Unternehmens-APIs mit Microservices
Seite 4: Option 3: Microservice-API
Eine weitere Möglichkeit wäre es, auf den zentralen Service zu verzichten. Dieser Ansatz lagert viele Aufgaben wie Routing, Versionshandling und Verfügbarkeitsangaben in komplexe Infrastrukturkomponenten aus. Hierzu muss in den Microservices das Wissen, Teil einer API zu sein, direkt enthalten sein. Auch machen unter anderem eine API-weite Versionierung, Routing und die Authentifizierung das Ganze herausfordernder.
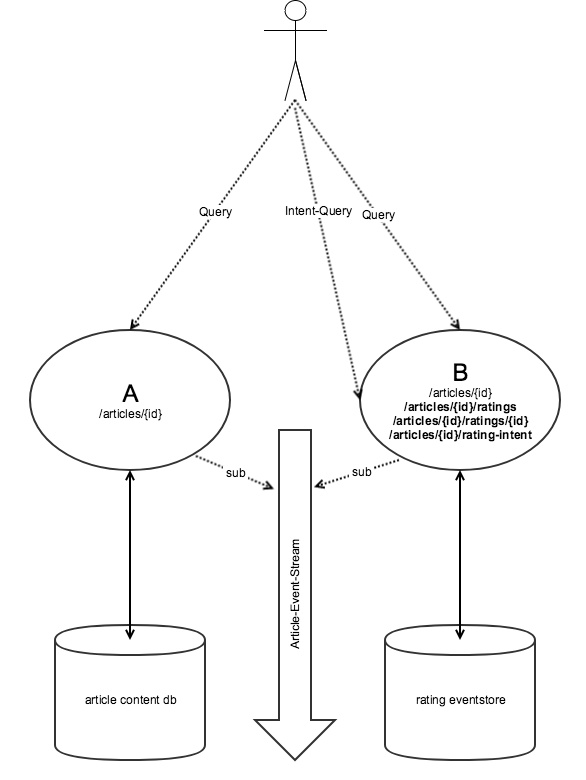
Um eine Verlinkung zu etablieren, muss der verlinkende Microservice wissen, wo sein Linkziel liegt oder zumindest die Adresse nach Außen kennen. Dies kann durch statische Links oder durch eine Service-Discovery erfolgen. Danach kann man unterschiedlich vorgehen.
Serverseitiges Rendern der Links
Der verlinkende Service geht zum verlinkten Service und fragt dort die zu rendernden Links ab. Dazu muss der Aufrufer das Linkformat und Templating verstehen. Caching sollte hierfür erlaubt sein.
In unserem Beispiel bedeutet das konkret, dass Service A, um einen Link zu den Bewertungen auszuliefern, zur Root-Ressource des Service B geht und daraufhin in das Template B/articles/{articleId} des Service B die entsprechende Id einsetzt. Danach tätigt Service A den Call zum Artikel und kopiert die Links zu den Bewertungen dort in seinen Request.
Wohlbemerkt muss Service A nichts von B verstehen, abgesehen vom Linkpfad. Man beachte dabei die Analogie zu Option 2. Service A kann nun eigenverantwortlich cachen (das heißt zum Beispiel den Templatelink nur jede Minute aktualisieren). Die Abhängigkeiten der beiden Services kann man noch durch Service-Registries, Schema-Registries oder ähnliches abfedern.
In einer Dokumentation der API tauchen dann jedoch nicht alle Endpunkte auf. Man könnte sogar darauf verzichten, die Endpunkte, die nur Service A benötigt, für den Client erreichbar zu machen. Sollte nun in der API die Anforderung bestehen, dass im Artikel-Payload auch die Gesamtbewertungen mit ausgeliefert werden, müsste A diese ausliefern, indem er nicht nur den Link von B zu den Ratings, sondern auch dessen Payload mit in seinen zusammenführt. Auch ein asynchroner Weg ist denkbar.

Das führt jedoch über kurz oder lang dazu, dass die Grenze der beiden Services verwischt. Wenn man nicht aufpasst, weiß A auf einmal, was eine Gesamtbewertung ist, was eigentlich in der Domäne von B liegt. Hier besteht die große Gefahr eines verteilten Monolithen. Der Unterschied zum API-Gateway besteht darin, dass A noch für einen Teil des fachlichen Codes zuständig ist.
Clientseitige Verlinkung
In einem solchen Fall weiß der verlinkende Service nur wenig über den aufzurufenden Service und gibt dem Client nur den Hinweis, wo der andere Service liegt. Im anderen Service bildet man das fehlende Schema in den Links durch sogenannte Intent-Ressourcen ab. Der Client muss, bevor er einen schreibenden Request absetzt, die Absicht (Intent) bekunden. Er bekommt dann eine Antwort, in der das genaue Schema für den Schreib-Request und die URL steht (und auch die Information, dass ein Schreiben zur Zeit möglich ist).
Dies ist den meisten Lesern schon aus Zeiten von (HTML-) Webservern bekannt und ist durchaus damit vergleichbar. Nur muss man hierzu nicht zwingend HTML sprechen, sondern weicht eher auf JSON und JSON-(Hyper)Schema aus. Die Vorteile liegen darin, dass der verlinkende Service kein Schema in die Links schreiben muss, sondern die Kenntnis von Schema und/oder Berechtigungen auf den verlinkten Service geschoben werden. Der Nachteil ist dabei ganz klar der eine zusätzliche HTTP-Request pro anzulegendem Objekt.
In unserem Beispiel bietet Service B also eine weitere Ressource B/articles/{id}/rating-intent an. Diese liefert einen geeigneten Payload mit Metainformationen (zum Beispiel ein JSON-Schema) dazu aus, wie das Anlegen einer neuen Bewertung durchzuführen ist. Service A ist das Linktemplate bekannt und liefert es aus. Je nachdem, wie eng man diese Kopplung machen möchte, kann die Beurteilung der generellen Durchführbarkeit schon bei A erfolgen, oder man lagert sie nach B aus.
Als Weg des Informationstransports bietet sich zum Beispiel das serverseitige Rendern an. Obwohl sich dann die Frage stellt, warum nicht gleich die ganze Intent-Ressource von B durch A mit ausgeliefert wird. Alternativ zur Intent-Ressource kann man hier einen OPTIONS-Request auf B/articles/{id}/ratings anbieten, die sich dann wie die Intent-Ressource verhält.
Bei diesem Vorgehen ist es zunächst nicht vorgesehen, dass der Payload von A die Gesamtbewertungen mitausliefert. Man müsste im Verfahren wie oben die Gesamtbewertung vorher serverseitig abholen, was die Nachteile der losen Bindung aufhebt und keine weiteren Vorteile liefert. Somit bietet es sich an, wenn die beiden Services solche Teile auf anderem Wege, zum Beispiel asynchron, austauschen. Diese Variante eignet sich nur, wenn die verschiedenen Teile der API möglichst wenig aufeinander angewiesen sind. Das ist zum Beispiel bei Self-Contained Systems der Fall. Dort sind die einzelnen Services nur durch HTML-Links verbunden und Daten werden durch asynchrone Kommunikation ausgetauscht.
Außerdem muss man wieder genau überlegen, welche Ressourcen man in die API-Dokumentation aufnimmt und welche eigentlich nur für A verfügbar sein sollen, damit der Kunde den Eindruck einer durchgängigen API erhält.