

Data Science: Warenkorbanalyse in 30 Minuten
Seite 4: Warenkorbanalyse im Detail
Für die eigentliche Warenkorbanalyse kommt das Paket apriori aus der Python-Bibliothek mlxtend (machine learning extensions) zum Einsatz. Die von dem Machine-Learning-Wissenschaftler Sebastian Raschka gut mit Beispielen beschriebene Bibliothek lässt sich leicht installieren – unter Anaconda beispielsweise mit dem Befehl conda install mlxtend.
Bevor apriori eingesetzt werden kann, müssen die Transaktionen für die Berechnung passend formatiert sein. Für den Fall, dass die Einkäufe in der Bäckerei in einer Tabellenkalkulation bearbeitet werden sollten, müsste die Liste der Transaktionen als Pivot-Tabelle vorliegen, in der jede Zeile den zu einem bestimmten Zeitpunkt abgeschlossenen Transaktion und jede Spalte einem von Kunden gekauften (1 oder True) oder nicht gekauften (0 oder False) Produkt entspricht:
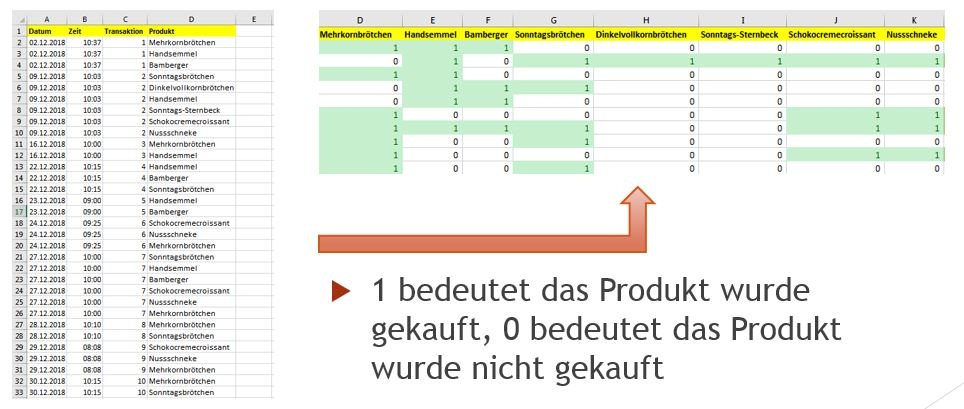
Im Fall der schottischen Bäckerei ist der Datensatz mit 95 eindeutig verkauften Produkten und über 20.000 Transaktionen für eine Analyse in einer Tabellenkalkulation zu umfassend. Bei diesem Umfang der Daten geht leicht der Überblick für zusammengehörige Käufe verloren – ganz unabhängig vom hohen manuellen Rechenaufwand, der anfällt, wenn für jedes mögliche Produktpaar Support, Konfidenz und Lift zu ermitteln sind. In Python lässt sich der Aufwand auf wenige Zeilen Code reduzieren:
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import association_rules, apriori
transaction_list = []
# FOR-Schleife zum Erstellen einer Liste der eindeutigen Transaktionen im Data-Set:
for i in df['Transaction'].unique():
tlist = list(set(df[df['Transaction']==i]['Item']))
if len(tlist)>0:
transaction_list.append(tlist)
print(len(transaction_list))
9465
te = TransactionEncoder()
te_ary = te.fit(transaction_list).transform(transaction_list)
df_ary = pd.DataFrame(te_ary, columns=te.columns_)
# print(df_ary)
Die Liste der eindeutigen Transaktionen lässt sich im TransactionEncoder für den späteren Einsatz des Apriori-Algorithmus formatieren. Der TransactionEncoder erstellt die Pivot-Matrix, in der jede Spalte einem Produkt entspricht, das gekauft (True) oder nicht gekauft (False) wurde. Die Python-Bibliothek mlxtend enthält außerdem einige Beispiele, an denen sich die im vorliegenden Artikel beschriebenen Manipulationen leichter nachvollziehen lassen.
Sobald der Datensatz formatiert ist, kommt der Apriori-Algorithmus mit den assoziativen Regeln zur Anwendung. Dabei wird für den Lift min_threshold = 1,0 festgelegt. Liegt der Lift-Wert unter 1,0, bedeutet das wie oben beschrieben, dass die beiden Produkte wahrscheinlich nicht zusammen gekauft werden.
Um die Wahrscheinlichkeiten erkennen zu können, ob ein Produkt gekauft wird, wenn sein "Vorgänger" gekauft wurde, sind die Ergebnisse nach der Konfidenz absteigend sortiert:
frequent_itemsets = apriori(df_ary, min_support=0.01, use_colnames=True)
rules = association_rules(frequent_itemsets, metric='lift', min_threshold=1.0)
# Nur die 'support', 'confidence', 'lift' Spalten anzeigen
result = rules[['antecedents', 'consequents', 'support', 'confidence', 'lift']]
result.sort_values('confidence', ascending=False)
# alles anzeigen
# rules.sort_values('confidence', ascending=False)
Die Warenkorbanalyse offenbart, dass Kunden mit 70-prozentiger Wahrscheinlichkeit (Konfidenz) auch einen Kaffee kaufen, wenn sie zuvor bereits ein Toast gewählt haben. Der Kauf eines Toasts macht den Kauf eines Kaffees also um 47 Prozent wahrscheinlicher (Lift 147 Prozent). Je höher also der Lift, desto stärker die Korrelation zwischen den beiden Produkten. Aus diesem Grund sind alle Beziehungen zwischen Produkten interessant, die ein hoher Lift verbindet – auch wenn die Konfidenz niedrig ist (Format: Vorgänger (antecedents) -> Folger (consequents)). Um solche Paare besser identifizieren zu können, lassen sich die Daten nach Lift absteigend sortieren.
