

Mozilla DeepSpeech: Speech-to-Text Schritt für Schritt
Dieses Tutorial zeigt anhand eines Praxisbeispiels, wie sich ein Sprachassistent mit DeepSpeech auf einem Raspberry Pi erstellen lässt.

(Bild: petrmalinak/Shutterstock.com)
- Pascal Moll
Intelligente Lautsprecher oder Sprachassistenten sind auf dem Vormarsch. Mehr als ein Drittel aller Deutschen nutzt sie. Doch was passiert eigentlich mit den dadurch erzeugten Daten? Es gibt verschiedene Vermutungen, dennoch lässt sich nicht sicher sagen, was mit den gesprochenen Informationen geschieht. Um die volle Kontrolle über diese Daten zu behalten, entschied sich der Autor, selbst eine Offline-Anwendung mit Java zu entwickeln.
Dieses Tutorial soll den Speech-to-Text (STT)-Anteil des Entwicklungsprozesses ausschnittsweise vorstellen. Es folgen Einblicke in die Installation der DeepSpeech Engine mithilfe eines Raspberry Pi. Diese Komponenten nehmen Gesprochenes entgegen und überführt das Gesprochene in Text. Im nächsten Schritt erfolgt die Einführung des zugehörigen Java-Programmcodes, um mit diesem Text zu interagieren und Sprachbefehle zu designen. Der Ausblick zeigt zahlreiche Erweiterungsmöglichkeiten und Einsatzgebiete.
Einführung in Mozilla DeepSpeech
Mozillas DeepSpeech ist eine freie Speech-to-Text-Engine. Sie arbeitet mit einem durch Maschine Learning erstellten Sprachmodell, basierend auf den Forschungsergebnissen von Baidu’s Deep Speech Research Paper und ermöglicht somit, Gesprochenes in Text umzuwandeln. Hier kommt unter anderem Googles Machine-Learning-Framework TensorFlow zum Einsatz, was die Implementierung vereinfachen soll. TensorFlow Lite eignet sich besonders für mobile Geräte, da es deutlich kleinere Sprachmodelle bei vergleichbaren Ergebnissen und Geschwindigkeit mitbringt. Mozilla arbeitet daran, verschiedene Modelle in anderen Sprachen zu generieren. Dafür nutzen sie das Projekt Common Voice. Das Ziel dieses Crowdsourcing-Projekts ist, eine freie Datenbank mit verschiedenen Sprachen und Sprechern aufzubauen.
Videos by heise
Mitwirkende können entweder andere Spracheingaben validieren oder selbst Sprachaufnahmen beisteuern. Zur Teilnahme wird lediglich ein Mikrofon benötigt. Für die englische Sprache ist dieses Projekt schon weit entwickelt, so ist die Fehlerquote sehr gering und selbst für nicht Muttersprachler mit Dialekt vielseitig anwendbar. Das deutsche Sprachmodell funktioniert ebenfalls gut, hat aber noch Schwierigkeiten bei Wörtern, die ähnlich klingen. Beispielsweise wird "Licht an" oft als "Lichter" erkannt.
Benötigte Komponenten und Voraussetzungen
Für das STT-Projekt sind diese Komponenten notwendig:
- Raspberry Pi 4 (ein PI3 B+ ist ausreichend, kann aber zu Verzögerungen bei der Ergebnisrückgabe führen)
- Java 8 mit Maven
- Python 3.5 auf dem Raspi
- Mikrofon (je nach Entfernung empfiehlt sich ein Ringmikrofon)
DeepSpeech als Server aufsetzen
Zunächst sollte das Standardbetriebssystem "Raspberry PI OS" installiert sein. Anschließend empfiehlt es sich, die gesamte Speicherkarte als Speicher über das Konfigurationsmenü bereitzustellen. Somit entfallen mögliche Speicherprobleme zu einem späteren Zeitpunkt, beispielsweise bei der Verwendung eines größeren Sprachmodells.
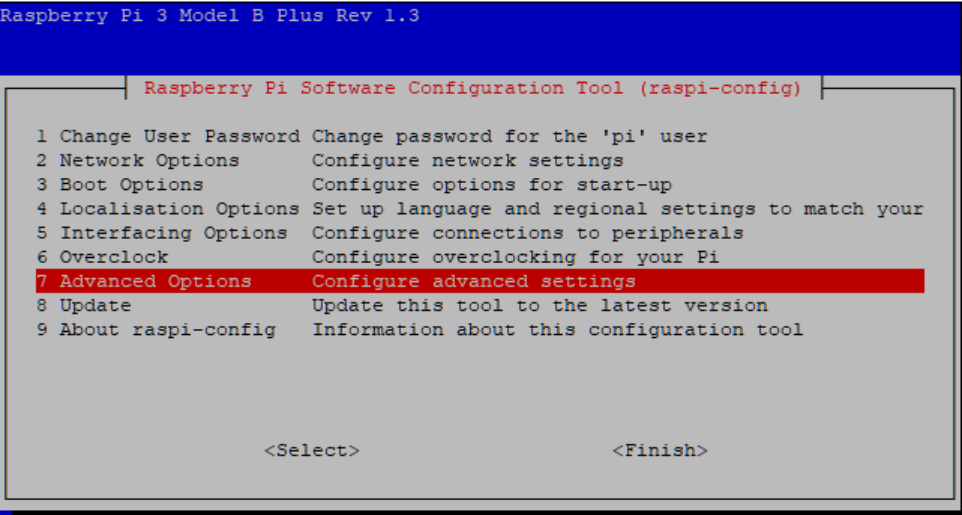
Über Advanced Options (Punkt 7) und A1 Expand Filesystem lässt sich die gesamte Größe der Speicherkarte nutzen. Darüber hinaus ist das Aktivieren des Secure File Transfer Protocol (SSH) oder Virtual Network Computing (VNC) zu empfehlen, um nicht immer wieder externe Peripherie für die Bedienung anschließen zu müssen.
Nach erfolgreichem Abschluss der Grundinstallation gilt es, DeepSpeech zu installieren, was über den Konsolenbefehl pip3 install deepspeech geschieht. Nach wenigen Minuten Wartezeit sollte die Erfolgsmeldung erscheinen:
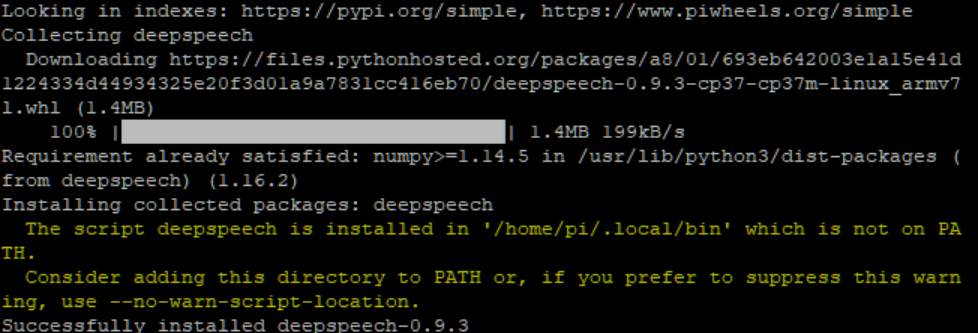
Mit pip3 install deepspeech-server wird nun der Server installiert. Dieser Vorgang kann einige Minuten in Anspruch nehmen.
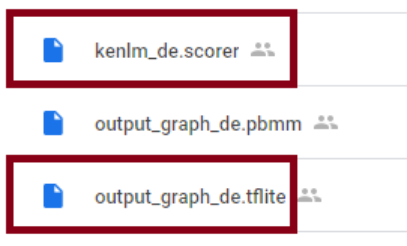
Anschließend ist DeepSpeech installiert, jedoch ist noch kein Sprachmodell hinterlegt. Pre-Trained-Modelle lassen sich via GitHub herunterladen. Für das deutsche Modell empfiehlt sich jedoch diese Adresse. Dieses Modell beinhaltet 1582 Sprach-Stunden. Benötigt werden das Modell TensorFlow lite und der Scorer.
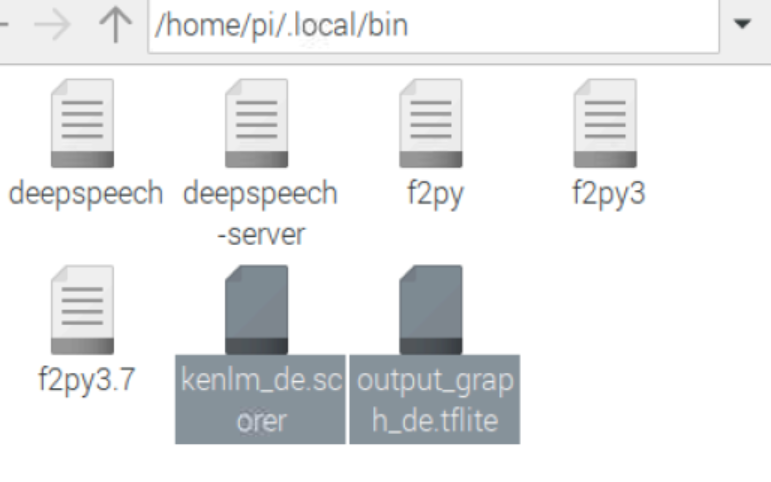
Beide Dateien gilt es herunterzuladen und in der Konfiguration zu hinterlegen. Am einfachsten ist dies mit dem VNC Viewer möglich.
Im letzten Schritt ist es notwendig, die Konfiguration zu hinterlegen. Hierzu dient eine neue Datei namens config.json.
Config.json
{
"deepspeech": {
"model" :"output_graph_de.tflite",
"scorer" :"kenlm_de.scorer",
"beam_width": 500,
"lm_alpha": 0.931289039105002,
"lm_beta": 1.1834137581510284
},
"server": {
"http": {
"host": "0.0.0.0",
"port": 8080,
"request_max_size": 1048576
}
},
"log": {
"level": [
{ "logger": "deepspeech_server", "level": "DEBUG"}
]
}
}Zum Abschluss der Konfiguration ist nun ein Neustart des Raspi erforderlich.
