

Data Science: Warenkorbanalyse in 30 Minuten
Seite 3: Vorbereiten der Daten
Ein wichtiger Schritt bei der Vorbereitung der Daten ist die Suche nach fehlenden Werten, also Einträgen mit den Werten "NULL" beziehungsweise "NONE" (undefinierte Daten). Im vorliegenden Datensatz sind über 700 Zeilen mit "NONE" markiert, das entspricht circa 3 Prozent des Gesamtbestands. Um das Ergebnis der Analyse dadurch nicht zu verfälschen, müssen die fehlenden Werte entweder befüllt oder gelöscht werden. Der Einfachheit halber löscht der Autor die betreffenden Zeilen im Datensatz:
df.drop(df[df['Item']=='NONE'].index, inplace=True)
print(df.info())
<class 'pandas.core.frame.DataFrame'>
Int64Index: 20507 entries, 0 to 21292
Data columns (total 7 columns):
Date 20507 non-null object
Time 20507 non-null object
Transaction 20507 non-null int64
Item 20507 non-null object
Jahr 20507 non-null object
Monat 20507 non-null object
Tag 20507 non-null object
dtypes: int64(1), object(6)
memory usage: 1.3+ MB
None
Im nächsten Schritt sollten Datums- und Zeitangaben in numerische Werte umgewandelt werden, um sowohl die Analyse als auch die Visualisierung der Daten zu erleichtern:
# Year
df['Jahr'] = df['Date'].apply(lambda x: x.split("-")[0])
# Month
df['Monat'] = df['Date'].apply(lambda x: x.split("-")[1])
# Day
df['Tag'] = df['Date'].apply(lambda x: x.split("-")[2])
print(df.info())
print(df.head())
<class 'pandas.core.frame.DataFrame'>
Int64Index: 20507 entries, 0 to 21292
Data columns (total 7 columns):
Date 20507 non-null object
Time 20507 non-null object
Transaction 20507 non-null int64
Item 20507 non-null object
Jahr 20507 non-null object
Monat 20507 non-null object
Tag 20507 non-null object
dtypes: int64(1), object(6)
memory usage: 1.3+ MB
None
Date Time Transaction Item Jahr Monat Tag
0 2016-10-30 09:58:11 1 Bread 2016 10 30
1 2016-10-30 10:05:34 2 Scandinavian 2016 10 30
2 2016-10-30 10:05:34 2 Scandinavian 2016 10 30
3 2016-10-30 10:07:57 3 Hot chocolate 2016 10 30
4 2016-10-30 10:07:57 3 Jam 2016 10 30
Visualisierung der Daten
Damit ist die Vorbereitung der Daten abgeschlossen. Der Datenbestand enthält nun aufbereitete Transaktionen für den Zeitraum vom 30. Oktober 2016 bis zum 9. April 2017. Von besonderem Interesse für die Analyse ist die Frage, welche Artikel Kunden am meisten kaufen:
# Die ersten 15 meistverkauften Produkte
most_sold = df['Item'].value_counts().head(15)
# print('Meistverkaufte Produkte: \n')
# print(most_sold)
plt.figure(figsize=(15,5))
# Meistverkaufte Produkte als Linie
plt.subplot(1,3,1)
most_sold.plot(kind='line')
plt.title('Meistverkaufte Produkte')
# Meistverkaufte Produkte als Balkendiagramm
plt.subplot(1,3,2)
most_sold.plot(kind='bar')
plt.title('Meistverkaufte Produkte')
# Meistverkaufte Produkte als Kreisdiagramm
plt.subplot(1,3,3)
most_sold.plot(kind='pie')
plt.title('Meistverkaufte Produkte')
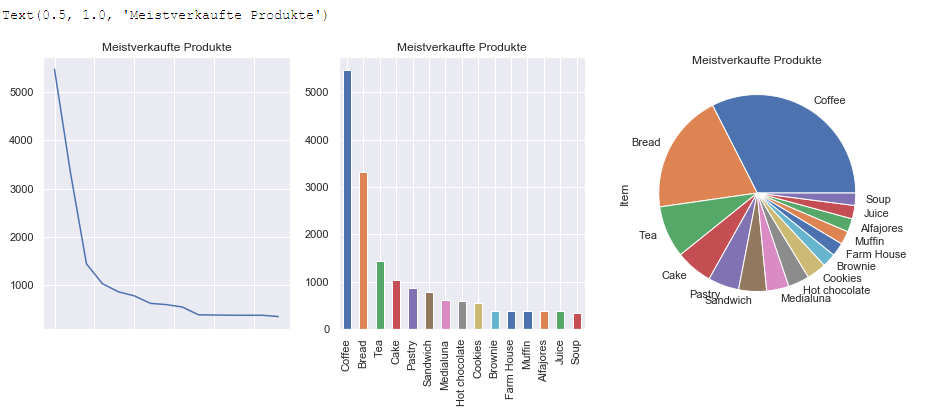
Kaffee ist überraschenderweise das meistverkaufte Produkt – erst danach folgt Brot. Auf den weiteren Plätzen finden sich Tee, Kuchen und Gebäck – wie man es für eine typische Bäckerei erwarten sollte.
Wie sich die Verkäufe der einzelnen Produkte im zeitlichen Verlauf darstellen, lässt sich am besten durch die visuelle Darstellung im monatlichen Vergleich erkennen:
df.groupby('Monat')['Transaction'].nunique().plot(kind='bar', title='Monatliche Verkäufe')
plt.show()

Die Monate Oktober und April stechen bei der Umsatzverteilung heraus. Woran könnte das liegen? Litt die Bäckerei in diesen Monaten unter einbrechenden Verkäufen? Um das zu prüfen, hilft ein Blick auf die Anzahl der Transaktionen im monatlichen Verlauf:
print(df.groupby('Monat')['Tag'].nunique())
Monat
01 30
02 28
03 31
04 9
10 2
11 30
12 29
Name: Tag, dtype: int64
Oktober und April entpuppen sich dabei tatsächlich als Ausreißermonate. Wie bereits in der Beschreibung des Datenbestandes vermerkt, wurden für den Datensatz im April nur 9 Tage und im Oktober sogar nur 2 Tage erfasst. Die zwei Monate sollten daher auf Grund mangelnder Relevanz bei der Analyse unberücksichtigt bleiben.
