

Big Data: Hortonworks startet Stinger.next
Nachdem die im letzten Jahr gestartete Stinger Initiative zur Beschleunigung von Apache Hive erfolgreich abgeschlossen werden konnte, hat Hortonworks nun weitere Pläne für SQL auf dem Big-Data-Framework Hadoop vorgestellt.
- Julia Schmidt
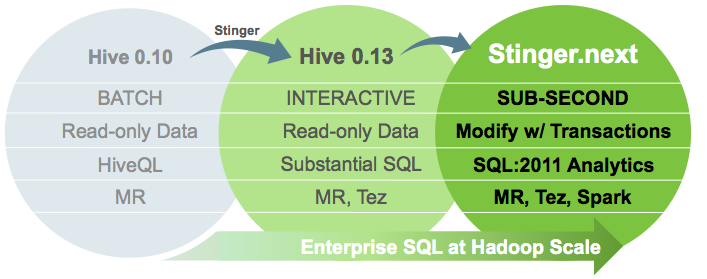
Hortonworks hat eine neue Runde zur Beschleunigung von Apache Hive eingeläutet. Nachdem die 2013 gestartete und im April dieses Jahres abgeschlossene Stinger Initiative Hive wohl schon um das Hundertfache beschleunigen konnte, soll Stinger.next nun Zugriff in Echtzeit und Transaktionsfähigkeiten realisieren. Dies soll erneut in Zusammenarbeit mit der Hive-Community geschehen und wie in der letzten Initiative setzt man auch bei Stinger.next auf ein Drei-Phasen-Modell zur Realisierung der gesetzten Ziele.
Das Open-Source-Projekt Hive versorgt das ebenfalls quelloffene Framework Hadoop mit Möglichkeiten zur Analyse von Datensets, indem es eine SQL-ähnliche Abfragesprache zur Verfügung stellt. Hadoop bietet ein Framework zum Speichern und Bearbeiten von Datensets auf Clustern verteilt bereitgestellter Hardware.
(Bild: Hortonwork )
Konkret soll das Stinger.next wohl erreichen, dass die Zeiten bei der Reaktion auf Anfragen unter einer Sekunde liegen, dass Hive das einzige SQL-Interface wird, das für Anfragen im Giga-, Tera- und Petabyte-Bereich ausgelegt ist, und dass Transaktionen und SQL:2011-Analysemöglichkeiten in Hive zur Verfügung stehen. Durch die Transaktionen sollen Nutzern in der Lage sein, Daten einfügen, aktualisieren und entfernen zu können und so von einem System, das auf "einmal schreiben, mehrmals lesen" fußt, abzurücken. Die schnelleren Reaktionszeiten soll Hive für Dashboards und explorative Analysevorgänge interessant machen, wobei dann die Analysefunktionen aus SQL:2011 ihr übriges tun können. Zudem plant man die Integration in das Framework für analytische Berechnungen auf Clustern Apache Spark.
All dies soll Hive besonders im Unternehmenssektor voranbringen. Stinger.next soll innerhalb der nächsten 18 Monate abgeschlossen sein und Hortonworks kann laut Ankündigung wohl unter anderem auf Unterstützung von Unternehmen wie Microsoft und Informatica bauen.
Da einige Anbieter von Hadoop-Distributionen Hive bereits als zu langsam für den Unternehmenseinsatz abgestempelt und alternative Produkte wie Cloudera Impala (ebenfalls Open Source) und IBM Big SQL ins Rennen geschickt haben, könnte der erfolgreiche Abschluss von Stinger.next ihnen ein Dorn im Auge sein, wären ihre Verkaufsargumente für derartige Software dann doch zumindest abgeschwächt. Vor allem Nutzer, die schon eine Weile mit Hive arbeiten und deren Anforderungen über die Zeit gestiegen sind, und Anhänger quelloffener Komponenten würden sich dann wahrscheinlich schwerer überzeugen lassen. (jul)
