

Versteckte Risiken beim Kompilieren von Embedded Software
Seite 2: Implementation-defined behaviour: Portabilitätsprobleme
Implementierungs-abhängiges Verhalten unterscheidet sich in einem wichtigen Punkt von unspezifiziertem Verhalten: Der Compiler-Hersteller muss dokumentieren, welches Verhalten der Compiler verwendet.
Der C++-Standard selbst enthält eine Liste mit allen Stellen, die einer solchen Dokumentationspflicht unterworfen sind. Mit 235 Punkten ist die Liste allerdings relativ umfangreich.
Einige Punkte erscheinen auf Anhieb plausibel: Das Alignment von Datentypen muss von der Zielarchitektur abhängig sein. Der Compiler muss beispielsweise berücksichtigen, wenn die Hardware den Zugriff auf 4-byte-Integer nur an 4-byte-Adressen (0x00, 0x04, 0x08, ...) unterstützt. Das einheitliche Festlegen solcher Charakteristiken über viele Hardwarearchitekturen hinweg in einer aussagekräftigen Weise ist schlicht nicht möglich. Die Plattformunabhängigkeit gehört zu den wichtigen Eigenschaften von C und C++. Es ist somit die beste Wahl, diese Punkte als implementierungsabhängig zu definieren.
Andere Punkte der Liste bringen keine dermaßen deutliche Begründung mit. Unter anderem ist nicht direkt ersichtlich, warum der Wert von NULL als implementierungs-abhängig markiert ist.
Am Beispiel von Aufzählungen mit enum lässt sich zeigen, wie aus der Freiheit des Compilers funktional unterschiedlicher Code entsteht. Der Standard definiert dazu Folgendes: Die Implementierung legt fest, welcher ganzzahlige Typ als zugrundeliegender Typ genutzt ist. Allerdings soll der zugrundeliegende Type nicht größer als int sein, es sei denn der Wert eines Enumerator passt nicht in int oder unsigned int. (It is implementation-defined which integral type is used as the underlying type except that the underlying type shall not be larger than int unless the value of an enumerator cannot fit in an int or unsigned int.)

(Bild: embeff)
In Abbildung 2 ist erkennbar, dass der arm-gcc den Typ der Aufzählung NWRegisteringMode auf unsigned char festlegt. Der x86-gcc weist dem gleichen Enum den Typen unsigned int zu. Das Template auf der linken Seite dient lediglich als Hilfsmittel, damit der Compiler den gewählten Typ des enums leserlich ausgibt.
Obwohl sich beide Compiler standardkonform verhalten, kann die Umsetzung Unterschiede zur Laufzeit bewirken. Insbesondere Bit-Operationen und Casts verursachen in der Praxis Bugs in Embedded-Bibliotheken.
Undefined behaviour: Merkwürdiges Verhalten
Eine prägnante Zusammenfassung für undefiniertes Verhalten liefert die cppreference: Durch das Verletzen bestimmter Regeln der Programmiersprache wird das gesamte Programm sinnlos. (Renders the entire program meaningless if certain rules of the language are violated.)
Wenn Code also (unbewusst) die Regeln der Sprache verletzt, darf der Compiler das gesamte Programm als unsinnig interpretieren. Das folgende Beispiel zeigt auf, welche Gefahr in derartigen Situationen lauert:
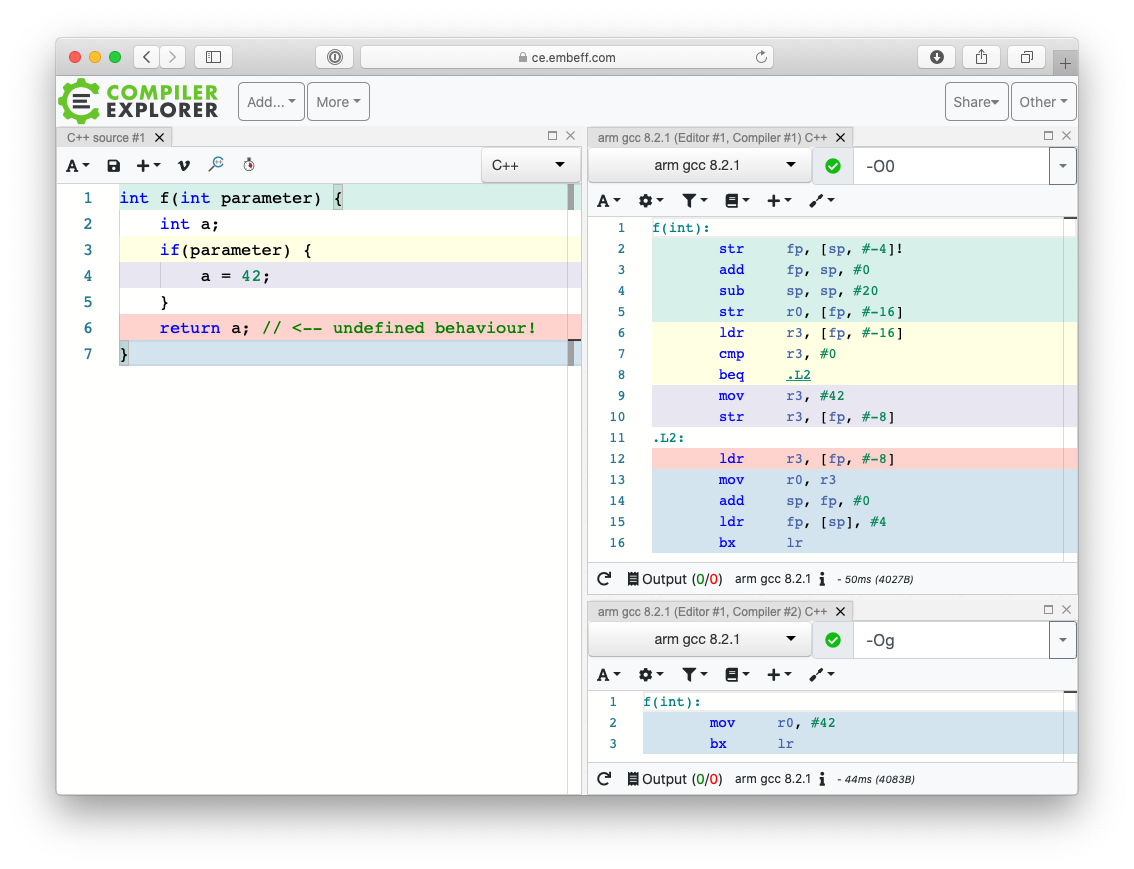
int f(bool parameter) {
// uninitialisierte lokale Variable:
int a;
if(parameter) { a = 42; }
// M�glicher Zugriff auf uninitialisierte Variable:
return a;
}Der Zugriff auf uninitialisierte Variablen verletzt die Regeln der Sprache und ist damit undefiniert. Um zu verstehen, wie der Compiler damit umgeht, ist ein Blick in das generierte Assembly aufschlussreich, das unterschiedliches Verhalten je nach Optimierung aufweist (s. Abb. 3):
- Ohne Optimierung (
-O0) wird überprüft, ob der Funktionsparameter von 0 verschieden ist. In diesem gibt die Funktion 42 zurück und andernfalls den Inhalt vona. Letztere Variable ist auf dem Stack alloziert, aber noch nicht initialisiert. Der Rückgabewert hängt daher davon ab, was vormals an dieser Position im RAM gespeichert war, beziehungsweise welche anderen Funktionen das Programm vorher aufgerufen hat. - Bei eingeschalteter Optimierung (-Og) entfällt die Betrachtung des Funktionsparameters, und der Code gibt immer 42 zurück.
(Bild: embeff)
Je nach Optimierungsstufe ist somit ein komplett unterschiedliches Verhalten zu beobachten. Da es sich bei dem Variablenzugriff um undefiniertes Verhalten handelt, ist die Interpretation zulässig. Laut Standard darf der Compiler an der Stelle das gesamte Programm als unsinnig betrachten. Der Standard fordert hingegen nicht, dass eine Meldung (Warnung/Fehler) darüber erfolgt.
Ausblick: Bugs im Compiler
Als weiteren wichtigen Faktor gilt es zu berücksichtigen, dass Compiler und Laufzeitbibliotheken Bugs haben. Das ergibt sich naturgemäß aus der mittlerweile enormen Komplexität solcher Tools. Das tatsächliche Ausmaß dieser Fehlerquelle ist dramatisch. Der verbreitete gcc-Compiler weist Stand Juli 2020 in seinem Bug-Tracker 14.383 offene Bugs aus. Während dieser Artikel entstand, konnten 49 davon behoben werden – gleichzeitig kamen jedoch 75 neu gemeldete Bugs hinzu.
Ein konkreter Bug in der GNU Embedded Toolchain von ARM verdeutlicht die Auswirkungen: #1527413 4.9 series reproducibly corrupts register R7 – unter äußerst speziellen Bedingungen verändert der Compiler ein Register des Prozessors ungewollt. Der Beispielcode zur Reproduktion würde unverändert mit einem anderen Compiler fehlerlos laufen. Das zeigt, dass nur eine On-Target-Ausführung sicherstellen kann, dass der eigene Code nicht von Compiler-Bugs betroffen ist.
