

Plat_Forms 2011: Web-Entwicklungsplattformen im direkten Projektvergleich
Seite 3: Fazit
Einzelheiten des Entwicklungsprozesses
Sicherlich gibt es noch eine Menge interessanter Eigenschaften, die man untersuchen könnte. Bei einigen davon haben das die Forscher getan, aber nichts Berichtenswertes gefunden. Bei anderen ist die Untersuchung zu aufwendig oder scheitert an den Randbedingungen. Zum Beispiel ließ sich die Effizienz und Skalierbarkeit der Entwicklungen deshalb nicht untersuchen, weil es keine sinnvollen Benutzungsszenarien gibt, deren Funktionen in allen 16 Anwendungen umgesetzt sind.
Was hingegen mit interessantem Ergebnis noch ausgewertet wurde, sind ein paar Facetten des Verhaltens der Teams während der zwei Tage Entwicklungszeit. Zum Beispiel konnten die Teams zur Klärung der Anforderungen jederzeit Rückfragen an den Anforderungslieferanten stellen. Die Betreiber haben die Anzahl dieser Fragen gezählt, mit dem in Abbildung 4 zusammengefassten Ergebnis.
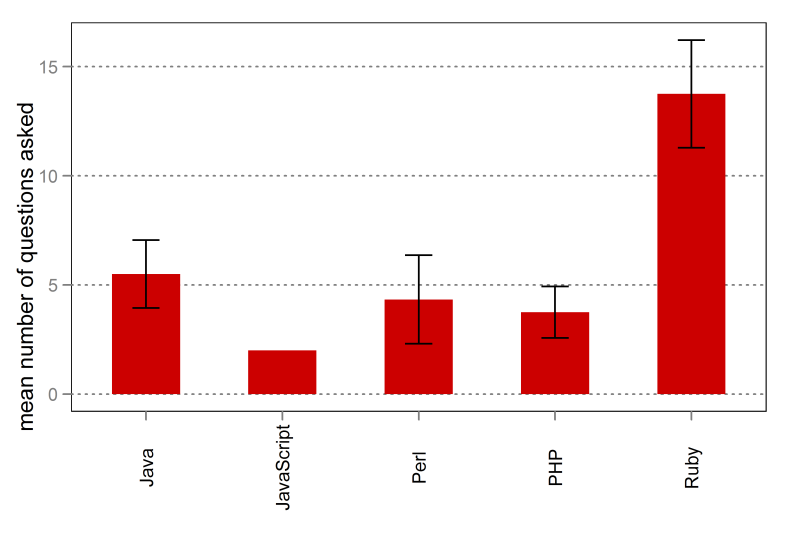
Wie man sieht, stellen die Ruby-Teams mit Abstand die meisten Fragen und die Java-Teams die zweitmeisten. Verblüffend daran: Das ist die gleiche Rangordnung wie bei der Produktivität. Die Bedeutung der Beobachtung ist allerdings mehrdeutig; von "Die hatten einfach mehr Zeit zum Fragen übrig" oder "Die sind besser zu den Feinheiten vorgedrungen, bei denen solche Fragen aufkamen" (d. h., Produktivität erzeugt quasi Fragen) über "kompetente Teams sind produktiv und stellen viele Rückfragen" (d. h., ein dritter Faktor erzeugt beides) bis hin zum radikalen "Wer seinen Kunden liebt und wirklich alles richtig machen will, ist auch produktiver" (d. h., Fragen erzeugen Produktivität) ist vieles denkbar.
Hochinteressant war noch ein Fundstück aus der Aktivitätsverfolgung. Die Forscher haben jeden Teilnehmer alle 15 Minuten gefragt: "Was haben Sie jetzt eben gerade getan", und die Antwort darauf war einer von 21 Aktivitätstypen wie "lese Anforderungen", "lese Dokumentation", "schreibe Code", "teste", "mache Pause" und "diskutiere mit Teamkollegen". Sowohl die Gesamthäufigkeit als auch der zeitliche Häufigkeitsverlauf waren bei den meisten Aktivitätstypen nicht auffällig verschieden zwischen den Plattformen. Eine Ausnahme bilden die drei Tätigkeiten "teste manuell", "schreibe automatisierten Test" und "lasse automatisierten Test ablaufen". Deren Häufigkeiten sahen nämlich aus wie in Abbildung 5 zusammengefasst.
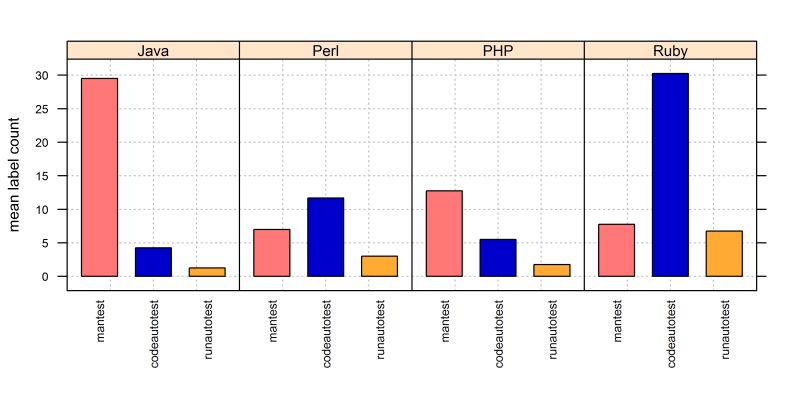
Zwei Beobachtungen stechen ins Auge:
- Die Ruby-Teams verwandten mehr Zeit auf automatische Tests als alle anderen zusammen.
- Die Java-Teams verwandten mehr Zeit auf manuelle Tests als alle anderen zusammen.
Zwei Schlussfolgerungen lassen sich daraus ableiten. Die erste ist interessant für alle, die hohe Testautomatisierung für oftmals zu aufwendig halten:
Erkenntnis 7: Selbst ohne längere Fortentwicklung des Produkts kann hohe Testautomatisierung offenbar sehr produktiv sein (siehe Ruby).
Die zweite richtet sich an die Gruppe all derer, die gegenteilig glaubt, allein automatische Tests machten selig:
Erkenntnis 8: Zumindest wenn längere Fortentwicklung des Produkts nicht nötig ist, kann manuelles Testen offenbar sehr produktiv sein (siehe Java).
Fazit
Im Datenmaterial steckt sicherlich noch einiges, das noch nicht zu Tage befördert wurde, aber von den bisher untersuchten Aspekten waren dies die wichtigsten Resultate. Wie 2007 fanden die Forscher, dass der Wettbewerb aus wissenschaftlicher Sicht ergiebig war, und auch die Teams waren von ihrer Teilnahme wieder begeistert. Mindestens die Siegerfirmen auf jeder Plattform freuen sich zudem über das tolle Marketingmaterial, das sie dadurch in Händen halten. Sponsoren für Plat_Forms 2011 waren Accenture, Microsoft, ICANS und vor allem die Deutsche Forschungsgemeinschaft.
Lutz Prechelt
ist Professor für Software Engineering am Institut für Informatik der Freien Universität Berlin. Seine Forschung betrifft überwiegend den Bereich Softwareprozesse, insbesondere agile Softwareprozesse, und darin vor allem die Paarprogrammierung, die verteilte Paarprogrammierung und das zugehörige Werkzeug Saros. Interessenschwerpunkt sind meist die psychologischen und soziologischen Aspekte.
Ulrich Stärk
ist wissenschaftlicher Mitarbeiter in der AG Software Engineering an der Freien Universität Berlin, war 2007 an der Auswertung von Plat_Forms beteiligt und ist verantwortlich für die Planung, Durchführung und Auswertung von Plat_Forms 2011 und 2012.
