

Serverless Computing, Teil 1: Theorie und Praxis
Seite 2: Function as a Service
Genau diese Lücke haben auch einige Cloud-Anbieter erkannt, allen voran Amazon und Microsoft, und bieten in der Cloud Laufzeitumgebungen für die Ausführung einzelner Business-Methoden (FaaS) an (s. Abb. 3). Die Idee dahinter ist, dass Entwickler lediglich die Business-Methoden der Anwendung implementieren, sie in die Cloud laden und ab diesem Moment – so die Theorie – keinen weiteren Aufwand mehr mit ihnen haben.
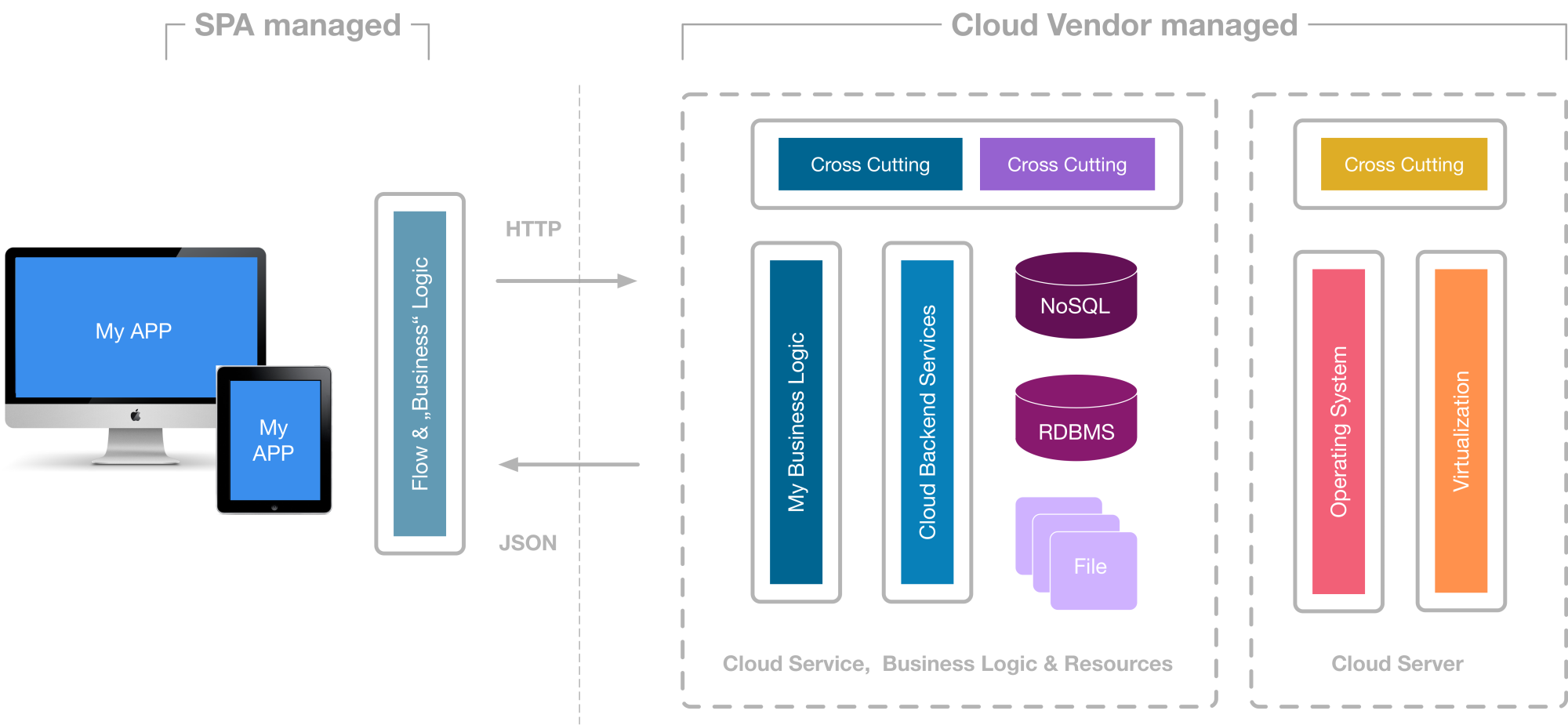
Aufgerufen werden die Funktionen entweder synchron via klassischem Request-/Response-Modell oder asynchron über Events. Um eine zu enge Kopplung der einzelnen Funktionen zu vermeiden und den Ressourcenbedarf zur Laufzeit zu optimieren, sollte – wenn möglich – auf die asynchrone Variante zurückgegriffen werden. Das gilt insbesondere bei verschachtelten Aufrufen von Funktionen, da sonst die aufrufenden Funktionen unnötig lange am Leben gehalten werden und entsprechende Kosten verursachen.
Was zunächst stark nach Platform as a Service klingt, unterscheidet sich in der Praxis stark von diesem Ansatz. Während PaaS eine langlebige Ablaufumgebung für die gesamte Laufzeit – vom Start bis zum gezielten Herunterfahren – eines Application Server oder eines (Micro-)Services zur Verfügung stellt, bietet Function as a Sercice eine kurzlebige Runtime, die lediglich für die Ausführungszeit eines einzelnen Funktionsaufrufs existiert. Laufzeiten von wenigen Sekunden oder gar Millisekunden sind das Maß der Dinge. Adrian Cockcroft, ehemals Cloud-Architekt bei Netflix und heute VP Cloud Architectures bei Amazon, schrieb dazu in einem seiner Tweets: "If your PaaS can efficiently start instances in 20ms that run half a second, then call it serverless."
Die FaaS-Runtime skaliert automatisch mit steigender Last. Wird eine Funktion häufiger aufgerufen, werden automatisch entsprechend viele FaaS-Runtimes gestartet und nach Abarbeitung der Funktion wieder beendet. Die Nutzung von FaaS eignet sich somit insbesondere für Szenarien, in denen das Lastverhalten einzelner Business-Methoden extrem schwanken kann. Natürlich existieren im Hintergrund auch weiterhin physikalische und virtuelle Server sowie minimalistische Server-Runtimes zur Ausführung der Funktionen. Der Begriff Serverless soll lediglich ausdrücken, dass sich Anwendungsentwickler um diese keinerlei Gedanken mehr machen müssen beziehungsweise keinerlei administrativen Aufwand mit ihnen haben.
Ein beispielhaftes "Hello FaaS"
Nicht nur AWS
Zur Umsetzung des skizzierten Anwendungsszenarios wird im Rahmen des Beispiels Amazons AWS Cloud verwendet. Die Realisierung der einzelnen Funktionen erfolgt mithilfe von AWS Lambda, Amazons FaaS-Implementierung. Das gezeigte Szenario ließe sich aber auch in ähnlicher Form problemlos mit anderen FaaS-Providern wie Google Functions, Microsoft Azure Functions oder IBM OpenWhisk realisieren.
Ein Beispiel sagt mehr als tausend Worte: Mithilfe der Anwendung "myJourney" können Anwender Reiseerlebnisse mit Freunden und Bekannten teilen. Zu diesem Zweck laden sie Bilder ihrer Reise inklusive Meta-Informationen in die Cloud. Die Bilder landen dort in einer zur Anwendung gehörenden Dateiablage, die Meta-Daten in einer entsprechenden Datenbank. Zusätzlich wird für die hochgeladenen Bilder ein Thumbnail erzeugt. Wie lässt sich ein solches Szenario mithilfe von Function as a Service als Serverless-Architektur realisieren?
Eine erste Funktion uploadImageToCloud lädt das Bild in die Cloud und legt es dort in einem zur Anwendung gehörenden Cloud-Dateisystem ab. Parallel dazu nimmt eine zweite Funktion insertImageMetaDataIntoCloudDB die zur Verfügung gestellten Meta-Daten und speichert sie in eine anwendungsspezifische Cloud-Datenbank.
/**
* Handles lambda function call
*
* @param imageUploadRequest Image information, e.g. URI of the image
* @param context Lambda function context
* @return String indicating if everything was fine.
* @throws IOException In case of file handling problems
*/
public ImageUploadResponse uploadImageToCloud(
ImageUploadRequest imageUploadRequest,
Context context) throws IOException {
// extract image info from request data
ImageInfo imageInfo =
ImageInfo.extractFromRequest(imageUploadRequest);
// create an in-memory-file
File inMemoryFile = Files.createTempFile(null, null).toFile();
FileUtils.copyURLToFile(new URL(imageInfo.getUri()), inMemoryFile);
// create object metadata for s3 storage
ObjectMetadata metadata = ... ;
// create PUT OBJECT S3 request with
// - predefined bucket (AWS_S3_BUCKET_NAME)
// - filename including path (AWS_S3_BUEKCT_KEY)
// - file to store
// - some additional meta data
// - public read access
PutObjectRequest putObjectRequest = new PutObjectRequest(
AWS_S3_BUCKET_NAME, AWS_S3_BUEKCT_KEY, inMemoryFile)
.withMetadata(metadata)
.withCannedAcl(CannedAccessControlList.PublicRead);
// call PUT OBJECT to AWS S3 bucket
// no credentials needed, lambda function has own AWS IAM role
PutObjectResult result = AWS_S3_CLIENT.putObject(putObjectRequest);
ImageUploadResponseBuilder builder
= new ImageUploadResponseBuilder();
return new ImageUploadResponseBuilder()
.withAwsS3BucketName(AWS_S3_BUCKET_NAME)
.withAwsS3BucketKey(AWS_S3_BUEKCT_KEY)
.withAwsS3ObjectSize(inMemoryFile.length())
.build();
}
Alternativ ließen sich die beiden Schritte in einer Funktion realisieren. Zur Optimierung der Laufzeit sowie zur Trennung der Zuständigkeiten wurde hier jedoch bewusst auf zwei Funktionen zurückgegriffen (s. Abb. 4, Step 1a und 1b).
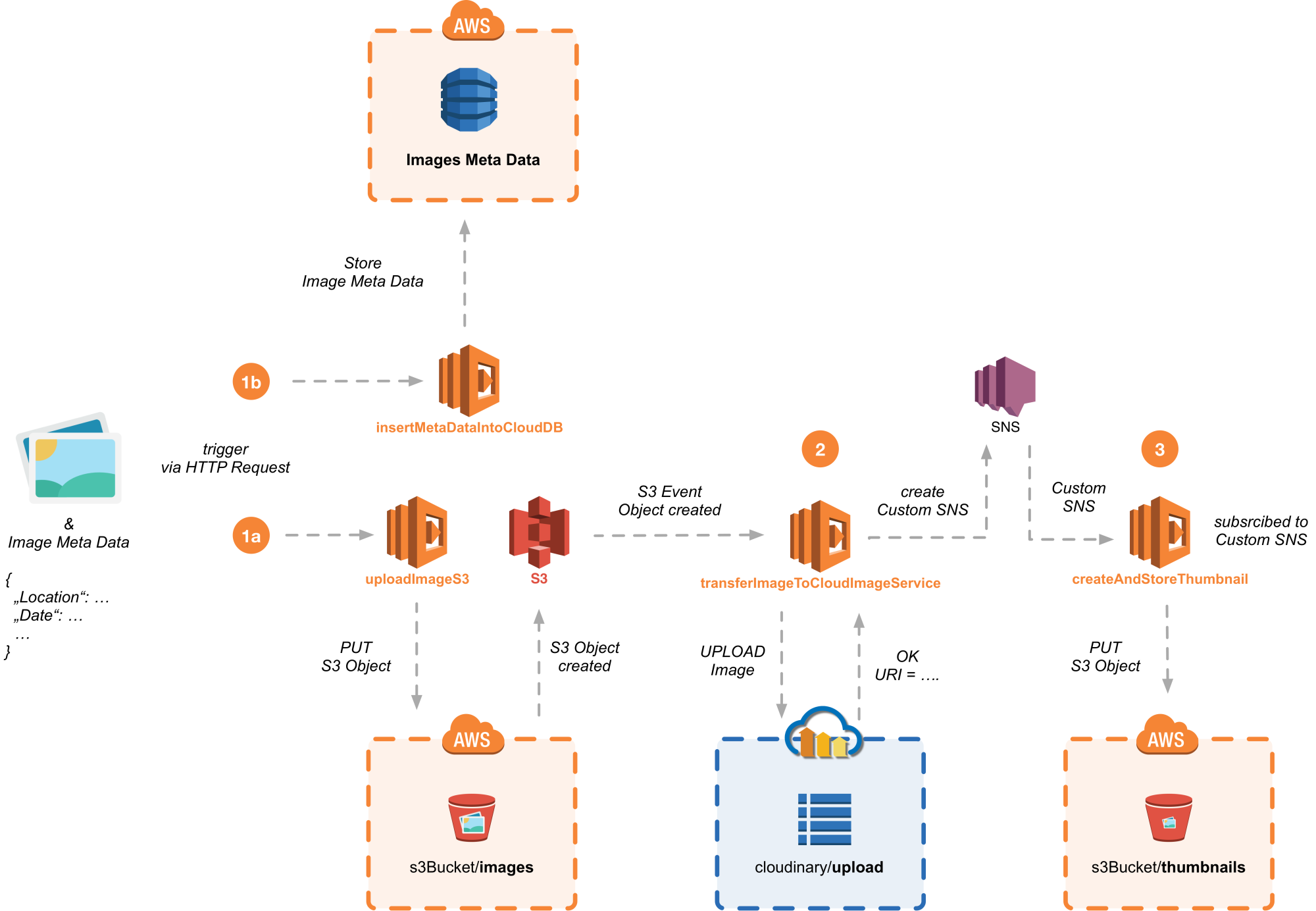
Durch das Ablegen des Bildes im Dateisystem wird ein Event "Object created" ausgelöst, das eine für das Event und das zugehörige Verzeichnis der Dateiablage als Listener registrierte Funktion transferImageToCloudImageService triggert. Sie überträgt zunächst das Bild aus dem Dateisystem in einen externen Cloud-basierten Bildmanipulations-Service (Cloudinary) zwecks späterer Bearbeitung. Mithilfe der vom Service zurückgelieferten URI erzeugt die Funktion anschließend ein selbstdefiniertes Event, das interessierten Funktionen signalisieren soll, dass ein Bild zur Generierung eines Thumbnails bereitliegt (Abb. 4, Step 2). Siehe dazu den zugehörigen Quellcode:
/**
* Transfers image from AWS S3 cloud to cloudinary image service
*
* @param s3Event event that indicates new image in AWS S3 bucket
* @param context Lambda function context
* @return upload location of cloudinary image service
*/
public String transferImageToCloudImageService (S3Event s3Event,
Context context) {
String uploadLocation = "UNKNOWN";
// extract info from S3 event, to get access to S3 object
// and upload object to Cloudinary image cloud
for (S3EventNotificationRecord s3EventNotificationRecord :
s3Event.getRecords()) {
// extract object (image) information from S3 event
S3Entity s3Entity = s3EventNotificationRecord.getS3();
String eventName = s3EventNotificationRecord.getEventName();
String bucketName = s3Entity.getBucket().getName();
String objectName = s3Entity.getObject().getKey();
// access image object from S3 bucket)
S3Object s3Object = AWS_S3_CLIENT.getObject(bucketName,
objectName);
// upload image to Cloudinary image cloud
try {
// create an in-memory-file
File inMemoryFile = Files.createTempFile(
null, null).toFile();
S3ObjectInputStream s3ObjectInputStream =
s3Object.getObjectContent();
FileUtils.copyInputStreamToFile(s3ObjectInputStream,
inMemoryFile);
Map uploadMetaData = CLOUDINARY_CLIENT.uploader()
.upload(inMemoryFile, keepFileInfoMetaData());
uploadLocation = uploadMetaData.get(URL).toString();
// publish aws sns message with image URI to topic
PublishResult publishResult = AWS_SNS_CLIENT
.publish(SNS_TOPIC, uploadLocation);
} catch (IOException e) {
// handle IO Exception
...
}
}
return uploadLocation;
}
Das Erzeugen des Thumbnails sowie dessen anschließende Ablage in einem separaten Ordner der Cloud-Dateiablage erfolgt letztlich durch die Funktion createAndStoreThumbnail (Abb. 4, Step 3):
/**
* Transfers image from AWS S3 cloud to cloudinary image service
*
* @param SNSEvent event that indicates the image location
* @param context Lambda function context
*/
public void createAndStoreThumbnail(SNSEvent event, Context context) {
String awsThumbnailLocation = "UNKNOWN";
for (SNSEvent.SNSRecord snsRecord : event.getRecords()) {
// extract image service uri from message
String snsId = snsRecord.getSNS().getMessageId();
String snsMessage = snsRecord.getSNS().getMessage();
// use cloudinary on-th-fly service to convert image
String generateThumbnailUri =
createGenerateThumbnailUri(snsMessage);
try {
File file = Files.createTempFile(null,null).toFile();
FileUtils.copyURLToFile(new URL(generateThumbnailUri),
file);
// set image S3 storage destination
String imageName = createStorageName(generateThumbnailUri);
// create PUT OBJECT S3 request with
// - predefined bucket (AWS_S3_BUCKET_NAME)
// - new filename (AWS_S3_BUCKET_KEY)
// - file to store
// - some additional meta data
// - public read access
PutObjectRequest putObjectRequest = new PutObjectRequest(
AWS_S3_BUCKET_NAME, AWS_S3_BUCKET_KEY, file)
.withCannedAcl(CannedAccessControlList.PublicRead);
// call PUT OBJECT to AWS S3 bucket
// no credentials needed, lambda function has own AWS IAM
PutObjectResult result = AWS_S3_CLIENT
.putObject(putObjectRequest);
} catch (IOException e) {
// handle excpetion
...
}
}
}
