

Serverless Computing, Teil 1: Theorie und Praxis
Nach IaaS, PaaS, BaaS und SaaS kristallisiert sich mit dem Akronym FaaS – Function as a Service – der nächste Evolutionsschritt der noch relativ jungen Cloud-Historie heraus. Laut Wunschvorstellung der Anbieter sollen Enterprise-Anwendungen zukünftig gänzlich ohne Server auskommen. Aber wie soll das funktionieren?
- Lars Röwekamp
Enterprise-Projekte bringen per Definition eine gewisse Komplexität mit sich. Das gilt sowohl für die umzusetzende Fachlichkeit als auch für die zur Laufzeit benötigte Infrastruktur. Die Entwicklung und Bereitstellung entsprechender Anwendungen wird daher nicht selten mit übergroßen Projektstrukturen, umständlichen Entwicklungsprozessen, schwergewichtigen Anwendungsservern, langsamen Test- und Deploymentzyklen sowie unnötig komplexer Provisionierung assoziiert. Da bilden auch Java-Projekte leider keine Ausnahme.
Modularisierungskonzepte wie Microservices inklusive minimalistischer Runtimes wie Spring Boot oder aber an Java EE angelehnte Umsetzungen lassen das Ganze zwar einfacher werden, aber eben noch nicht einfach genug. Optimal wäre es erst, wenn Entwickler sich tatsächlich nur noch um die Implementierung der fachlichen Bausteine kümmern müssten. Ein Traumszenario? Keineswegs. Zumindest nicht nach Ansicht der Cloud- und Serverless-Propagandisten. "Run code, not Server", so das Motto der Stunde.
Das kleine Cloud-Einmaleins
Eine Anwendung besteht aus Fachlichkeit beziehungsweise Use-Cases. Ziel sollte es somit sein, dass sich die Entwickler der Anwendung maßgeblich auf deren Umsetzung konzentrieren können. Die Realität sieht leider anders aus. Ein Großteil der Zeit innerhalb eines Projekts wird nicht für die Anwendungsentwicklung selbst, sondern für das korrekte Aufsetzen und Betreiben der zur Laufzeit benötigten Infrastruktur und Backend-Services ver(sch)wendet.
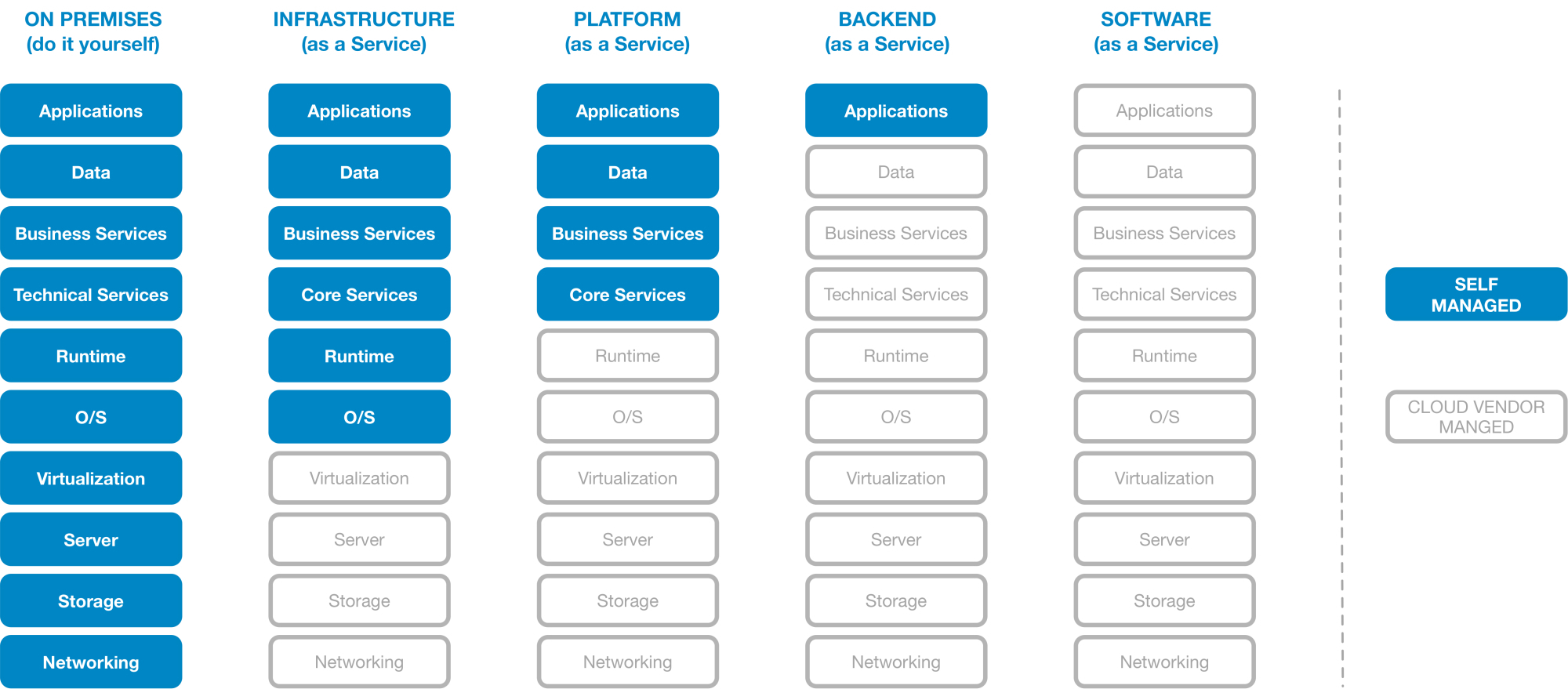
Genau an der Stelle setzen die unterschiedlichen Cloud-Angebote an und liefern den Entwicklerteams Out-of-the-box-Dienste unterschiedlichster Granularität. Angefangen bei virtuellen Rechnern (Infrastructure as a Service, IaaS) über Datenbanken, Dateisysteme oder Anwendungsserver (Platform as a Service, PaaS), bis hin zu komplexen Softwareanwendungen – als modulare Services (Backend as a Service, BaaS) oder in Gänze (Software as a Service, SaaS) – kann sich ein Cloud-affines Entwicklerteam einer breiten Palette an Möglichkeiten bedienen (s. Abb. 1).
Einmal abgesehen von der Tatsache, dass sich mithilfe der Cloud-Dienste in allen Phasen des Softwarelebenszyklus ein großer Teil des Entwicklungs- und operationalen Aufwands einsparen lässt, bringt deren Einsatz noch einen weiteren, wichtigen Vorteil mit sich: automatische Skalierung. Dank der Verlagerung von Infrastruktur in die Cloud kann eine Anwendung "on the fly" skalieren. Werden zum Beispiel zusätzliche Rechnerinstanzen benötigt, lassen sie sich in Minuten statt Tagen oder Wochen zur Verfügung stellen.
Gleiches gilt für neue Datenbanken, zusätzlichen Plattenplatz oder weitere Instanzen von Anwendungsservern. Selbst komplexe Dienste wie Kundenverwaltung, Social-Media-Integration, Push Notifications, Chat und Messaging oder Nutzeranalysen passen sich dank Cloud-basierter Backend-Services automatisch der anfallenden Last an. Abgerechnet wird dabei in der Regel aufwandsbasiert via Pay-per-use-Modell. Hohe Initialkosten und somit ein nur schwer kalkulierbares Projektrisiko gehören der Vergangenheit an.
Es ist sicherlich für jedermann vorstellbar, dass der Einsatz Cloud-basierter, virtualisierter Server eine deutlich vereinfachte Provisionierung mit sich bringt. Gleiches gilt für die Verwendung vorinstallierter und vorkonfigurierter Datenbank- und Storage-Systeme oder Anwendungsserver in der Cloud. Und selbst die Einbindung von Rundum-sorglos-Softwaremodulen zur Abdeckung von Standardaufgaben wie der Verwaltung von Kunden- oder Produktdaten eines Web-Shops scheint gangbar (s. Abb. 2).

Aber wo genau befindet sich die Grenze? Oder anders gefragt: Wie weit lässt sich die Verlagerung der eigenen Anwendung in Richtung Cloud treiben? Ist es realistisch, wie es der Begriff Serverless suggeriert, seine Anwendung vollständig in die Cloud zu verlagern, sodass kein Server mehr zu betreiben, zu administrieren und zu konfigurieren ist? Die Verwendung von Containern wie Docker schafft zwar einheitliche Umgebungen zur Entwicklungs- und Laufzeit und minimiert so den administrativen Aufwand, eliminiert wird er durch ihren Einsatz aber nicht.
Wer braucht schon einen Server?
Eine Enterprise-Anwendung setzt sich aus anwendungsspezifischer Logik zusammen. In der Java-Welt läuft diese in der Regel als mehrschichtiger Monolith auf einem Application Server oder alternativ verteilt in Form mehrerer eigenständiger (Micro-)Services inklusive eingebetteter Server-Runtime-Komponente. Die Frage, die sich auf dem Weg zu Serverless stellt, ist somit, wie sich die Logik weg vom selbst verwalteten Server bewegen lässt. Ein genauerer Blick auf die Logik einer Anwendung offenbart die Unterscheidung in drei Aufgabenbereiche:
- Ablaufsteuerung und lokale Logik
- standardisierte Geschäftslogik
- individuelle Geschäftslogik
Die Ablaufsteuerung befindet sich normalerweise in UI-Controllern. Diese nehmen Eingaben der UI entgegen, triggern im Hintergrund die Abarbeitung von Geschäftslogik an (2. und 3.), um am Ende die als nächste darzustellende UI-Ansicht zu bestimmen. In einer reinen Cloud-Architektur ließe sich diese Logik in den Client verlagern. Er könnte zum Beispiel eine in JavaScript geschriebene Single Page Application sein. Gleiches gilt für die lokale Logik, also die Geschäftslogik, die nicht auf geteilte Ressourcen wie Datenbanken, Dateisystem et cetera zugreift. Auch sie ließe sich vollständig auf den Client verlagern. Vorausgesetzt natürlich, dass keine sicherheitsrelevanten Aspekte dagegen sprechen. Zum Beispiel sollten Security-Credentials niemals auf dem Client gespeichert werden.
Die Verlagerung der standardisierten Geschäftslogik wurde oben im Rahmen der Vorstellung von BaaS beschrieben. Denn genau das ist es, was ein Backend as a Service ausmacht. Es bietet standardisierte Services und somit unter anderem standardisierte Geschäftslogik in der Cloud. Bleibt die individuelle Logik, also die serverseitige Logik, die die BaaS-Angebote der Cloud-Anbieter nicht abdecken können. Sie ist es, die bisher eine eigene Server-Runtime benötigte – egal ob in Form eines Application Server oder eingebettet als Runtime-Komponente eines (Micro-)Services.
