
apt-get install -y apt-transport-https curl gnupg2
RUN curl -s \
https://packages.cloud.google.com/apt/doc/apt-key.gpg \
| apt-key add -
RUN echo \
"deb https://apt.kubernetes.io/
kubernetes-xenial main" \
| tee -a /etc/apt/sources.list.d/kubernetes.list
RUN apt-get update && \
apt-get install -y kubectl
RUN export VERSION=$(curl --silent \
"https://api.github.com/repos/argoproj/argo-cd/releases/latest"\
| grep '"tag_name"' | sed -E 's/.*"([^"]+)".*/\1/') && \
curl -sSL -o /usr/local/bin/argocd \
https://github.com/argoproj/argocd/releases/download/\
$VERSION/argocd-linux-amd64 && \
chmod +x /usr/local/bin/argocd
COPY scripts/* /usr/local/bin/
RUN chmod +x /usr/local/bin/prepareEnv
Kubernetes und ArgoCD
Das Aufsetzen des Clusters erfolgt mit der schlanken Kubernetes-Distribution k3s, die sich durch eine einfache Installation auszeichnet. Zusätzliche Konfigurationen oder Werkzeuge sind nicht erforderlich. Folgende Befehlszeile installiert den Cluster:
curl -sfL https://get.k3s.io | sh -.kubectl apply -f \
https://raw.githubusercontent.com/indeedeng/k8dash/\
master/kubernetes-k8dash.yaml
Ein zentrales Werkzeug des GitOps-Konzepts im Beispielprojekt ist der ArgoCD-Server. Er überwacht ein definiertes Git-Repository als Single Source of Truth, in dem der herzustellende Zustand der Anwendung als Sourcecode liegt. Helm ist im Projekt die Grundlage für die Deployments nach Kubernetes. Zunächst gilt es, die Repositories über die Oberfläche des ArgoCD zu konfigurieren.

Die Helm-Konfiguration für die Anwendung liegt direkt in einem Unterordner des Repository der jeweiligen Anwendung. Hinzu kommen zwei öffentliche Helm-Repositories für das Deployment der MongoDB. Die installierten Anwendungen lassen sich über ArgoCD-Projekte organisieren. Für die Verteilung der Anwendungen kommt ausschließlich das Default-Projekt von ArgoCD zum Einsatz. In der Oberfläche des ArgoCD-Servers sind die Zustände der installierten Anwendungen einsehbar, und die Projektübersicht lässt sich nach Namespaces, Labels, Clustern und ArgoCD-Projekten filtern.
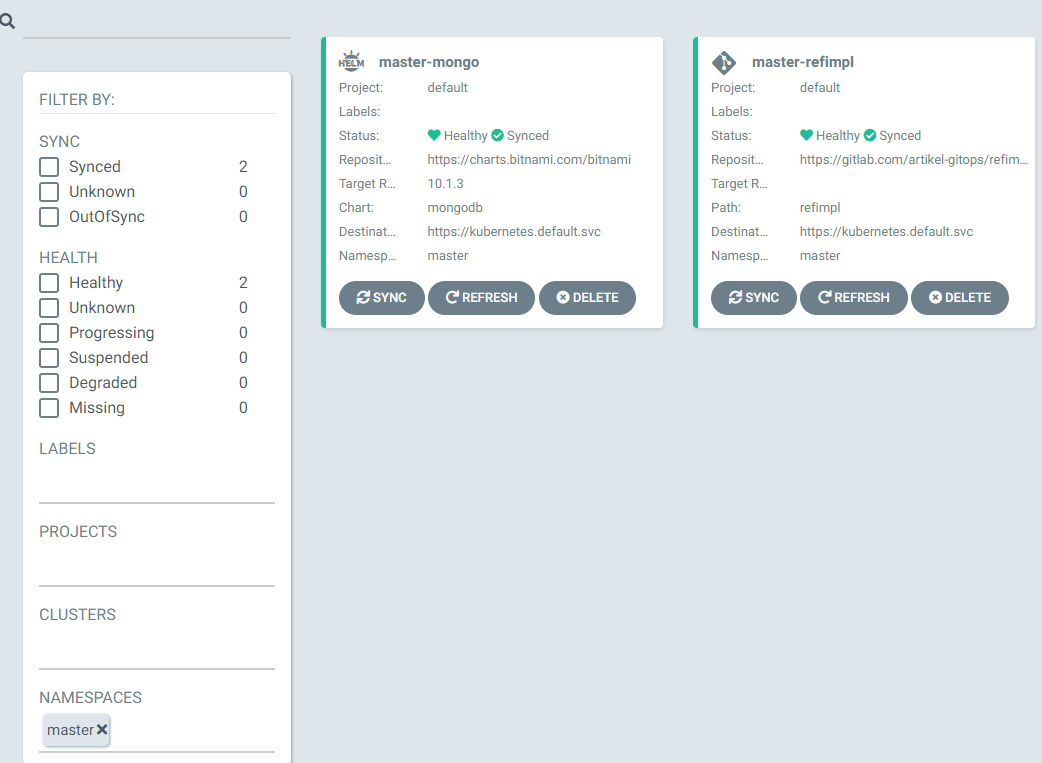
In der Detailansicht lässt sich der Status jeder installierten Kubernetes-Ressource darstellen. Nutzer können aus der Übersicht zudem eine manuelle Synchronisation anstoßen und einzelne Kubernetes-Ressourcen löschen.

Um die Überwachung eines Repository und das automatische Ausrollen zu konfigurieren, gilt es zunächst eine Anwendung mit dem passenden Sourcecode-Repository anzulegen. Es gibt zwei Wege, eine Anwendung in ArgoCD zu erstellen. Da sich das Erstellen über die Oberfläche schwer automatisieren lässt, nutzt das Beispielprojekt die zweite Variante, die eine Automatisierung über das ArgoCD-CLI ermöglicht. Die Anwendung erhält die Konfigurationen als Parameter. Der Zugriff über die Kommandozeile erfolgt im Projekt automatisiert mit einem Skript, um die Anwendung über Umgebungsvariablen im Kubernetes-Cluster zu installieren.
