

Herausforderung Brownfield, Teil 4: Komplexität bewältigen durch Differenzierung
Seite 3: Spezialisierte Datenmodelle
Spezialisierte Datenmodelle differenzieren die Domänenlogik
Erhält man den Auftrag für eine Anwendung mit einem Satz an Anforderungen, ist es nachvollziehbar, dass man dafür eine Lösung im Sinne eines Programms entwickeln will. Das eine Programm repräsentiert meist ein Datenmodell.
Es ist zum Beispiel bei einer Faktura-Anwendung naheliegend, dass das Datenmodell die Anforderungen von Rechnungslegung und Mahnwesen, Zahlungseingangsbuchung und Auswertung erfüllen muss. Schließlich hat sich der Kunde die Funktionen gewünscht. Daran ändert auch nichts, dass man Rollen identifiziert hat und die Anwendung partitioniert. Das eine Datenmodell, oft repräsentiert durch die reflexartige Entscheidung für ein relationales Datenbanksystem, wird es schon richten. Nur so ist Datenkonsistenz, Verfügbarkeit und Sicherheit gewährleistet – oder?
Es geht auch anders. Man nehme den einen Wunsch des Kunden nicht als Auftrag, eine Anwendung (gegliedert in mehrere Partitionen) zu liefern, und schaue genauer hin. Der Kunde selbst weiß es nicht besser, aber die Entwickler. Sie sollten die Anforderungen betrachten und sich fragen, ob damit wirklich eine Anwendung beschrieben ist oder ob es mehrere sind. Sie sollten besser davon sprechen, dass der Kunde ein Softwaresystem will, nicht eine Anwendung. In "System" steckt ja drin, dass es mehrere Funktionseinheiten geben kann, die im Sinne des Gesamtzwecks zusammenwirken.
Auch sollten Entwickler sensibel für die Sprache der Anforderungsdokumente sein. An ihnen haben viele Stakeholder mitgearbeitet, die alle nur das Beste für ihren Bereich wollen. Das führt – wie es bei Menschen und ihren Wünschen üblich ist – zu Widersprüchen; die einen wollen etwa Effizienz, die anderen Flexibilität. Das mündet aber auch in Missverständnissen. Die entstehen oft durch Homonyme, das heißt gleich klingende Worte, die Unterschiedliches bedeuten. Bei einer Faktura-Anwendung könnte das etwa der Begriff "Rechnung" sein.
Für die Rechnungslegung ist eine Rechnung ein Dokument, vergleichbar mit einem Word-Dokument, nur etwas strukturierter. Ein intelligentes Formular, das beim Ausfüllen hilft mit Zugriff auf Stammdaten von Kunden und Produkten. Für die Zahlungseingangsbuchung hingegen ist eine Rechnung nur ein Tupel bestehend aus Rechnungsnummer, -datum, -betrag, Zahlungsbedingung und vielleicht einer Kurzinformation über den Kunden. Für die Auswertung schließlich ist eine Rechnung vielleicht ein Tupel bestehend aus Umsatzdatum, Umsatz, Kosten, Umsatzregion.
Die Stakeholder dreier Rollen haben sich im Anforderungsdokument "verewigt" und dabei denselben Begriff benutzt: Rechnung. Ohne sich dessen bewusst zu sein, haben sie jedoch mehr oder weniger unterschiedliche Vorstellungen davon, was eine Rechnung ist. Deshalb sollten sich alle Begriffe in Anforderungsdokumenten mit ihren Rollen qualifizieren lassen (zum Beispiel Rechnungslegung.Rechnung, Zahlungseingang.Rechnung, Auswertung.Rechnung), solange nicht ausdrücklich klar ist, dass sie rollenübergreifend dasselbe bedeuten.
Derzeit ist das aber noch nicht der Fall und deshalb ist die Gefahr groß, dass Homonyme in Anforderungsdokumenten nicht erkannt werden. Das führt dazu, dass zwischen ihnen nicht zu unterscheiden ist und Entwickler versuchen, es allen Rollen mit dem einem Datenmodell rechtzumachen. Das führt nicht nur zu aufgeblähten Datenmodellen, sondern auch zu ineffizienten. Wieder sei das Beispiel Faktura-Anwendung herangezogen: Versucht man die Anforderungen an Rechnungslegung.Rechnung und Auswertung.Rechnung in einem (relationalen) Datenmodell zu erfüllen, kommt man wahrscheinlich auf eine von zwei Lösungen:
- Entweder berechnet man für die Auswertung Umsatz und Kosten aus den Rechnungspositionen, weil sich nur so der Forderung nach einer normalisierten Datenbank nachkommen lässt. Allemal zwängt man dafür Dokumente (Rechnungslegung.Rechnung) in ein relationales Schema. Das allein sollte schon Schmerzen bereiten.
- Oder man speichert Umsatz, Kosten und Zahlungseingänge denormalisiert – beispielsweise im Rechnungskopf. Dann widerspricht der jedoch dem Single Responsibility Principle – und das sollte auch Schmerzen verursachen.
Wie man es dreht und wendet, man wird immer wieder zu Kompromissen gezwungen, die Datenbanken und Datenobjektmodelle in die Unwartbarkeit treiben, wenn man Anforderungen als großes Ganzes sieht, dessen Lösung nur ein Datenmodell haben soll.
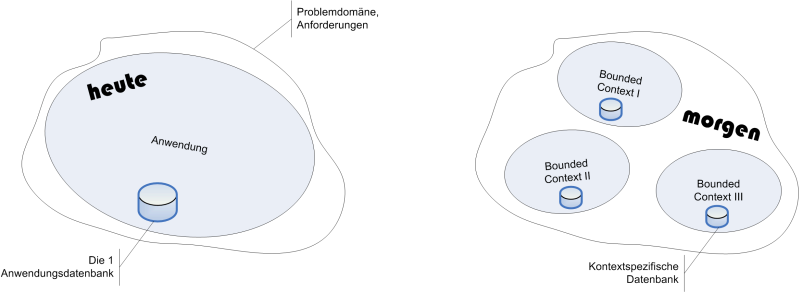
Stattdessen sollte der Entwickler die Grenzen zwischen den "Sprachgemeinschaften" der Stakeholder oder besser den "Begriffsgültigkeitsbereichen", kurz Kontexten, erkennen. Manche Begriffe sind wirklich universell, aber viele haben nur eine begrenzte Reichweite. Innerhalb der Anforderungen gibt es daher meist mehrere Kontexte, die so unterschiedlich sind, dass sie eine eigene Anwendung verdienen. Domain Driven Design (DDD) nennt die Kontexte Bounded Contexts (BC) und weist ihnen eigene Datenmodelle zu.
In der Faktura-Anwendung könnten etwa Rechnungslegung, Auswertung und Verwaltung (Mahnwesen, Zahlungseingang, USt-Voranmeldung, Datenexport) drei Bounded Contexts darstellen. Ihre jeweilige Sicht auf die Daten ist so anders, dass es sich lohnt, sie durch unabhängige Datenmodelle zu beschreiben und auch unterschiedliche Persistenzmedien zu benutzen. Für die Rechnungslegung könnte eine Dokumentendatenbank wie CouchDB optimal sein, die Auswertung könnte von einer OLAP-Datenbank profitieren, und die restlichen Partitionen setzen vielleicht auf ein RDBMS.

Partitionen dienen besserer Usability. Jede Rolle bekommt ein auf sie genau zugeschnittenes Frontend. Das wiederum dient der Modularisierung des Anwendungscodes. Bounded Contexts hingegen dienen nichtfunktionalen Anforderungen wie Performance oder Skalierbarkeit. Indem sie das Datenmodell modularisieren, schaffen sie es, innerhalb jedes Kontexts Struktur und Technik optimal für die darin enthaltenen Partitionen zu wählen. Das wiederum dient der Entkopplung von Daten und Code.
Die Vorteile der vielen Datenmodelle mit ihren optimalen Persistenztechniken haben allerdings ihren Preis. Der besteht nicht so sehr darin, sich potenziell in viele Techniken einarbeiten zu müssen. Er ist vielmehr in Form von explizitem Synchronisationsaufwand zu zahlen. Denn kontextspezifische Datenbanken enthalten oft Daten redundant. Noch einmal als Beispiel die Faktura-Anwendung: Im Verwaltungs- wie im Auswertungskontext geht es etwa um Rechnungsdatum und Umsatz. Ändern sich die Daten in einem Kontext, die für andere relevant sind, sind die betroffenen Kontexte zu synchronisieren.
Teilt man den Code in mehrere Bounded Contexts auf, muss der Entwickler zusätzlich Synchronisationscode schreiben. Beim einem traditionellen Datenmodell ist das, wenn er die Daten vollständig normalisiert hält, nicht nötig. Aber oft sind auch universelle Datenmodelle unsauber, das heißt denormalisiert, sodass dafür konsistenzsichernder Code zu schreiben ist, etwa in Form von Triggern.

Ist die Synchronisierung ein K.O.-Kriterium für Bounded Contexts? Nein. Erstens ist der Aufwand, der in die Synchronisation geht, wahrscheinlich geringer als der, der in die Wartung des einen undurchsichtigen universellen Datenmodells und des darauf basierenden Codes geht. Zweitens zeigt eine explizite Synchronisierung, was vorher unsichtbar war. Sie repräsentiert damit eine Erkenntnis, ist sozusagen aktives Wissens-Management, und sie ist Repräsentant der Grenze zwischen den "Kulturen des Umgangs mit Daten".
An der expliziten Synchronisierung hängt allerdings noch ein weiterer Preis, ihre Latenz. Daten sind nicht sofort, wenn sie persistiert wurden, softwaresystemweit verfügbar. Synchronisierung braucht ihre Zeit; das können Sekunden, Minuten oder Stunden sein. Arbeitet eine Projektteam mit Bounded Contexts, ist es gezwungen, sich auf Eventual Consistency einzulassen. Das ist aber nicht schlimm. Wenn es im Faktura Beispiel etwa fünf Minuten dauern sollte, bis eine neue Rechnung in der Verwaltung und der Auswertung ankommt, ist die Verzögerung aus Sicht der abhängigen Bounded Contexts nicht zu unterscheiden von einer Speicherung, die fünf Minuten später stattfindet.
Synchronisierung und Eventual Consistency sind also vergleichsweise kleine, dafür jedoch explizite Kosten im Vergleich zu den versteckten, kaum bezifferbaren Kosten, die undurchsichtige monolithische Datenmodelle verursachen.
