

Versteckte Risiken beim Kompilieren von Embedded Software
Um sicherzustellen, das Embedded Software korrekt läuft, sind der passende Compiler und Tests auf der Zielplattform unerlässlich.
- Daniel Penning
Embedded Firmware entsteht üblicherweise auf einem Desktop-PC. Code ohne direkte Abhängigkeit zur Hardware lässt sich mit einem herkömmlichen Compiler an der Workstation kompilieren und bereits auf dem Entwicklungsrechner (Off-Target) ausführen. Viele Teams nutzen diesen Ansatz, um lange Kompilier-Flash-Debug-Schleifen auf dem Mikrocontroller zu umgehen.
Dabei gilt es jedoch zu beachten, dass der auf die Weise getestete Code beim Ausführen auf dem echten Zielsystem (On-Target) unter Umständen ein anderes Verhalten zeigt. Im besten Fall kommt es bereits beim Kompilieren mit dem Cross-Compiler zu einem Fehler. Mit weniger Glück verhält sich der kompilierte Code in Details anders. Im Off-Target-Verfahren verifizierter Code ist plötzlich nicht mehr korrekt.
Vielfach kommt der Off-Target-Ansatz für Unit-Tests zum Einsatz, was im Hinblick auf ein effizientes Entwickeln sinnvoll ist. Bleiben aber zusätzliche On-Target-Tests – mit potenziell unterschiedlichen Ergebnissen – aus, ergibt sich schnell eine rein gefühlte Sicherheit.
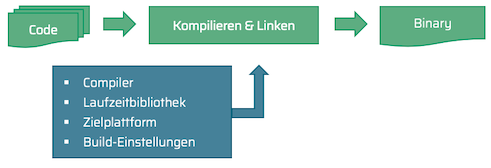
Der Code wird erst durch eine Toolchain mit Compiler und Linker zu einem ausführbaren Binary. Abbildung 1 zeigt die Einflussfaktoren auf diesen Prozess. Einen wichtigen, wenn auch subtilen Einluss, hat der Compiler. Das wirft die Frage auf, wie zwischen zwei standardkonformen Compilern ein Unterschied im Ergebnis entstehen kann. Ist die eindeutige Auslegung von Code nicht gerade der Hauptgrund für einen Sprachstandard?
Die Freiräume eines Compilers
Der Begriff "undefined behaviour" ist vielen C- und C++-Entwicklern bekannt. Dabei lassen die Standards den Compilern mit Absicht Freiraum in der Interpretation. Weniger bewusst ist die Tatsache, dass es dadurch zu subtilen Abweichungen im Off-Target-Verhalten kommen kann.
Insgesamt gibt es drei Kategorien von Freiräumen, die der C++-Standard konformen Compilern einräumt. Der folgende Überblick ist der Definition des noch aktuellen C++17-Standard entnommen, und der C18-Standard definiert die Begriffe sinngemäß gleich.
- unspecified-behaviour: Verhalten für ein wohlgeformtes Programmkonstrukt und korrekte Daten, das von der Implementierung abhängt ("behavior, for a well-formed program construct and correct data, that depends on the implementation")
- implementation-defined behaviour: Verhalten für ein wohlgeformtes Programmkonstrukt und korrekte Daten, das von der Implementierung abhängt und das jede Implementierung dokumentiert. ("behavior, for a well-formed program construct and correct data, that depends on the implementation and that each implementation documents")
- undefined behaviour: Verhalten, für das dieser internationale Standard keine Anforderungen vorgibt.
Unspecified Behaviour: Überraschend alltäglich
Unspezifiziertes Verhalten bezieht sich auf korrekte Programme, die Sprachmittel in einer nicht näher spezifizierten Weise verwenden. In dem Fall kann der Compiler entscheiden, welches Verhalten er einsetzt. Im Gegensatz zu "undefined behaviour" sind die möglichen Verhaltensweisen jedoch überschaubar und nachvollziehbar.
Überraschenderweise ist einer der Kernaspekte der Sprache undefiniert: Die Ausführungsreihenfolge bei Ausdrücken.
foo(fun1(), fun2());Die Zeile ruft eine Funktion foo mit zwei Parametern auf, die jeweils Rückgabewerte von zwei weiteren Funktionen sind.
Der Standard definiert für solche Ausdrücke nicht, ob zunächst fun1 oder fun2 ausgeführt wird. Und tatsächlich nutzen unterschiedliche Compiler beide möglichen Varianten. Das folgende Kurzbeispiel demonstriert die Reihenfolge der Auswertung:
#include <iostream>
int fun1() { printf("fun1() \n"); return 0; }
int fun2() { printf("fun2() \n"); return 0; }
void foo(int x, int y) { printf("foo() \n"); }
int main() {
foo(fun1(), fun2());
}
Die Ausgabe auf einem typischen Desktop-Compiler (x86-64 mit gcc 9.2) liefert folgendes Ergebnis:
fun2()
fun1()
foo()
Ein typischer Embedded Compiler (arm-gcc-none-eabi 8-2018-q4) auf einem ARM Cortex-M4 erzeugt aus derselben Zeile dagegen folgenden Code:
fun1()
fun2()
foo()
Der Embedded hat gegenüber dem Desktop Compiler somit eine verdrehte Reihenfolge in der Ausführung.
Dieses Beispiel führt lediglich zu unterschiedlichen Ausgaben. Beide Funktionen geben immer 0 zurück. Man kann sich jedoch leicht ausmalen, welche Effekte entstehen, wenn fun1 und fun2 auf gemeinsame Daten zugreifen und diese auswerten und verändern.
Nach Wissen des Autors existiert leider keine kompakte Liste für unspezifiziertes Verhalten. Das ist für eine weitere Kategorie von Compiler-abhängigem Verhalten glücklicherweise anders.
