

Verwundbarkeitsanalyse anhand von CPE-Dictionary und CVE-Feeds
Seite 2: Beschreibung und Einsatz des CVE-Standards
Damit IT-Sicherheitsexperten, Wissenschaftler, CERTs (Computer Emergency Response Team) oder die Antivirusindustrie Verwundbarkeiten in Software- oder Hardwareprodukten eindeutig identifizieren können, ist eine standardisierte Methode notwendig. Der CVE-Standard entstand für diesen Zweck. Jeder bekannten Softwareschwachstelle wird eine eindeutige CVE-ID zugewiesen.
Darüber hinaus bekommt ein CVE für eine Verwundbarkeit nicht nur eine ID, sondern es werden Angriffsmöglichkeiten wie ein DoS-Angriff (Denial of Service) kurz beschrieben, die Kritikalität dieser Schwachstelle definiert und, am wichtigsten, die betroffenen Software- und Hardwareprodukte in das CPE-Format übergeben. Dadurch lässt sich ein bestimmtes IT-Produkt mit einer Verwundbarkeit einfach verlinken.
Ähnlich wie beim CPE-Standard bietet die NVD eine öffentlich zugängliche XML- oder JSON-Datenbank (CVE-Feeds), in der die meisten bekannten Schwachstellen im CVE-Format eingetragen werden. Abbildung 2 zeigt ein Beispiel eines Eintrags des XML-CVE-Feeds von 2018. In diesem Fall handelt es sich um einen Buffer Overflow in verschiedenen Versionen des Acrobat Reader. Die Informationen des CVE-Beispiels werden verkürzt dargestellt.

Zielsetzung und Anwendungsumfang einer Verwundbarkeitsanalyse
Ein Verwundbarkeitsmanagementsystem hat das Ziel, verwundbare Software innerhalb einer IT-Infrastruktur rechtzeitig zu erkennen, zu melden und zu beseitigen, um einen möglichen Angriff zu vermeiden. Den Prozess, in dem ein Softwareprodukt als verwundbar erkannt wird, bezeichnet man als Verwundbarkeitsanalyse.
Die vorherigen Abschnitte haben ein Verfahren zur eindeutigen Identifizierung von Software (CPE) und eine Methode zur eindeutigen Identifizierung bekannter Schwachstellen in Software (CVE) vorgestellt. Außerdem kam zur Sprache, dass öffentlich zugängliche Datenbanken für die CPE- und CVE-Einträge zur Verfügung stehen.
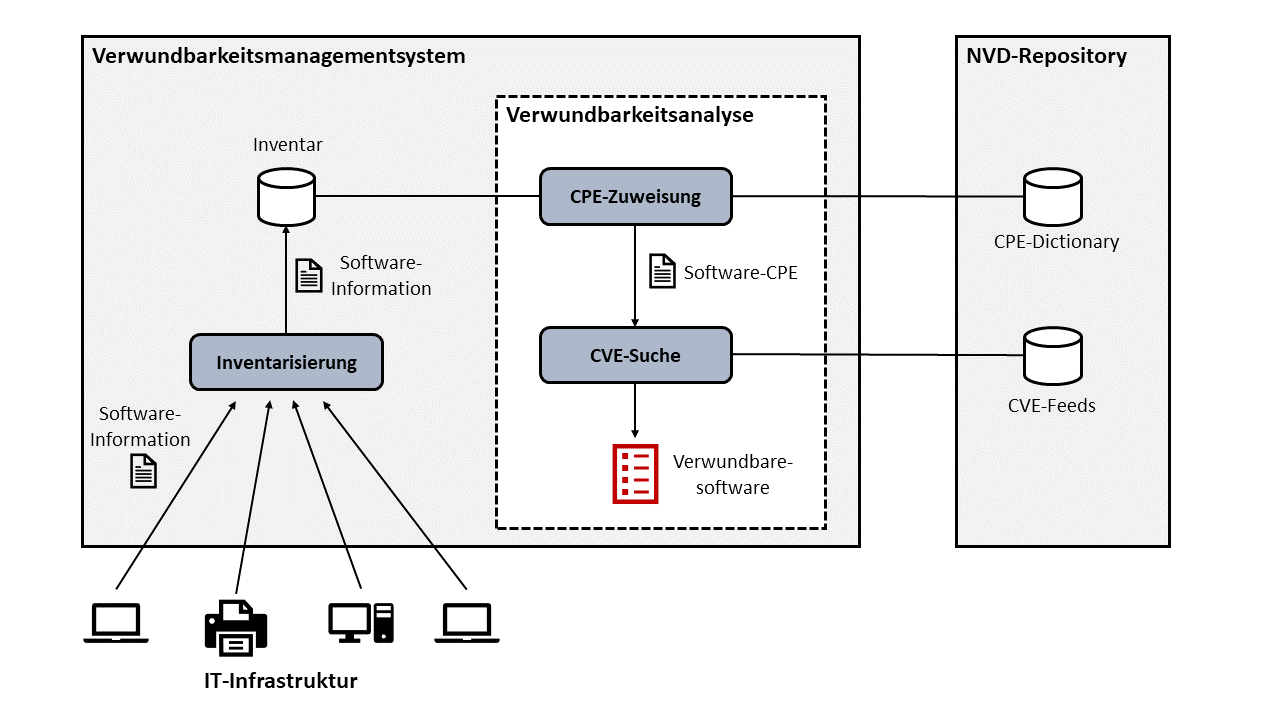
Die Kompatibilität der CVE-Feeds mit dem CPE-Standard ermöglicht die Implementierung kostengünstiger und effektiver Verwundbarkeitsanalyseangebote. Abbildung 3 zeigt die Realisierung einer VA anhand der CPE- und CVE-Datenbanken. Die VA-Komponente befindet sich in einem Verwundbarkeitsmanagementsystem und bekommt als Eingabe die Softwareprodukte, die in einer IT-Infrastruktur installiert sind, aus einer Inventardatenbank. Während der Analyse werden grundsätzlich drei Schritte durchgeführt:
- Jedes Softwareprodukt bekommt eine CPE.
- Anhand der zugewiesenen CPE wird nach CVEs für das Softwareprodukt gesucht.
- Falls CVEs für die Softwareprodukte gefunden wurden, wird eine Liste zu den verwundbaren Produkten erzeugt. Danach werden bei Bedarf andere Komponenten wie ein Meldungssystem des VMS in diese Liste mit aufgenommen. Den letzten Teil zeigt die Abbildung 3 nicht, da der Fokus auf der Verwundbarkeitsanalyse (mit der CPE und CVE) liegt.
Evaluierung von CPE-Dictionary und CVE-Feeds
Bevor eine Verwundbarkeitsanalyse – mithilfe der offiziellen CPE- und CVE-Datenbanken – implementiert wird, ist es zu empfehlen, eine Evaluierung der Datenbanken durchzuführen, um einige Aspekte wie die Synchronisierung zwischen CPE-Dictionary und CVE-Feeds zu berücksichtigen. Über die Evaluierung lässt sich vermeiden, dass die Verwundbarkeitsanalyse inkorrekte Ergebnisse liefert. Es könnte zum Beispiel ein Softwareprodukt als nicht verwundbar klassifiziert werden, was tatsächlich gar nicht stimmt. Das führt somit zu einer Falsch-negativ-Rate (eng. false negative rate). Diese falsche Klassifizierung könnte einen Hackerangriff verursachen, der die Sicherheitslücke in der Software ausnutzt.
Bei einer Evaluierung von CPE-Dictionary und CVE-Feeds (durchgeführt am 13. Juni 2018) haben die Autoren ein Tool in Python geschrieben, das in Gitlab zur Verfügung steht. Es ermöglicht Entwicklern, die Evaluierung ebenfalls jederzeit durchführen zu können.
