GTC 2017: Nvidias Volta-Architektur ein Meilenstein im GPU-Design
Führende Nvidia-Ingenieure haben sich zu den Neuerungen der Volta-GPU geäußert. Laut Chefentwickler Alben ist Volta mehr als nur ein Aufguß von Pascal, sondern eine völlig neue Architektur.
Nvidia hat seinen Next-Gen-Grafikchip Volta auf der GPU Technology Conference vorgestellt. Im Laufe der Konferenz haben führende Entwickler und Ingenieure dabei weitere Details zum kommenden High-End-Chip herausgelassen. Demnach ist die neue Volta-GPU mehr als nur ein vollgepackter Pascal 2.0. Jonah Alben, GPU-Chefentwickler bei Nvidia, erklärte: "Volta ist ein komplett anderer Prozessor, nicht nur ein Pascal mit Tensor Cores".
Weiterlesen nach der Anzeige
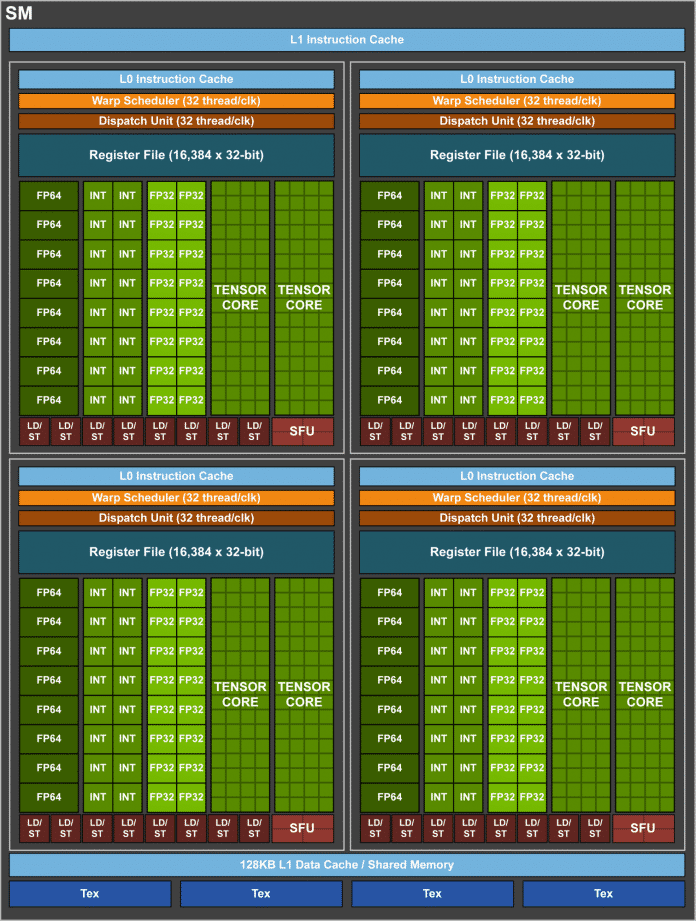
Die neuen Tensor Cores belegen eine vergleichsweise große Chip-Fläche. Jeder Streaming-Multiprozessor enthält 8 Tensor Cores.
So habe man Volta an den entscheidenden Stellen umgekrempelt und sei beim Design an die Grenze des derzeit physikalisch Möglichen gegangen. "Ich bin glücklich, dass Jensen uns einen solchen Chip hat bauen lassen", erklärte Alben mit einem verschmitzten Lächeln und schob hinterher: "noch größer und der Chip wäre illegal". Als die Frage nach der Yield-Rate kam, also die Chipausbeute pro Wafer, wollte Vice President Alben nicht antworten.
Besonders wichtig seien die Änderungen bei Scheduling, die Volta im Vergleich zum Pascal-Vorgänger das Ausführen von noch komplexeren Code erlauben. Der Pascal-Scheduler sei im Vergleich nicht annähernd so effizient gewesen.
Volta: GV100-GPU mit 16 GByte HBM2-Speicher
(Bild: Martin Fischer)
Streaming-Prozessoren 50 Prozent energieeffizienter
Die Streaming-Multiprozessoren (SM) haben Nvidia-Ingenieure laut Alben speziell fürs Deep Learning optimiert. Jede Volta-SM soll 50 Prozent energieeffizienter arbeiten als ihre Pascal-Vorgänger; die Leistung beim Ausführen von FP32- und FP64-Code bei gleichem Energiebedarf steigen. Das neue Thread Scheduling erlaubt feinkörnige Synchronisierung über mehrere Threads hinweg. Dabei soll der größere L1-Cache und das Shared-Memory-Subsystem die Performance weiter verbessern und letzendlich auch das Programmieren vereinfachen. Alben zufolge hat der L1-Cache im Vergleich zum Vorgänger eine um den Faktor 4 geringere Latenz und erreicht einen Durchsatz von rund 14 Terabyte/s.
Volta enthält im Vollausbau bis zu 5376 Kerne.
(Bild: Nvidia)
Compute-Spezifikationen
GPU
Kepler GK110
Maxwell GM200
Pascal GP100
Volta GV100
Compute Capability
3.5
5.2
6.0
7.0
Threads / Warp
32
32
32
32
Max Warps / SM
64
64
64
64
Max Threads / SM
2048
2048
2048
2048
Max Thread Blocks / SM
16
32
32
32
Max 32-bit Registers / SM
65536
65536
65536
65536
Max Registers / Block
65536
32768
65536
65536
Max Registers / Thread
255
255
255
255*
Max Thread Block Size
1024
1024
1024
1024
FP32 Cores / SM
192
128
64
64
# of Registers to FP32 Cores Ratio
341
512
1024
1024
Shared Memory Size / SM
16 KB/32 KB/48 KB
96 KB
64 KB
Configurable up to 96 KB
Nvidia setzt auf der Tesla V100 einen Volta-Chip mit 5120 Cores und 80 SMs ein. Das Design erlaubt jedoch Chips mit bis zu 84 SMs und 5376 FP32-Kernen, 2688 FP64-Kernen und 672 Tensor-Cores. Für künftige Gamer-Karten interessant: Volta enthält bis zu 336 Textureinheiten. Der Chefentwickler kommentierte, dass Volta auch Spiele "ziemlich schnell" darstellen kann. Im Vergleich zu einer GeForce GTX 1080 Ti könnte eine künftige High-End-Karte mit Volta-GPU durchaus bis zu 50 Prozent mehr Performance bieten; allerdings dürften solche Karten nicht vor dem zweiten Quartal 2018 erscheinen.
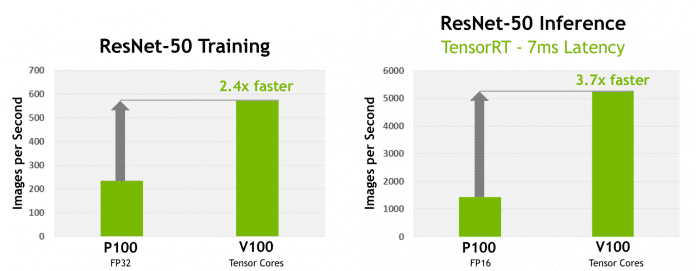
Beim Training und Inferencing von neuronalen Netzwerken schlägt Volta den Vorgänger P100 deutlich.
(Bild: Nvida)
Tensor Cores: 120 Billionen Operationen pro Sekunde
Die Tensor Cores sollen einen vergleichsweise großen Teil der 815 mm² großen Chipfläche einnehmen. Jeder Streaming-Multiprozessor enthält acht Tensor-Cores. Sie lassen sich zwar nur eingeschränkt programmieren, liefern aber sowohl beim Training als auch Inferencing von neuralen Netzwerken eine gigantische Rechenleistung bei Matrix-Matrix-Multiplikationen von 120 Tensor-TFlops; schaffen also 120 Billionen Operationen pro Sekunde.
Weiterlesen nach der Anzeige
Gerade in Server-Systemen ist der schnelle Austausch zwischen mehreren GPUs wichtig. Mit der zweiten Generation des High-Speed-Interconnects "NVLink 2.0" sind mit Volta nun bis zu 300 GByte/s möglich – über sechs NVLink-Links. NVLink 2.0 unterstützt nun außerdem CPU Mastering und Cache-Kohärenz bei Servern mit IBM-Power-9-CPUs. Vom schnellen Interconnect profitieren etwa auch die überarbeiteen DGX-1-Supercomputer.
Die 150-Watt-Version der Tesla V100 soll immerhin noch 80 Prozent der Leistung der 300-Watt-Varianten erzielen.
(Bild: Martin Fischer)
HBM2-Speicher mit 900 GByte/s
Beim Speicher bleibt Nvidia bei 16 GByte HBM2, erhöht jedoch die Speichertaktfrequenz und damit die Transferrate von 720 GByte/s (Tesla P100) auf 900 GByte/s. Jonah Alben unterstrich, dass Volta einen neuen Speichercontroller mitbringt und erklärte, dass theoretisch auch ein größerer Speicherausbau, etwa auf 32 GByte möglich sei. Praktisch liefert aber noch kein Hersteller entsprechende Chips aus. Verbessert wurde im Vergleich zu Pascal auch das Unified-Memory-Modell; so enthält Volta neue Access Counter, die die Effizienz bei Speicherzugriffen erhöhen.
CUDA 9 mit voller Volta-Unterstützung
Die neuen Funktionen der Volta-GPUs lassen sich erst mit CUDA 9 ausnutzen. cuBLAS und cuDNN enthalten neue Interfaces, um die Tensor-Cores für Deep-Learning-Anwendungen und -Frameworks zu nutzen. Neue Versionen von Deep Learning Frameworks sollen bereits von Volta profitieren können; Nvidia erwähnt dabei speziell Caffe2, MXNet, CNTK und TensorFlow.
Die Volta-Rechenkarte Tesla V100 soll ab dem dritten Quartal 2017 erhältlich sein – als 300- und 150-Watt-Version. Letztere soll immerhin noch 80 Prozent der Leistung liefern, wie Jonah Alben gegenüber Journalisten versicherte.