Mozilla DeepSpeech: Speech-to-Text Schritt für Schritt
Seite 2: Starten des DeepSpeech-Servers
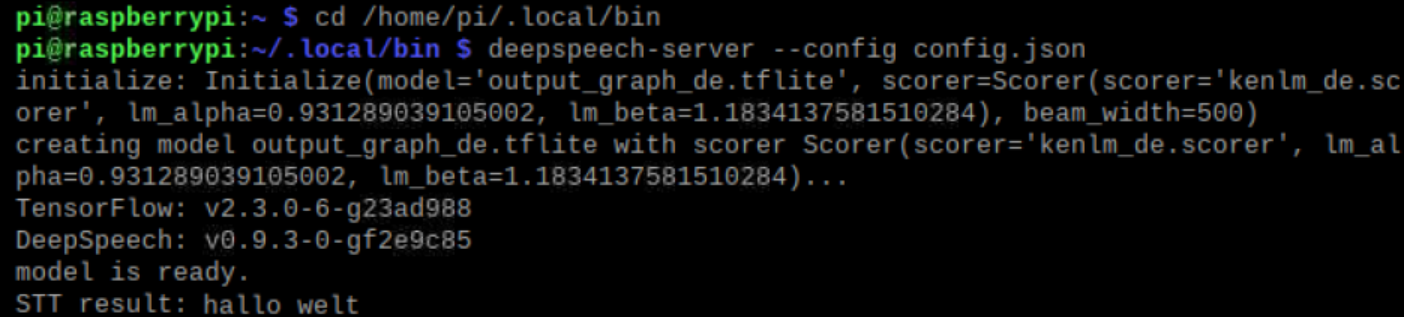
Um den Server zu starten, ist im Verzeichnis cd /home/pi/.local/bin der Steuerbefehl deepspeech-server --config config.json einzugeben.
Sollte der Fehler Original error was: libf77blas.so.3: cannot open shared object file: No such file or directory auftauchen, hilft der Befehl: sudo apt-get install libatlas-base-dev.
DeepSpeech-Aufruf
Um DeepSpeech per Curl aufzurufen, wird die IP des Raspberry-Servers benötigt sowie der Curl-Befehl: curl -X POST --data-binary @testfile.wav http://IP:8080/stt
DeepSpeech verlangt eine Sounddatei
Aktuell existieren keine nativen Java Libraries, um DeepSpeech zu nutzen. Es gibt lediglich eine Android-Bibliothek, die für Desktop-Anwendungen jedoch wenig hilfreich ist. Daher ist es erforderlich, DeepSpeech als Server aufzusetzen. Somit lässt sich eine Verbindung über HTTP aufbauen und ein eigenes Java-Programm entwickeln. Der Curl-Befehl lässt es schon vermuten: DeepSpeech verlangt eine Sounddatei im WAV-Format, die entgegengenommen, interpretiert und dann als Text zurückgeliefert wird. Das nachfolgende Programm geht genauso vor.
Blick in die Bibliothek
Zunächst sind zwei Bibliotheken notwendig. Beide befinden sich im Maven Central Repository und lassen sich einfach ins Project Object Model (POM) einbinden:
<dependencies>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.13</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.8.0</version>
</dependency>
</dependencies>Ans Eingemachte mit Java
Der nachfolgende Code ist vereinfacht dargestellt: Exception Handling wurde bewusst weitestgehend vernachlässigt. Der Client besteht aus den drei Methoden transcribe(), createAudioOutputStream(...) und sendDataToServer(...).
Übertragen des Gesprochenen
Die Methode transcribe() öffnet den Mikrofoneingang und legt gleichzeitig einen Buffer für das Gesprochene an.
AudioFormat format = new AudioFormat(16000, 16, 1, true, false);Die Abtastrate des Eingangssignals wird hiermit auf 16000, die Samplesize auf 16 und die Kanäle auf Mono festgelegt. Der true-Wert gibt an, dass das Eingangssignal signed ist, es kann also sowohl positive als auch negative Werte beinhalten. Das ist notwendig, da Sprachsignale eben solche Werte beinhalten. Der false-Wert steht für littleEndian und gibt die Speicherreihenfolge an;true steht für bigEndian.
Diese Einstellungen sind erforderlich, da die hinterlegten Sprachmodelle von DeepSpeech ebenfalls mit diesen Werten abgelegt wurden. Ein Wechsel von mono auf stereo beeinflusst die Erkennung negativ.
Schließlich wird das Mikrofon mit dem vorgegebenen Audioformat geöffnet und ist bereit Signale zu empfangen.
DataLine.Info info = new DataLine.Info(TargetDataLine.class,
format);
if ( ! AudioSystem.isLineSupported(info)) {
throw new Exception("Mikrofon ist nicht verf�gbar!");
}
TargetDataLine line = ( TargetDataLine )
AudioSystem.getLine(info);
line.open(format, line.getBufferSize());Zum Speichern des Eingangssignales wird noch ein Buffer zur Verfügung gestellt:
ByteArrayOutputStream out = new ByteArrayOutputStream();
byte[] data = new byte[line.getBufferSize() / 4];Nachdem alle Vorbereitungen abgeschlossen sind, lässt sich das Signal aufzeichnen und abspeichern:
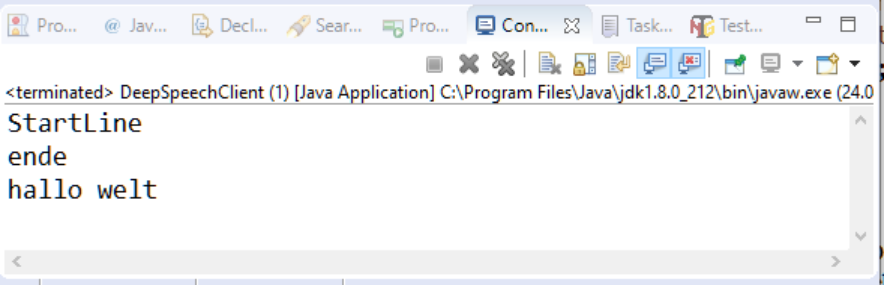
System.out.println("StartLine");
line.start();
long startTime = System.currentTimeMillis();
while ( ( System.currentTimeMillis() - startTime ) < 2000) {
int numBytesRead = line.read(data, 0, data.length);
out.write(data, 0, numBytesRead);
}
System.out.println("ende");Der Eingang hört zwei Sekunden zu und speichert das Gesprochene in dem zuvor festgelegten Buffer. In einem nächsten Schritt wird der ByteBuffer an die Methode createAudioOutputStream(...) weitergegeben. Das Ergebnis davon geht an sendDataToServer(...).
ByteArrayOutputStream byos = createAudioOutputStream(line, out);
return sendDataToServer(byos);Ausgabe in die Datei
Die Methode createAudioOutputStream wandelt den Inhalt des ByteBuffer in eine WAV-Datei um. Dazu berechnet sie die benötigte WAV-Größe, liest den ByteBuffer ein und schreibt schließlich eine WAV als ByteArrayOutputStream raus:
private ByteArrayOutputStream
createAudioOutputStream(TargetDataLine line,
ByteArrayOutputStream out)
throws IOException {
int frameSizeInBytes = line.getFormat().getFrameSize();
byte audioBytes[] = out.toByteArray();
AudioInputStream audioInputStream = new
AudioInputStream(new ByteArrayInputStream(out.toByteArray()),
line.getFormat(),
audioBytes.length / frameSizeInBytes);
ByteArrayOutputStream byos = new ByteArrayOutputStream();
AudioSystem.write(audioInputStream,
AudioFileFormat.Type.WAVE, byos);
audioInputStream.close();
return byos;
}Kommunikation mit DeepSpeech
Nachdem nun die WAV-Datei als ByteArrayOutputStream vorliegt, lässt sich eine Verbindung zum DeepSpeech Server aufbauen und die Datei dorthin senden:
private String sendDataToServer(ByteArrayOutputStream byos)
throws IOException, ClientProtocolException {
HttpClient httpclient = HttpClients.createDefault();
HttpPost httppost = new HttpPost(SERVERADRESS);
ByteArrayEntity bae = new ByteArrayEntity(byos.toByteArray());
httppost.setEntity(bae);
HttpResponse response = httpclient.execute(httppost);
HttpEntity entity = response.getEntity();
if (entity != null) {
try (InputStream instream = entity.getContent()) {
return IOUtils.toString(instream, "UTF-8");
}
}
return "Kein Ergebnis";
}Die gezeigte Methode baut zunächst eine Serververbindung auf und setzt anschließend einen Post-Befehl ab. Die Serveradresse sieht beispielsweise so aus: http://localhost:8080/stt.
Das zuvor erstellte ByteArray wird nun in eine Entity verpackt und an den Server gesendet. Zum Abschluss erfolgt das Auslesen der zurückgegebenen Response.