

Erste Nvidia DGX1-Systeme mit Volta-Chips verschickt
Die Vermarktung der neuen für Deep-Learning-Training optimieren DGX-1-Systeme mit fast 1 Petaflops Rechenleistung (fp16) geht los. Erster Empfänger ist das Center für klinische Datenwissenschaften in Boston.

Da ist sie, die erste ausgelieferte DGX-1. Sie geht an die Forschungsteam des Center for Clinical Data Science (CCDS) in Boston. Damit kommt das im Mai auf Nvidias Entwicklerkonferenz GTC angekündigte DGX-1-System knapp vier Monate später allmählich auf den Markt – offizieller Kaufpreis samt komplettem Software-Stack für Deep Learning liegt bei 150.000 US-Dollar. PCIe-Karten mit Tesla-Volta V100 wurden schon vor über einem Monat an Forscher ausgeliefert.
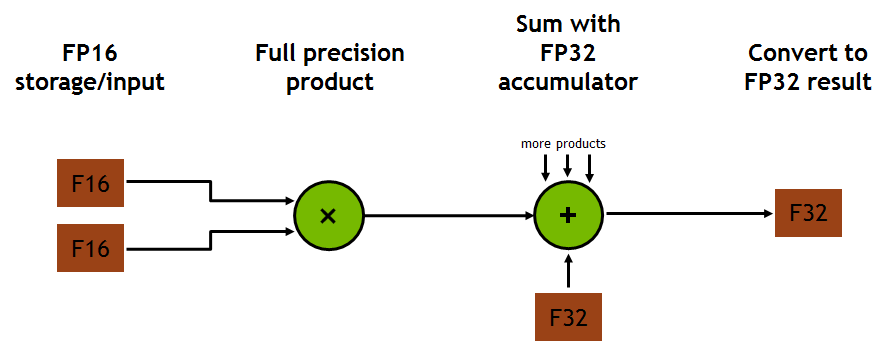
Das für Deep Learning optimierte DGX-1-System erreicht nun dank der per NVlink-2 verbundenen acht Tesla-V100-Karten und somit über 5000 Tensor-Kernen fast 1 Petaflops in Fp16/Fp32 Mixed Precision. Es ist damit rund sechsmal so schnell wie das DGX-1-Vorgänger-System mit Pascal P100. Gegenüber den über PCIe verbundene Karten in 8-GPU-Servern klappt das Zusammenspiel der ohnehin etwas schnelleren Karten im SXM2-Format dank NVlink 2 mit sechsmal 25 GByte/s (bidirektional) weit besser. Damit soll dann das Training bei ResNet50 (90 Epochen) etwa um Faktor 2,5 schneller laufen. Verglichen mit einem Dual-Xeon E5-2699v4 soll laut Nvidia ein DGX-1 mit V100 gar 100mal so schnell sein.
(Bild: Nvidia)
Versorgt werden die acht Tesla-V100-Karten im SXM2-Format wie zuvor auch von zwei kleineren Broadwell-Xeons (E5-2698v4). Die Speichergröße mit 16 GByte pro Karte ist gegenüber Tesla P100 gleich geblieben, ebenso der Hauptspeicher von 512 GByte (DDR4-2133).
Ein DGX-1-System ist mit 3200 Watt ausgewiesen. Damit rücken Exascale-Systeme mit nur rund 3,5 MWatt Energieaufnahme in den Bereich des Möglichen, wenn auch nur mit der von Nvidia-Chef Jensen (früher mal Jen-Hsun) Huang proklamierten "Umwidmung" von doppelter Genauigkeit (Fp64) auf das seiner Ansicht nach inzwischen wichtigere 16-bittige Datenformat Fp16.
Aber Jensen Huang weiß auch, dass die High-Performance-Community weiterhin auf fp64 angewiesen ist. Die nächste Architektur (man hört vom Namen "Ampere") wird verstärkt wieder auf diese Kundschaft eingehen – vielleicht gar mit 32- oder 64bittigen Tensor-Kernen? (as)
